
How to change a blog's permalinks and not lose all organic traffic
Changing URLs is risky. Here's how we managed it without losing a single visitor


During 2019 we decided to change the URL of all the posts in this blog. While this seems like a simple change in the configs, it has the potential to invalidate all our backlinks and thus zero out the organic traffic. Because of this, we had to plan everything very carefully.
But while the migration itself is a point-in-time event, we also had to make sure we don't end up with a system that promotes accidental breaking of backlinks during day-to-day use. This can happen, for example, when the URL of an article is based on a setting that is seemingly unrelated to it. We don't want broken backlinks when fixing a typo in the article title.
In this article, I'll detail how we managed to do the migration and what was the thought process behind each decision. This is a Jekyll-based blog, but the underlying ideas are transferrable to other blog engines.
Here are the results:

The migration happened on Dec 15 (highlighted), and you can see that reduction in organic traffic only happened from the beginning of Christmas until the end of the holiday season. After that, it went back up, like nothing happened.
No traffic was lost because of the migration.

The original structure
We used the most common permalink structure that comes with Jekyll, which is /:categories/:year/:month/:day/:title/. This is the easiest to
use for anybody new to blogging as it provides the least friction. And it's called pretty in the presets
and even if you omit the setting it will default to a structure similar to this.
And this structure has the most important aspect of permalinks: the URLs are permanent. Jekyll uses the filenames for the publication date too, so unless you go ahead
and rename files in the _posts folder you can be sure that your links won't change, ever.
Notice the :title part of the config. It has nothing to do with the actual title of the post but is the part of the filename that comes
after the publication date. This structure gives URLs such as https://advancedweb.hu/2019/07/17/upload_signed_urls_differences/.
But the filename is usually considered an implementation-specific thing and we used that to distinguish posts from each other. When I start writing an article I have a vague idea of what it will be about and I give the file a similarly vague name. And that ended up in the URL.
SEO problems
Why is that a problem? SEO, of course.
The common advice is to use - instead of _ in the URL as the former is considered a word break by search engines while the latter is not.
Another best practice is to put keywords to the URL of the page as it is shown in the search results.
Similarly, the publication date should not be included in the URL. We have a lot of evergreen articles, but more importantly, the date is already shown in the search snippet:

Showing the date and the filename goes against the recommendations so we decided to change the structure. But while it seems like an easy thing, it turned out to be quite complicated.
Why it's hard to change permalinks
Changing all URLs to new ones invalidates all our backlinks. And while SEO is more of an art than science, everybody agrees that backlinks are the #1 booster of organic traffic. Breaking all our backlinks would zero our organic traffic, which is where the majority of our visitors are coming from.
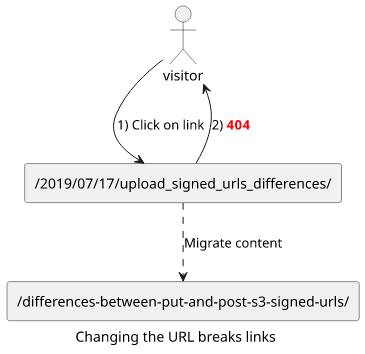
The solution is to redirect the old URLs to the new ones which preserve the backlinks. People usually say that a redirect robs some of the backlink's strength but we decided we'll win more from the SEO-friendly URLs than what we're losing on the redirects.
How to configure redirects
Redirect can happen in multiple ways.
First, the web server can send back an HTTP 301 along with the new URL in the Location header. This is the preferred method as it's almost transparent and should be supported in every user agent and crawler.
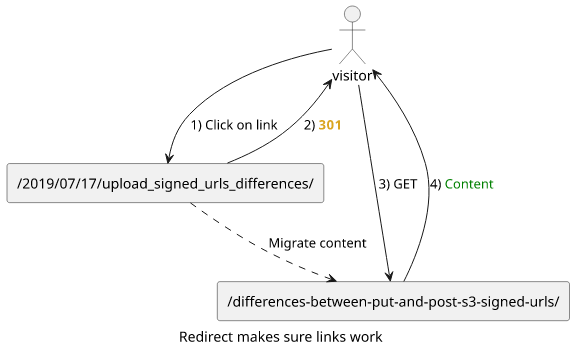
Another solution is to place an HTML file that instructs the browser to change the location upon parsing the page. For example, the jekyll-redirect-from plugin, which we ended up using, generates the following file:
<!DOCTYPE html>
<html lang="en-US">
<meta charset="utf-8">
<title>Redirecting…</title>
<link rel="canonical" href="https://advancedweb.hu/differences-between-put-and-post-s3-signed-urls/">
<script>location="https://advancedweb.hu/differences-between-put-and-post-s3-signed-urls/"</script>
<meta http-equiv="refresh" content="0; url=https://advancedweb.hu/differences-between-put-and-post-s3-signed-urls/">
<meta name="robots" content="noindex">
<h1>Redirecting…</h1>
<a href="https://advancedweb.hu/differences-between-put-and-post-s3-signed-urls/">Click here if you are not redirected.</a>
</html>This HTML uses multiple ways to achieve its purpose. First, it has a <meta http-equiv="refresh"> which is the primary way to send the browser to a
different URL. If it does not work for some reason, there is a <script>location="..."</script> that uses Javascript to do the same. And finally,
there is a link the user can click on. This should take care of any browser or crawler that hits this page.
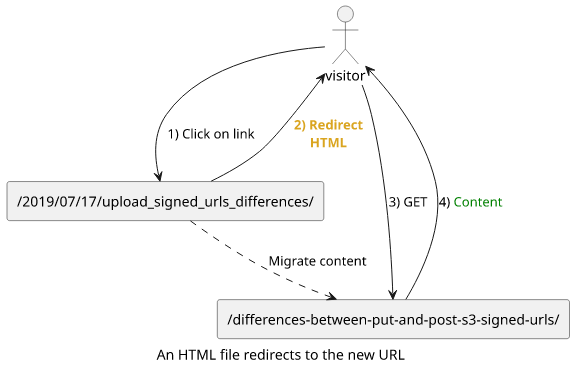
But it's not just about redirection but also to let the crawlers know that this page is on another URL. The <link rel="canonical"> specifies
the target URL to be the real source of the content while the <meta name="robots" content="noindex"> instructs the crawler not to index this page.
HTTP 301 or HTML?
Sending the HTTP 301 status code is the preferred way of redirecting, as that is expected to be recognized by all browsers and tools. Just look at all those edge cases handled in the HTML file that is so elegantly taken care of by a single number.
But there are cases where sending a status code can not be done, for example when the page is hosted on Github Pages, which is where our blog currently is. In this case, while we can put arbitrary HTML files, we can not define status codes. The file-based approach is compatible with every kind of hosting solution.
From the perspective of the user, there is no difference between the two approaches. The browser handles them the same and both require a GET request to the original URL and then another one to the target location.
As for SEO, there is also no difference. Crawlers support the <meta http-equiv="refresh"> just like the 301 status code.
The Jekyll-redirect-from plugin
The barebones solution is to generate a bunch of redirect HTML files that instruct the browser to move to the target location. This can be done point-in-time with some scripting, but the main downside is that the post and the redirect files are separated. A need for another redirect later means another file and knowing which of them redirects to a specific post requires inspecting all of them.
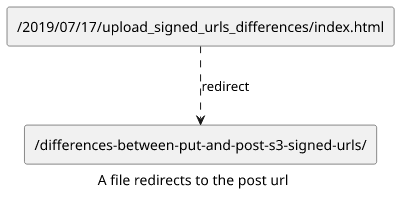
But there is an excellent plugin for Jekyll that solves this problem quite elegantly: jekyll-redirect-from. It lets defining the redirect URLs in the front matter of the post:
---
layout: post
title: "Differences between PUT and POST S3 signed URLs"
...
redirect_from:
- /2019/07/17/upload_signed_urls_differences/
---The plugin generates a redirect HTML file for every path in the redirect_from array and sets the target to the current URL. With this, it nicely handles
when the URL is changed multiple times without a chain of redirects.
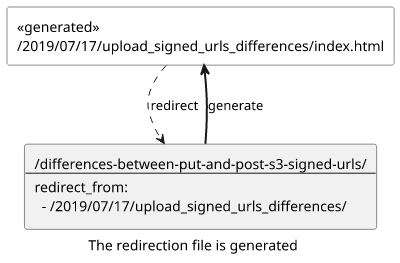
Sitemap
We had a slight problem with the above redirect solution. It generated a bunch of pages that appeared in the sitemap.
This was due to how we generated the sitemap.txt. It was a few lines of Liquid template that iterated over all the pages and outputted their URLs.
Fortunately, the jekyll-redirect-plugin works with the jekyll-sitemap-plugin to ignore these generated files from the sitemap. After installing the plugin, the generated files disappeared from the sitemap. And we started using the XML format which might be better overall.
The new permalink structure
Now that we have a mechanism to change the URLs without losing backlinks, it's time to think about what the new URLs should be.
The most common approach is to use the title but convert it to contain only lowercase characters and numbers separated by dashes. For example, Medium.com uses this approach:
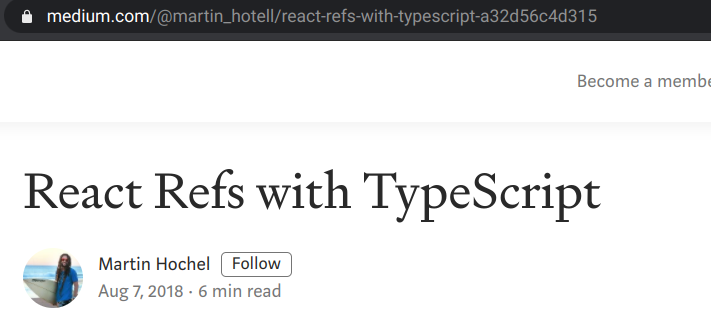
The conversion of a title to alphanumeric characters with dashes is called slugification and the result is called a slug. This is not an exact algorithm and different libraries implement it differently. For example, the title "Tips & Tricks" can be slugified to "tips-tricks" but a more sophisticated version would produce "tips-and-tricks".
Notice the random characters appended to the title of the Medium article's URL. That is because different titles can have the same slugs and that part makes sure the URLs don't clash. A simple example is "Tips & Tricks" and "Tips and Tricks" may both have the slug "tips-and-tricks".
But while Medium needs to consider clashing URLs, it's not an issue for us. Article titles are quite distinct, and if not, we can just use some code to warn us about it.
This leaves us with the ideal permalink algorithm: the slug of the article title.
Integrate to Jekyll
But in Jekyll, permalinks can only use a fixed set of placeholders. While they can also be defined
in the front matter of each page, but that overwrites the whole path while the global config
can define what is before and after the slug. For example, we might change our URLs to remove the trailing slash (https://advancedweb.hu/2019/07/17/upload_signed_urls_differences/) which would require a change in every single post.
But Jekyll has a slug placeholder for permalinks which makes the permalink: /:categories/:slug/ config possible. Its documentation:
Slugified title from the document’s filename (any character except numbers and letters is replaced as hyphen). May be overridden via the document’s slug front matter.
It still uses the filename and not the title, but at least it can be overwritten in the front matter of each page. This can be the basis for a solution.
The slug front matter defines the URL of the post, but we need to be extra careful to make sure it is defined as Jekyll would just fall back to
the slugified filename. This is a problem, but fortunately, a simple hook can make sure it can never happen:
# Make sure the slug front-matter is defined
Jekyll::Hooks.register :posts, :post_render do |post|
raise "Slug not defined in #{post.path}" if post.data["slug"].nil?
endBut there is still one edge case. Remember that Medium.com uses a hash appended to the URL to make sure every URL is unique. A similar solution is possible,
but an even easier one is to make sure that all slugs are different:
# Make sure slugs are unique across the posts
Jekyll::Hooks.register :site, :post_render do |site|
titles = site.posts.docs.map{|post| post.data["slug"]}
raise "Two slugs collide: #{titles}" if titles.uniq.length != titles.length
endThe above two hooks make sure all the advantages of the filename-based permalinks are retained. First, the latter generator makes sure the slugs are
unique, which makes the URLs unique too.
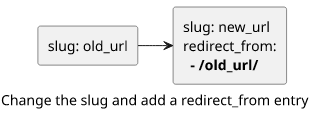
Second, a dedicated parameter controls the URL which is not changed accidentally. When the slug is changed, it's easy to remember to add the current one
to the redirect_from thus preserving backlinks.
Check slug against the article title
The above safety mechanisms are enough to make it unlikely that we lose a backlink even if we rename posts and change their URLs.
But I reckoned we can do better.
Defining the slug is still a manual process without any guarantees that it stays in sync with the title it is supposed to be derived from. A better
approach is to make a hook that checks not just that the slug is defined but also that it is the result of slugifying the title. With this,
every change to the title makes sure the slug and thus the URL, is also changed.
This can also make sure the old value is added to the redirect_from.
The current version that does this and a few other bits:
Jekyll::Hooks.register :posts, :post_render do |post|
# https://stackoverflow.com/a/4308409
def to_slug(value)
value = value.gsub(/[^\x00-\x7F]/n, '').to_s
value.gsub!(/[']+/, '')
value.gsub!(/[&]+/, 'and')
# cors: *
value.gsub!(/[*]+/, 'star')
value.gsub!(/\W+/, ' ')
value.strip!
value.downcase!
value.gsub!(' ', '-')
value
end
title = post.data["title"]
slugged = to_slug(title)
current_slug = post.data["slug"]
unless current_slug == slugged
if post.draft?
Jekyll.logger.warn("slug (#{current_slug}) does not match calculated slug (#{slugged}) for post #{post.path}")
else
raise <<~HEREDOC
slug (#{current_slug}) does not match calculated slug (#{slugged}) for post #{post.path}
***** ATTENTION *****
If this post has been published, update the redirect_from and the rss_guid attributes with the current value!
---
...
slug: #{slugged}
rss_guid: /#{current_slug}
redirect_from:
...
- /#{current_slug}/
---
HEREDOC
end
end
endIt displays an error if the slug is not what it supposed to be, with the proposed configuration changes.
The resulting workflow is as simple as possible. When we work on a post, it shows what the slug should be, but it's just a hint. When an article is published, the URL is guaranteed to be an SEO-friendly version of the title. And if we need to change the title, it prints what needs to be changed in a copy-pasteable way.
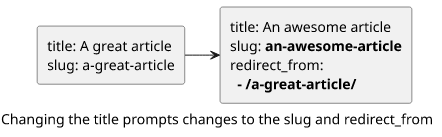
Fix RSS items
Just like any other blogs, we have an RSS stream that maintains a machine-readable list of the newest posts. RSS readers periodically check it to see
if there are any new things. An RSS reader knows when something is "new" when there is a new guid appearing in the stream. And this can be a problem.
We used the id of the post to define the guid:
<guid>{{ site.production_url }}{{ post.id }}</guid>The id should be a permanent identifier of the post, but checking the source
reveals that it is based on the slug when that is defined:
@id ||= File.join(File.dirname(url), (data["slug"] || basename_without_ext).to_s)Before we started using the slug front matter the id was only dependent on the filename, such as /2019/07/17/upload_signed_urls_differences.
But now, whenever we change the slug, such as when we change the title of a post, it will change the id and RSS readers see it as a new post.
Because of this, post.id is no longer suitable to be part of the guid.
A simple solution is to define another front matter which overwrites the post.id when defined. When the slug changes, we just need to
define this rss_guid to be the first published slug:
<guid>{{ site.production_url }}{{ post.rss_guid | default: post.id }}</guid>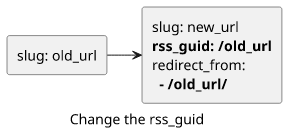
The generator above takes this into consideration and outputs what needs to be changed in this parameter.
Conclusion
Changing URLs is risky and requires careful planning. Make sure you place redirects from the old URLs to the new ones, either by HTTP 301 status codes or an HTML file that does the redirection. Also, make sure to use a system that makes it unlikely that an unrelated change breaks backlinks.
But handled with care, URLs can be changed.

