
How to use DynamoDB with AppSync
How to store, retrieve, and query items in a DynamoDB table with an AppSync resolver


AppSync natively supports reading and writing data from/to DynamoDB tables. This is done through the DynamoDB data source that defines the data structure for the resolvers for each operation. It supports all operations DynamoDB supports, which means you can implement anything database-related natively in resolvers.
In this article we're going to look into a simple data model that stores data in DynamoDB tables. We'll see how to do various operations on the items and how to integrate that with AppSync.

Example data model
In this article, we're going to implement a simple GraphQL API with two tables: users and groups. Both of them have an id and a name and users belong to groups.
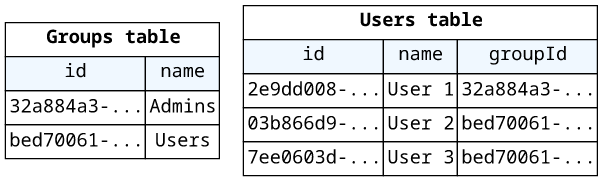
We'll implement a query to get back a group based on its ID, and mutations to add groups and users.
The schema:
type User {
id: ID!
name: String!
}
type PaginatedUsers {
users: [User!]!
nextToken: String
}
type Group {
id: ID!
name: String!
users(count: Int, nextToken: String): PaginatedUsers!
}
type Query {
groupById(id: String!): Group
}
type Mutation {
addGroup(name: String!): Group!
addUser(name: String!, groupId: ID!): ID!
}
schema {
query: Query
mutation: Mutation
}Data source
First, we need the tables:
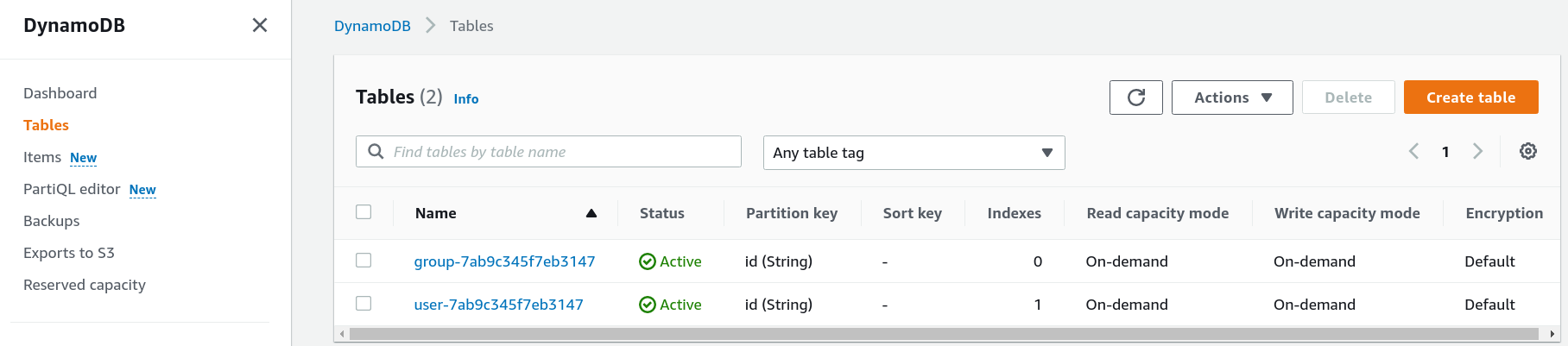
Then we'll define a data source for each of them:
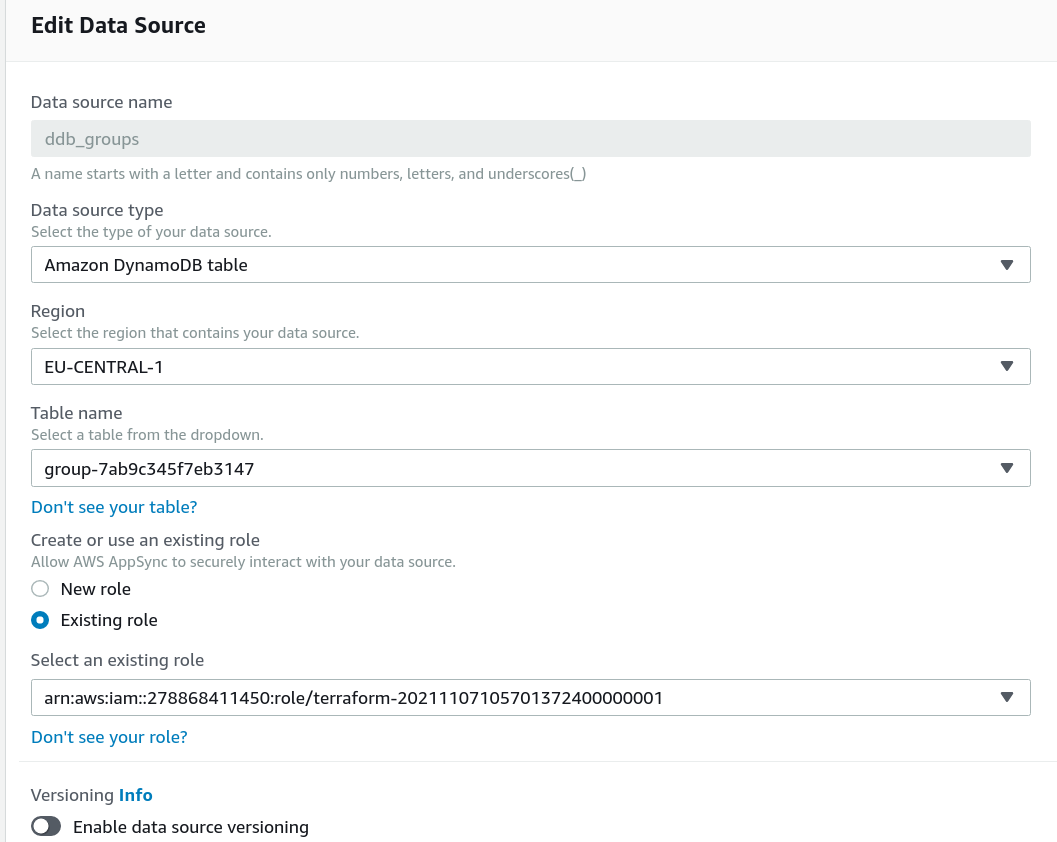
The first part is straightforward, as it defines the data source as an "Amazon DynamoDB table", and locates it. AppSync uses an IAM Role to gain the necessary permissions to access these tables, so we need to create the role and add the permissions:
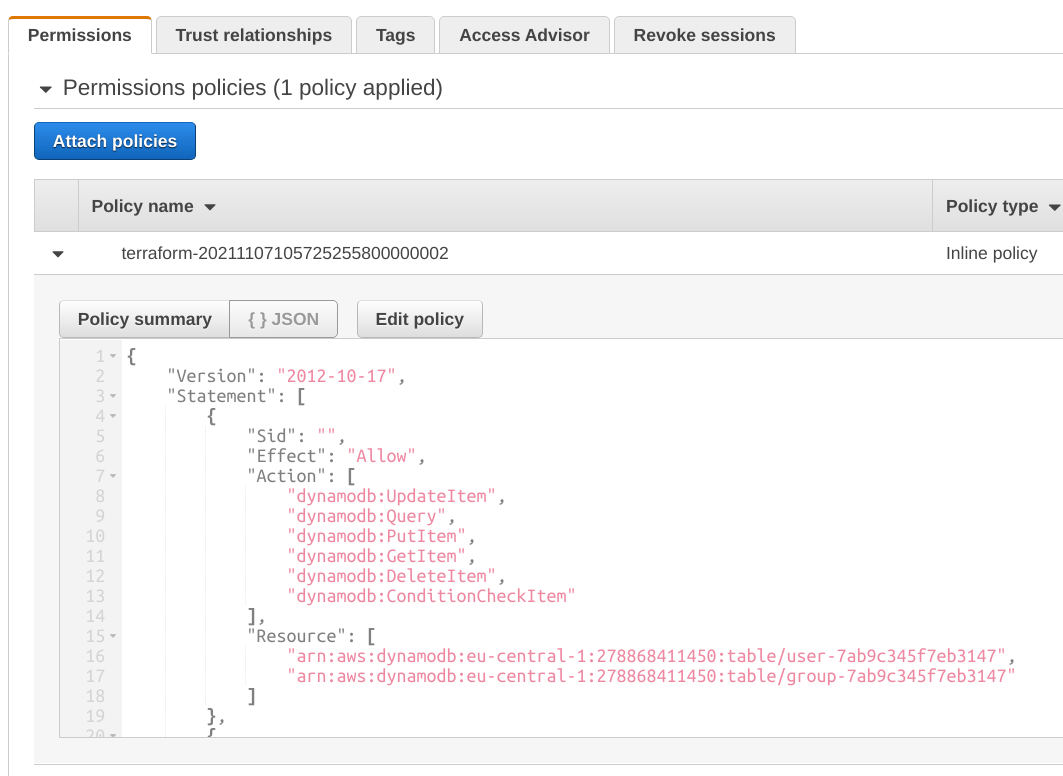
This is all we need to start using these DynamoDB tables in AppSync resolvers.
Operations
AppSync supports the full feature set of DynamoDB. You can issue all basic operations (CRUD items, queries, scans, transactions, batching), use conditions, expressions, and specify the types, just like with any other DynamoDB client.
Let's see the most commonly used operations and how to implement them for our data model!
Getting items
Let's start with the entry point to the object graph, the groupById query:
type Query {
groupById(id: String!): Group
}This gets an id argument and returns a Group. A query and a response:
query MyQuery {
groupById(id: "group1") {
id
name
}
}{
"data": {
"groupById": {
"id": "group1",
"name": "Group 1"
}
}
}To implement this, we need a resolver that sends a GetItem to the groups table:
{
"version" : "2018-05-29",
"operation" : "GetItem",
"key" : {
"id" : {"S": $util.toJson($ctx.args.id)}
},
"consistentRead" : true
}This is the structure that most GetItems follow. The $ctx.args.id is the query argument, then the $util.toJson converts it to a String in a
safe way. The key specifies what element to get, and the consistentRead defines a strongly consistent read.
The response mapping:
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$util.toJson($ctx.result)Here, AppSync first needs to check if there was an error during the GetItem call. By default, resolvers don't terminate if there was an error in the
underlying data source (as of the 2018-05-29 version) but leave that to the response mapping template. So the template needs to check the $ctx.error
and throw an error using $util.error.

Queries
Queries in DynamoDB allows returning a list of items when a table or index has a composite key. The query needs to define the hash key in full, then it can define filters and sorting for the range key.
In our data model, a group can contain a list of users. This is a field in the Group type and that resolves to a list of users:
type Group {
users(count: Int, nextToken: String): PaginatedUsers!
}Since the users table has the user id as its key, we need an index to be efficiently query users in a group:
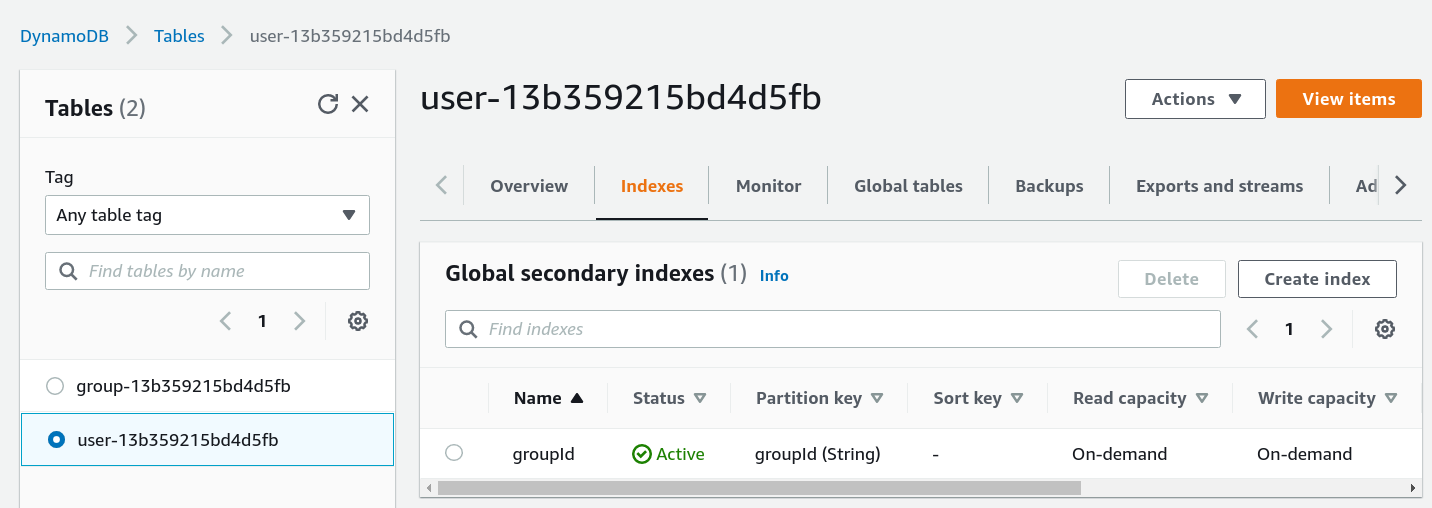
AppSync can then query this index to get back the list of all users for a given group. This operation scales, as it does not matter how many groups the database has, only how many users are in a given group (as opposed to a Scan operation, that would get slower with more groups).
Pagination
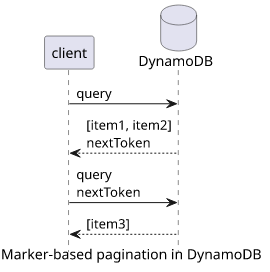
Pagination is a central concept in DynamoDB as every operation that returns a list is not guaranteed to return all elements in one go. The exact number of elements is determined by the size of each item DynamoDB needs to read, which means you can't make assumptions of the returned number. For small items, DynamoDB returns maybe hundreds, but if at a later point you start adding new attributes this number can drop. Moreover, filtering is run after the items are fetched by the database, so it can happen that a query returns 0 results for a page. Because of this, always assume that a Query might return partial results.
DynamoDB implements marker-based pagination. This means when it returns a partial response it returns a marker (called nextToken). When you want the next
page, run the same query and pass the nextToken from the previous page.
AppSync has a limitation that using the DynamoDB data source you can only send a predefined number of requests to the database. One resolver equals one query, and you can't define a loop that fetches all pages for a query. On the other hand, AppSync has hard limits for the response size and time. Because of this, it is not suited to returns a list of items that can go to large numbers.
It's a best practice to expose DynamoDB pagination to the clients. It even has a named design pattern in GraphQL: the connection pattern.
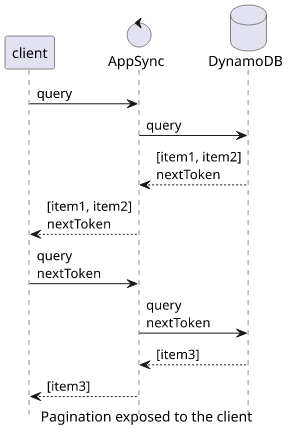
To implement this in AppSync, the field for the list should include a nextToken both in the arguments and the response:
type PaginatedUsers {
users: [User!]!
nextToken: String
}
type Group {
users(count: Int, nextToken: String): PaginatedUsers!
}With this, the client can send a request, get back a page, then send the next request with the token, and so on, until there is no token in the response. Concatenating the results gives the full list.
Also, it's a best practice to add a limit argument too. But keep in mind the usual restrictions of DynamoDB queries:
- The client needs to adjust the limit according to how many items it already got
- Limit = 1 does not mean there is no pagination
Resolver
After all this background, let's see how to implement the AppSync resolver for the Group.users field!
Since it is a field of the Group type, the $ctx.source is the Group object, so $ctx.source.id is the group id. Also, since the field gets a
count and the nextToken arguments, these are accessible under $ctx.args.
To send the query to the index:
{
"version" : "2018-05-29",
"operation" : "Query",
"index": "groupId",
"query": {
"expression" : "#groupId = :groupId",
"expressionNames": {
"#groupId": "groupId"
},
"expressionValues" : {
":groupId" : {"S": $util.toJson($ctx.source.id)}
}
}
#if($ctx.args.count)
,"limit": $util.toJson($ctx.args.count)
#end
#if($ctx.args.nextToken)
,"nextToken": $util.toJson($ctx.args.nextToken)
#end
}It defines quite a few things:
operationisQueryso it sends a Query to a DynamoDB tableindexisgroupIdso it queries an index and not a table- The
expressionsspecifies the partition key of the items ":groupId" : {"S": $util.toJson($ctx.source.id)}defines the group's id- If there is a
$ctx.args.countthen specify thelimit - If there is a
$ctx.args.nextTokenthen specify thenextToken
The response gets what DynamoDB returns and transforms it to the structure of the PaginatedUsers:
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
{
"users": $utils.toJson($ctx.result.items)
#if($ctx.result.nextToken)
,"nextToken": $util.toJson($ctx.result.nextToken)
#end
}As usual, it check for errors first. Then it converts the $ctx.result.items to User objects, then attaches a nextToken if DynamoDB returned one.
Testing
Finally, let's see how the above query works!
To get back users, we need a group, obtained with groupById, then fetch the users field:
query MyQuery {
groupById(id: "group1") {
id
name
users {
users {
id
name
}
nextToken
}
}
}Result:
{
"data": {
"groupById": {
"id": "group1",
"name": "Group 1",
"users": {
"users": [
{
"id": "user1",
"name": "User 1"
},
{
"id": "user2",
"name": "User 2"
}
],
"nextToken": null
}
}
}
}To simulate pagination, let's add a count argument to the field:
query MyQuery {
groupById(id: "group1") {
id
name
users(count: 1) {
users {
id
name
}
nextToken
}
}
}The result contains only one user, and a token:
{
"data": {
"groupById": {
"id": "group1",
"name": "Group 1",
"users": {
"users": [
{
"id": "user1",
"name": "User 1"
}
],
"nextToken": "eyJ2ZX..."
}
}
}
}To get the next page, add the nextToken to the field:
query MyQuery {
groupById(id: "group1") {
id
name
users(count: 1, nextToken: "eyJ2ZX...") {
users {
id
name
}
nextToken
}
}
}{
"data": {
"groupById": {
"id": "group1",
"name": "Group 1",
"users": {
"users": [
{
"id": "user2",
"name": "User 2"
}
],
"nextToken": "yLCJ0...."
}
}
}
}Notice that there is another nextToken in the response, which means there might be more results.
query MyQuery {
groupById(id: "group1") {
id
name
users(count: 1, nextToken: "yLCJ0....") {
users {
id
name
}
nextToken
}
}
}{
"data": {
"groupById": {
"id": "group1",
"name": "Group 1",
"users": {
"users": [],
"nextToken": null
}
}
}
}No more users, and no nextToken either. That means we got all the results.
Storing items
To add groups we need to implement a mutation that calls the putItem operation:
type Mutation {
addGroup(name: String!): Group!
}
schema {
query: Query
mutation: Mutation
}This gets a name argument that will be the name of the group, and it returns a Group object. Since groups need an id and the mutation does not
get one, AppSync needs to generate it. This is done using the $util.autoId() function:
{
"version" : "2018-05-29",
"operation" : "PutItem",
"key" : {
"id" : {"S": "$util.autoId()"}
},
"attributeValues": {
"name": {"S": $util.toJson($ctx.args.name)}
}
}This defines the id and the name attributes for the new item. The former is generated by AppSync, while the latter comes from the mutation
arguments.
The response needs to check for errors, then return the item:
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$util.toJson($ctx.result)Why does it return a Group object?
The DynamoDB PutItem returns the object that is inserted into the database, converted to Javascript types (which means instead of {"name": {"S": "group1"}},
it will be {"name": "group1"}) and that will be the value of $ctx.result. Because of this, there is no need to refetch the item.
Retrying
One important thing is missing here: retrying failed operations. DynamoDB might fail to insert the item for all sorts of reasons, and AppSync won't try again after a failure but return an error to the client.
This is called fail-fast behavior and it's the preferred way to handle errors. But because of this, the clients need to implement a retry strategy that automatically sends the same request if there is a failure.

Testing
To test it, send a mutation that adds a new group:
mutation MyMutation {
addGroup(name: "group3") {
id
name
}
}The response, if everything went fine:
{
"data": {
"addGroup": {
"id": "254603e9-8a17-4a3a-8eea-4d4b4d2a4f69",
"name": "group3"
}
}
}Transactions
Transactions are the primary way to implement cross-item (and cross-table) consistency guarantees in DynamoDB. A transaction is an all-or-nothing set of operations.

We'll need a transaction to insert a new user as DynamoDB needs to check that the group exists. The mutation needs a name for the user and the group's id:
type Mutation {
addUser(name: String!, groupId: ID!): ID!
}Transactions are made of transaction items. Each item is an operation that adds (PutItem), deletes (DeleteItem), updates (UpdateItem), or
checks a condition (ConditionCheck) for an item. In our case, we need to add a user (PutItem) and also check the existence of the group (ConditionCheck).
{
"version": "2018-05-29",
"operation": "TransactWriteItems",
"transactItems": [
{
"table": "user-13b359215bd4d5fb",
"operation": "PutItem",
"key": {
"id" : {"S": "$util.autoId()"}
},
"attributeValues": {
"name": {"S": $util.toJson($ctx.args.name)},
"groupId": {"S": $util.toJson($ctx.args.groupId)}
}
},
{
"table": "group-13b359215bd4d5fb",
"operation": "ConditionCheck",
"key":{
"id": {"S": $util.toJson($ctx.args.groupId)}
},
"condition":{
"expression": "attribute_exists(#pk)",
"expressionNames": {
"#pk": "id"
}
}
}
]
}The $util.autoId() generates a new UUID for the user, and the $ctx.args contains the name and the groupId specified in the arguments.
Then the attribute_exists(#pk) checks the existence of the group item.
The global DynamoDB limit of at most 25 items in a single transaction still applies. While it's rare to hit that limit, it's good to be aware of it.
The response mapping template checks if there was an error, and extracts the id from the response:
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$util.toJson($ctx.result.keys[0].id)Data source
The DynamoDB data source defines the table, but transactions can have operations targeting different tables. That means each transactItem has a
table attribute that specifies what table the operation is sent to. Because of this, the table for the data source does not matter.
What matters though is the IAM role of the data source. AppSync uses that role to send the transaction, so it needs the necessary permissions for all of the involved tables.
Return type
You might have noticed that the addUser returns the ID of the new user and not the full User object. This is because DynamoDB returns only the ID and not
the full object, so AppSync can not resolve the fields that need other properties of the source object (such as the name).
It is possible to return the full object but that needs a second resolver that reads the item from DynamoDB and returns that. It's possible with a pipeline resolver.

Testing
To add a new user:
mutation MyMutation {
addUser(groupId: "group1", name: "user5")
}It returns the ID of the user:
{
"data": {
"addUser": "3174153b-cbcc-468c-ad22-67267c8d8fbd"
}
}If the group does not exist it returns an error:
mutation MyMutation {
addUser(groupId: "none", name: "user5")
}{
"data": null,
"errors": [
{
"path": [
"addUser"
],
"data": null,
"errorType": "DynamoDB:TransactionCanceledException",
"errorInfo": null,
"locations": [
{
"line": 2,
"column": 3,
"sourceName": null
}
],
"message": "Transaction cancelled, please refer cancellation reasons for specific reasons [None, ConditionalCheckFailed] (Service: DynamoDb, Status Code: 400, Request ID: D82EOU9B0DM440THDU9U8L0H7FVV4KQNSO5AEMVJF66Q9ASUAAJG, Extended Request ID: null)"
}
]
}Conclusion
The DynamoDB data source allows an AppSync API to directly interface with tables in the AWS account. You can define resolvers for queries, fields, and mutations that create/retrieve/update/delete items, even across multiple tables.

