
Pipeline resolvers in AppSync
How to write functions and combine them to interact with multiple data sources for a single field


GraphQL resolvers define how AppSync (or any other GraphQL server) produces the response for a field. It needs a data source that allows interfacing with other services, such as a DynamoDB table, or a web server accessible via HTTP. Then the request and the response templates provide a way to convert the AppSync query structure to conform to the data source's format.
But what if you need multiple data sources in a single resolver?
For example, a mutation for adding a user might want to call Cognito and also update a DynamoDB table with the details. You could use a Lambda function to handle both operations but then you'll lose the benefits of the AppSync-managed resolver interface. The AppSync-native solution is pipeline resolvers.



Pipeline resolvers
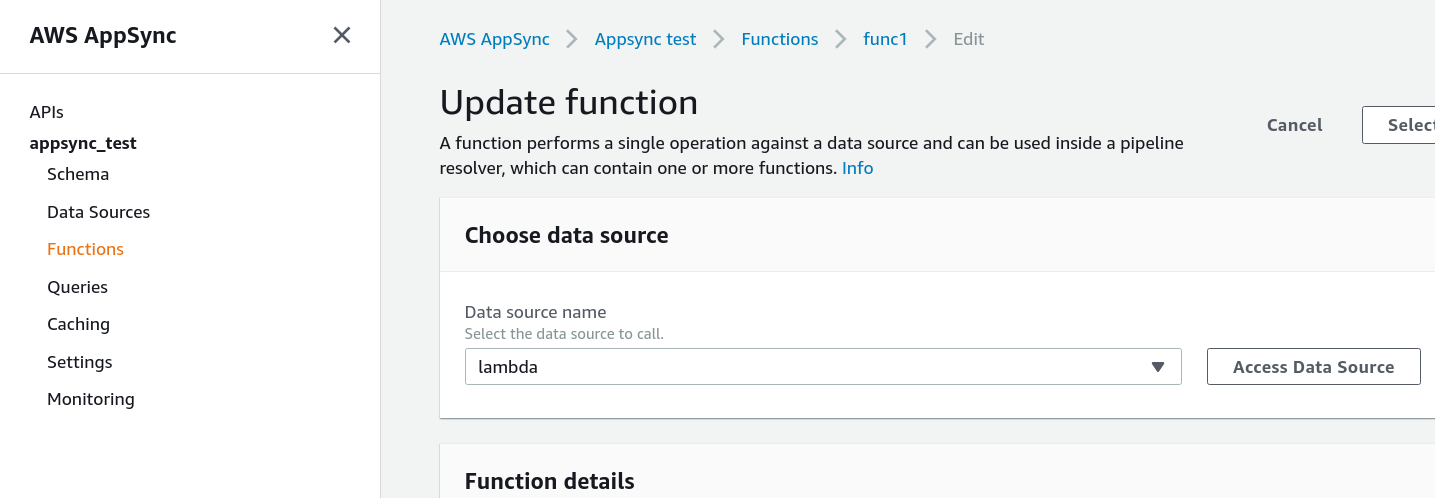
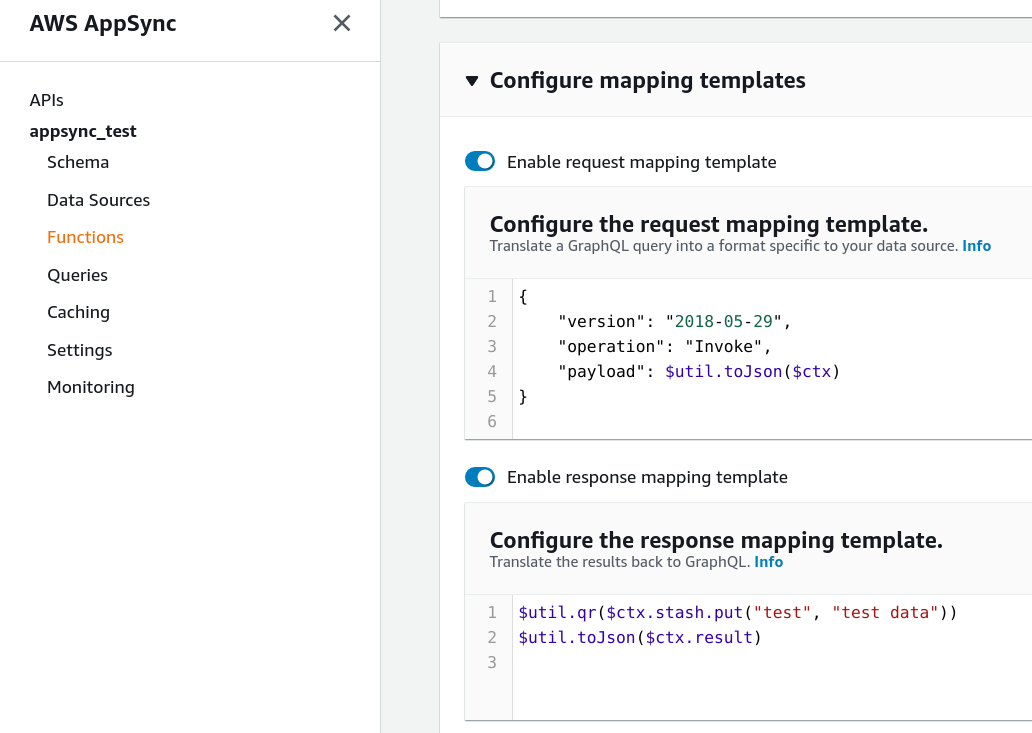
Pipeline resolvers are made of functions that are structurally the same as normal resolvers, but they can only be part of pipeline resolvers. A function needs a data source and it can have a request mapping template and a response mapping template. These templates use the same structure as the resolvers' templates.
Choosing the data source for the function:
Configuring the templates for a function:
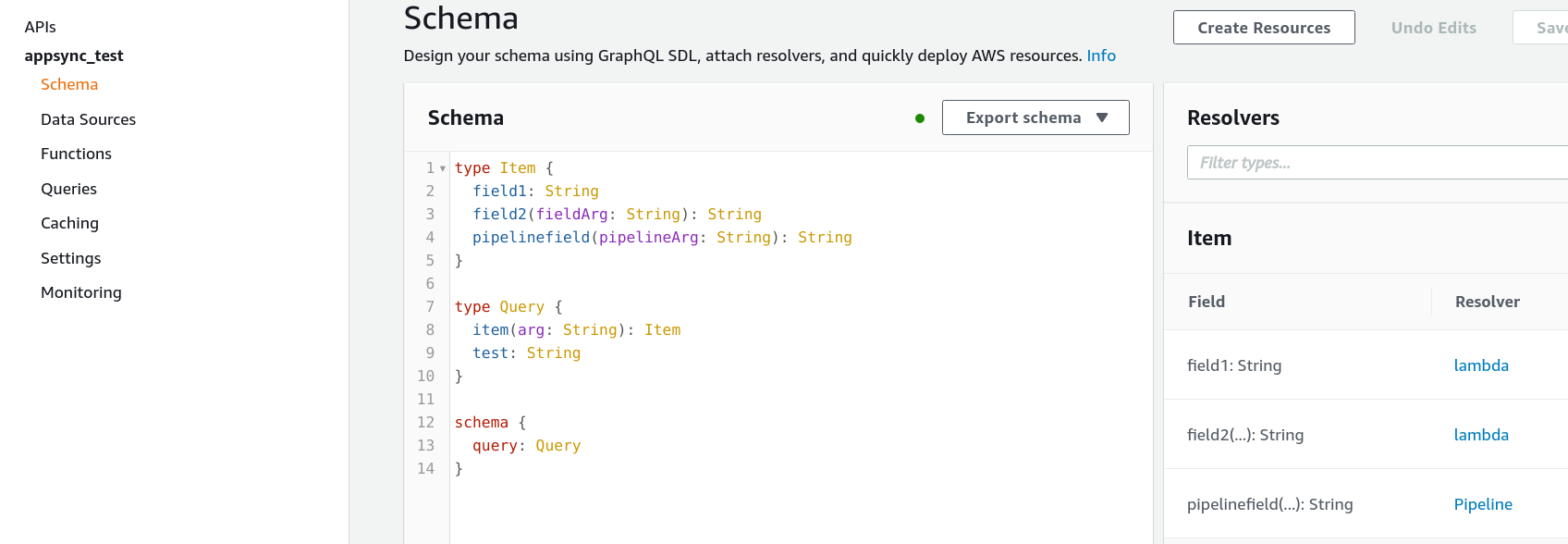
To use the functions in a pipeline resolver, add a resolver to a field on the "Schema" page:
The pipeline itself is similar to a unit resolver that it has a before mapping template and an after mapping template. But unlike other resolvers, pipelines have no single data source, instead they have a series of functions.
A pipeline resolver config, showing the before mapping template and its functions:
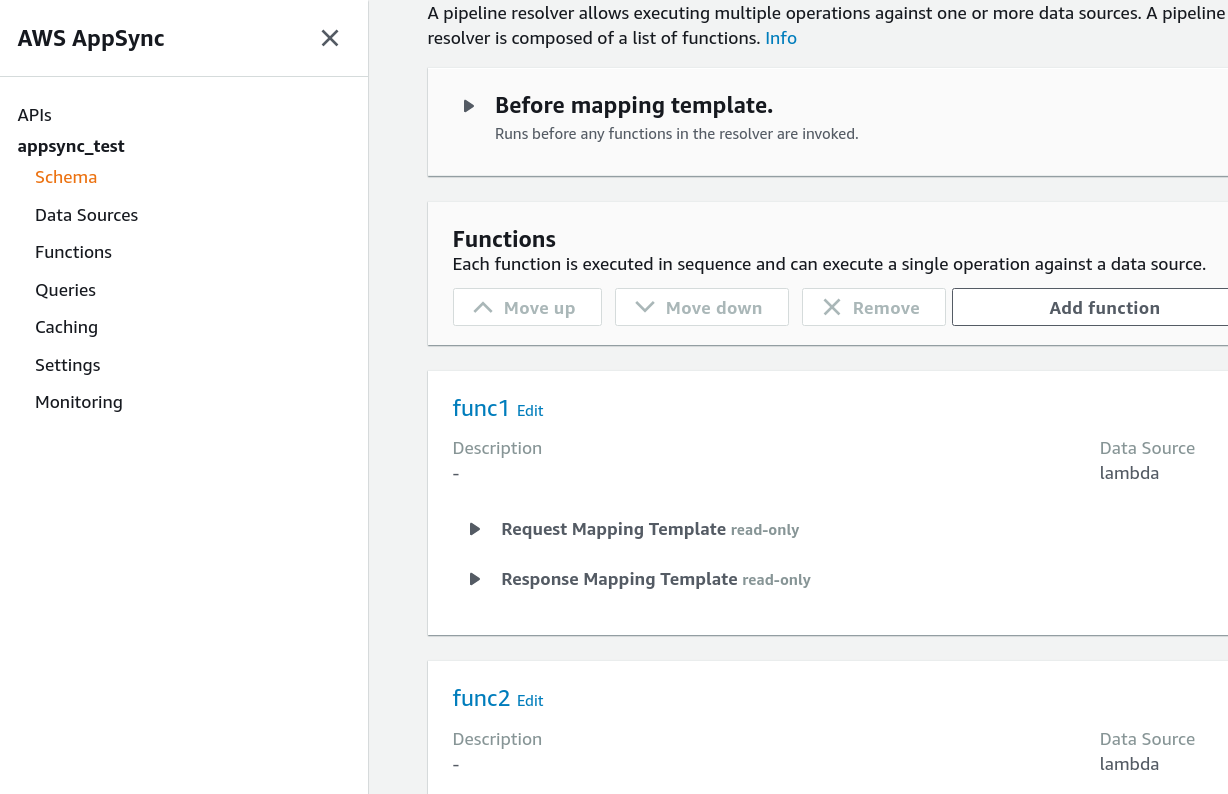
In practice, the before and the after mapping templates are rarely used. They are useful when the first or the last function is reused between pipelines and you can't adapt them to individual fields. In that case, the before template is useful to convert the context to what the first function expects, and the after template to convert the result of the last function to the result AppSync needs.
How functions work
Functions work the same as unit resolvers, and they are called serially by AppSync. For example, the first function can call a Lambda function that creates a Cognito user, and the second function can use a DynamoDB data source to insert the value to a table. You can add up to 10 functions in a single pipeline, which should be enough for most use-cases. The good thing is that you can always fall back to a Lambda function instead and get around all the limitations of pipelines.
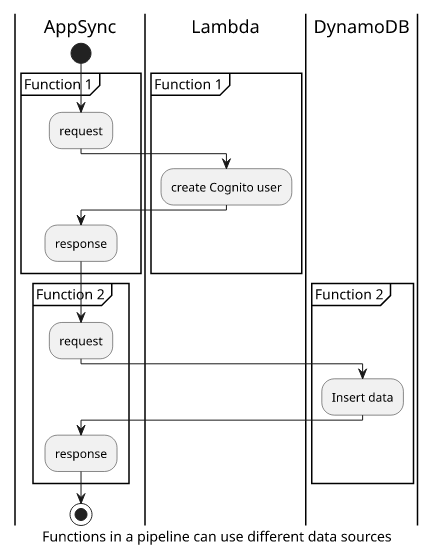
Error handling
Unlike unit resolvers, a pipeline can behave in 2 ways regarding errors:
- interrupt the execution and return immediately:
$util.error() - register the error in the context but continue execution:
$util.appendError()
At first sight, the second way does not make much sense. Isn't the best practice is to fail-fast, so throw an error as soon as possible?
It is definitely the case for queries, but I've found non-terminating errors useful in mutations for cleaning up dirty data in case there is a failure.
Let's say we want to do 2 operations: create a Cognito user, then update a DynamoDB table. Both operations can fail for a number of reasons, so you can't assume that if Cognito returns a success response DynamoDB will do the same.
It makes sense to add a third function to the pipeline that undoes the Cognito operation if there was an error with DynamoDB. But for that to work, the DynamoDB
function needs to use the $util.appendError() non-terminating helper instead of the $util.error().
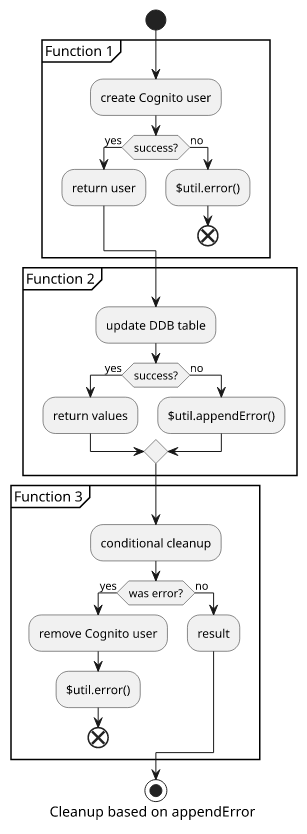
Note that this structure does not completely eliminate the chance of ending up in a dirty state, as the cleanup function can also fail. But in practice, that's the best you can do. And since nothing guarantees that a Lambda function is not terminated mid-processing, using a Lambda resolver won't solve this problem either.
Early return
You might also want to conditionally skip the function. In the previous example, you don't want to run the cleanup code if there were no errors in the previous
step. For that, you can use the #return() directive in the request mapping template and that will skip running the data source altogether.
The common structure is to check for the skip condition:
#if(condition)
#return(result)
#end
... proceed normallySharing data
In the context, all functions share some data. Since the request itself is the same, the arguments, the identity, and the source are the same
for all functions in a pipeline.
But there are several important additional fields in the context related to pipelines.
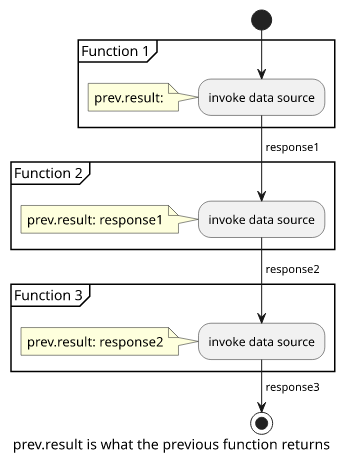
prev.result
This holds the result of the previous function in the pipeline. Most functions build on data from the previous one, so this is the most important way to share data in the pipeline.
For example, the first function that creates a Cognito user might return the unique id of that user. Then the second resolver can read that and add to the database.
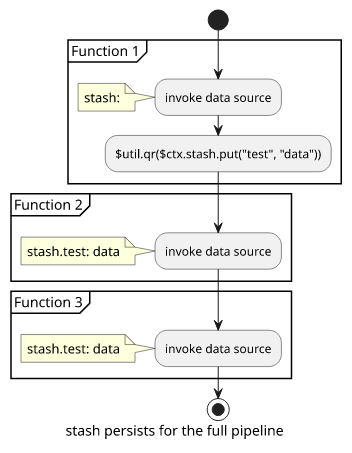
stash
When you need to access a value from a function that is not the previous one in the pipeline, you can use the stash. This is a storage of arbitrary values that are shared by all the functions in the pipeline execution.
You can add items to the stash in request and response mapping templates as well, and you can read the contents in either of them too. It's a common practice to read data that will be needed later in the pipeline and store it in the stash.
Store text in the stash:
$util.qr($ctx.stash.put("test", "data"))Access it later:
$ctx.stash.testFor example, creating a user might need some data from the database, such as what extra attributes to attach to the Cognito user. The first function might read the data, store it in the stash, then the next functions can use that.
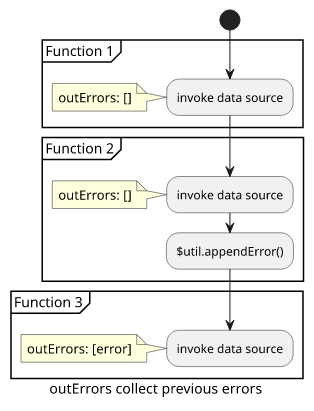
outErrors
When a function uses the $util.appendError() to add a non-terminating error, it is written to the context.outErrors. This is an array that collects
previous errors, so a function can check the individual items.
Conclusion
Pipeline resolvers combine unit resolvers and allow you to define a multi-stage process for a query or a mutation. They allow using AppSync-managed VTL to interact with multiple different data sources.

