
How to implement an exponential backoff retry strategy in Javascript
Automatically retry an async operation in an efficient way


 An example is available on GistRun
An example is available on GistRun
Backoff algorithm
A Javascript application made a fetch call to a remote server and it failed. How should it retry the request so that it eventually succeeds while also
minimizing the calls made?
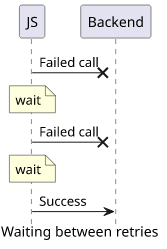
A backoff algorithm makes sure that when a target system can not serve a request it is not flooded with subsequent retries. It achieves this by introducing a waiting period between the retries to give the target a chance to recover.
The need for a backoff builds on the observation that a service is unavailable when it is overloaded and sending more requests only exacerbates the problem. When all callers temporarily cease adding more load to the already overloaded service usually smooths the traffic spikes with only a slight delay.
The backoff algorithm used determines how much to wait between the retries. The best configuration is actively researched in the case of network congestion, such as when a mobile network is saturated. It's fascinating to see that different implementations yield drastically different effective bandwidth.
Retrying a failed call to a remote server is a much easier problem and doing it right does not require years of research. In this article, you'll learn how to implement a backoff solution in Javascript that is good enough for all practical purposes.

Exponential backoff
But let's first revisit the problem of choosing the backoff strategy, i.e. how much to wait between the retries! Sending requests too soon puts more load on the potentially struggling server, while waiting too long introduces too much lag.
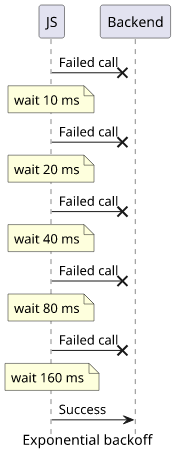
The exponential backoff became the standard algorithm to use. It waits exponentially longer for subsequent retries, which makes the first few tries happen with only a slight delay while it reaches longer periods quickly.
It has two parameters: the delay of the first period and the growth factor. For example, when the first retry waits 10ms and the subsequent ones double the previous values, the waiting times are: 10, 20, 40, 80, 160, 320, 640, 1280, ...
Notice that the sum of the first 3 attempts is less than 100 ms, which is barely noticeable. But it reaches >1 second in just 8 tries.
Javascript implementation
There are two pitfalls when implementing a backoff algorithm.
First, make sure to wait only before retries and not the first request. Waiting first and sending a request then introduces a delay even for successful requests.
And second, make sure to put a limit to the number of retries so that the code eventually gives up and throws an error. Even if the call eventually succeeds, something upstream timeouts in the meantime, and the user likely gets an error. Returning an error in a timely manner and letting the user retry the operation is a good UX practice.
There are two types of operation in terms of retrying: rejection-based and progress-based. Let's discuss each of them!
Rejection-based retrying
This type of call either succeeds or fails and it is usually implemented as a Promise resolving or rejecting. A canonical example is a "Save" button that may fail and in that case, retrying means sending the request again.
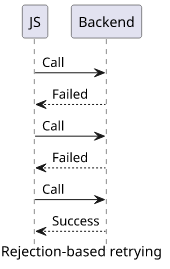
For illustration, this operation emulates a network call that fails 90% of the time:
const wait = (ms) => new Promise((res) => setTimeout(res, ms));
const maybeFail = (successProbability, result, error) => new Promise((res, rej) => Math.random() < successProbability ? res(result) : rej());
const maybeFailingOperation = async () => {
await wait(10);
return maybeFail(0.1, "result", "error");
}Calling this function without a retry mechanism is bad UX. The user would need to click the button repeatedly until it succeeds.
A general-purpose solution that can take any async function and retry it for a few times before giving up:
const callWithRetry = async (fn, depth = 0) => {
try {
return await fn();
}catch(e) {
if (depth > 7) {
throw e;
}
await wait(2 ** depth * 10);
return callWithRetry(fn, depth + 1);
}
}And to use it with the operation defined above:
const result = await callWithRetry(maybeFailingOperation);In the retry implementation, the depth argument indicates the number of calls made to the service so far. It determines how much to wait (await wait(2 ** depth * 10)) and when to give up (if (depth > 7) {...}). When the function calls itself it increments this value.
Interestingly, this is a scenario where using return await makes a difference. Usually, it does not matter if an async function returns a Promise or its
resolved value. But not in this case, as the try..catch needs to wait for the fn() call to finish to handle exceptions thrown from it.
Note that this implementation retries for any error, even if it is a non-retriable one, such as sending invalid data.
Progress-based retrying
Another class of retriable operations is when each call might make some progress towards completion but might not reach it.
A great example of this is how DynamoDB's batchWriteItem call works. You define the items to store, and the call tries to save all of them. It then
returns a list in the response indicating which elements failed. The retry operation only needs to include these missed items and not the whole request.

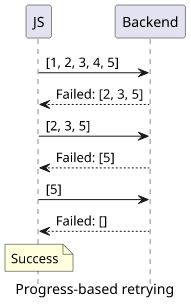
As an illustration, this function emulates a progressing call to a remote server. It returns a progress field that goes from 0 to 1, and a result
when the call is fully finished. It also needs to know the current progress, which is a parameter for the call:
const progressingOperation = async (startProgress = 0) => {
await wait(10);
const progress = Math.round(Math.min(startProgress + Math.random() / 3, 1) * 10) / 10;
return {
progress,
result: progress === 1 ? "result" : undefined,
};
}In this case, not reaching completion still resolves the Promise, which mimics the DynamoDB API. But a different API might reject it. Fortunately, it's easy to
convert a rejected Promise to a resolved one: .catch().
In the DynamoDB batchWriteItem example, the progress return field is the list of the unprocessed items, and the startProgress parameter is the
items to save.
To retry the above call until it reaches completion:
const callWithProgress = async (fn, status, depth = 0) => {
const result = await fn(status);
// check completion
if (result.progress === 1) {
// finished
return result.result;
}else {
// unfinished
if (depth > 7) {
throw result;
}
await wait(2 ** depth * 10);
return callWithProgress(fn, result.progress, depth + 1);
}
}To use this retrying call, use:
const result = await callWithProgress(progressingOperation);Note that this implementation is not general-purpose as it builds on how the call returns progress.
Conclusion
Implementing a retrying behavior with a backoff algorithm is better for UX (users see fewer errors) and also attempts to handle system overload by not flooding the called service. Using an exponential algorithm is a simple yet effective way to determine how much to wait between the calls while it also makes a sensible tradeoff between latency and the number of calls made.

