AWS AppSync: Getting started
How to create an AppSync API, add a schema, configure data sources and resolvers, and test using the AWS Management Console


AWS AppSync is a managed GraphQL service integrated into the AWS cloud. It offers a graph-based way to query data and that offers several benefits over the REST model. On the other hand, it introduces a lot of new concepts that make this technology harder to adopt, not to mention the AWS-specific additions AppSync brings to the table.
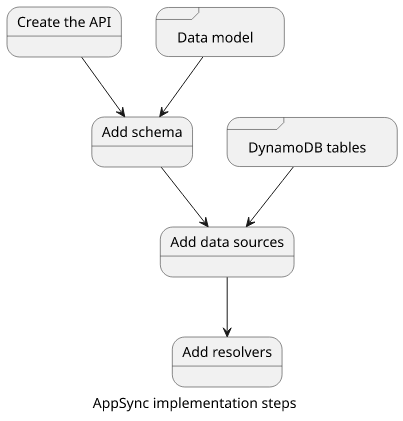
In this article, we'll cover a simple GraphQL data model and how to deploy it with AppSync using the AWS Management Console. You'll learn about the important concepts of GraphQL (GraphQL schema, resolvers) and AppSync (Data sources), see how to create and configure the resources needed for the API, and we'll close with a detailed discussion on how each piece works to provide a response to GraphQL queries.


The data model
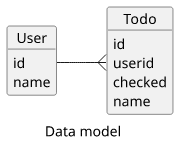
As with every API, we first need to think about what kind of data we want to store and their relationships. In this example, we'll have users and every user can have a list of Todo items.
With this model, the API will offer queries to fetch all users and by id, then to query the Todo items for a given user. It will also allow creating new items for the users.
Step #1: Create the API
The first step is to go to the AppSync Console and create a new API. AWS offers several wizards and templates, but start from scratch instead. The only required argument is a name, which does not need to be unique in a region.
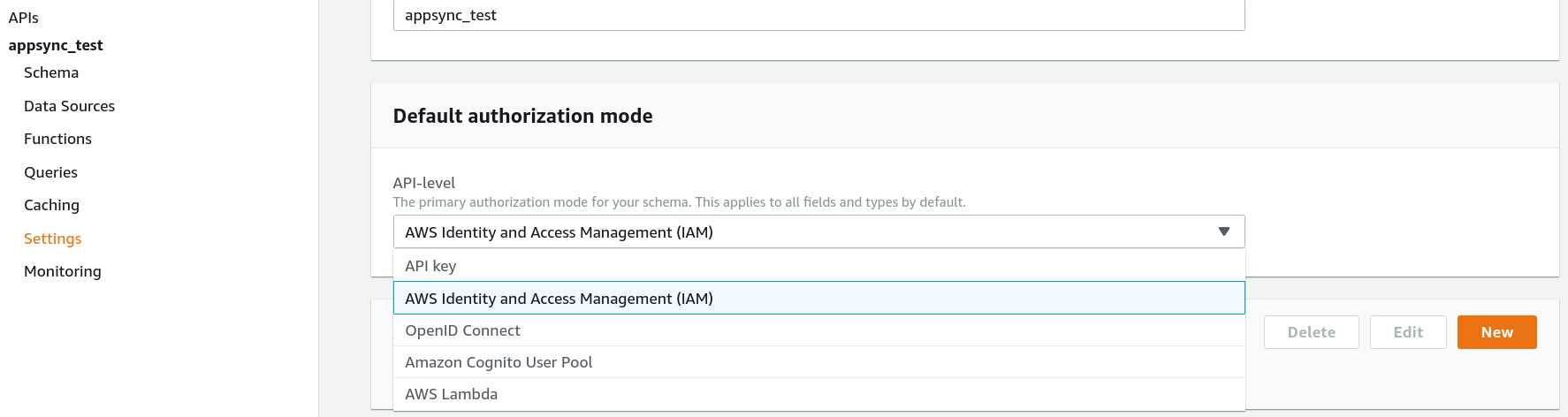
Authorization: API key vs IAM vs Cognito
AppSync provides several ways to setup authorization (who can call the API). Most tutorials use the API key approach, where you generate keys on the Console then send that key with every request. It's a good way to get started and start seeing responses, but it's not a permanent solution.
IAM authorization uses IAM entities (users or roles) and you can use policies attached to them to fine-tune access control. It is good when the clients have AWS credentials (Access Key ID and Secret Access Key), which is the case when using the Management Console, but it's usually not the intended usage.

Then Cognito authorization is the most versatile and it supports login to a website and sending requests to the API, a setup that most webapps follow. On the other hand, it requires setting up Cognito, which requires some work.

In this tutorial, we'll use the Management Console, so choose IAM authorization for the API.
Step #2: Add the schema
The GraphQL schema defines what is possible with the API. It defines the object model, the queries, and the mutations (and in the case of AppSync, the subscriptions). This is a text document that you can copy-paste on the Schema page for the API:
type Mutation {
addTodo(userId: ID!, name: String!): Todo!
}
type Query {
user(id: ID): User
allUsers: [User]
}
type Todo {
name: String
checked: Boolean
user: User
}
type User {
id: ID
name: String
todos: [Todo]
}
schema {
query: Query
mutation: Mutation
}There are several important elements here. First the types are the nodes in the graph. We have Users and Todos.
The fields of the types are either scalars (Todo.name) or edges between the nodes (Todo.user). These fields define what data clients can query and how
they can traverse the graph.
Queries are the entry points to the graph. For example, the Query.user allows getting a single user by its ID, then the request can get its
name and its Todo items using its fields.
Moving between nodes is a core concept in GraphQL and it's especially important for access control. For example, if a user can query only itself (through some
custom mechanism that limits the allowed ids in the Query.user) and there are no edges to another user node then a user can't access other users' data.
Finally, mutations define what data clients can change. There is only a semantic difference between a query and a mutation as there is no mechanism that prevents a query from changing data. But it's best practice to make a clear separation between things that make changes and those that don't. In our example, clients can add a new Todo entry.
Implementation
The schema is an abstract concept and it does not contain any information on how to get the data for the queries or how to change the database for the mutations. Think of it as an interface waiting for an implementation.
This implementation needs two things: data sources and resolvers.
DynamoDB
But first, we need a place to store the data. In this example, we'll use DynamoDB, but AppSync does not care about where the data comes from. It provides some utilities for common AWS services, but ultimately you could call an arbitrary HTTP endpoint or a Lambda function that produces the data.
We'll need two tables to store the user and their Todo items:
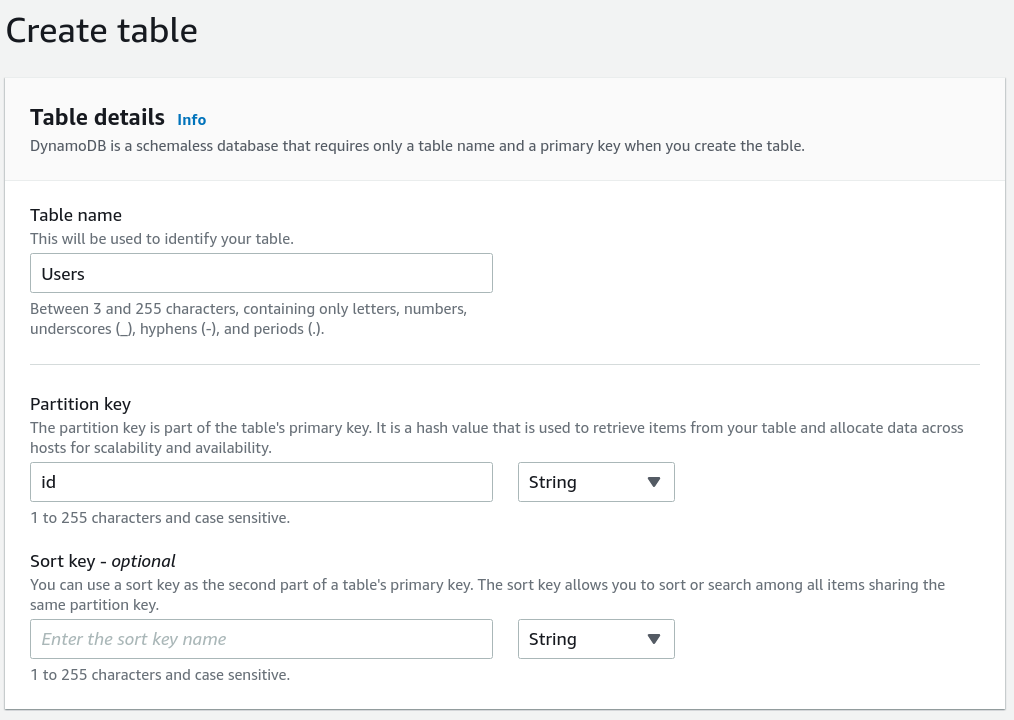
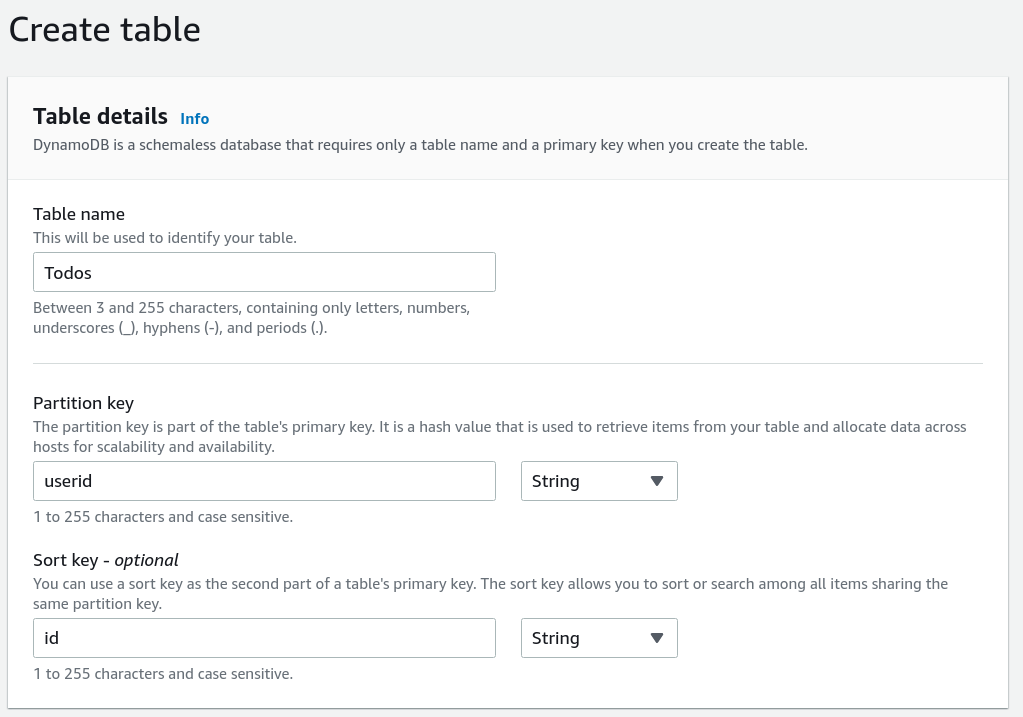
Then add some sample data, so that the API can return it:
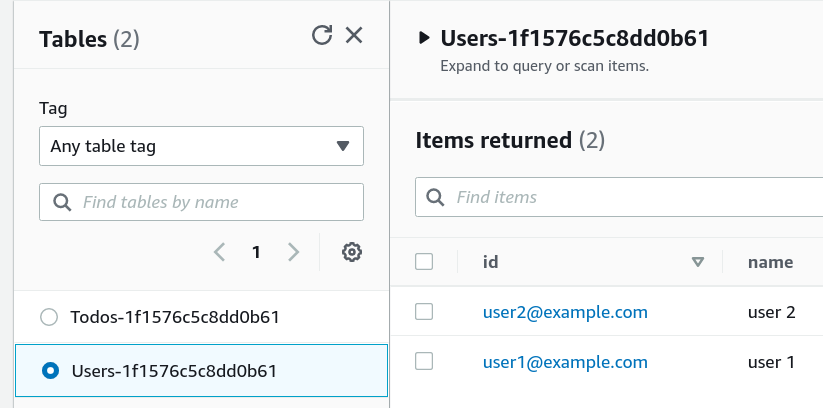
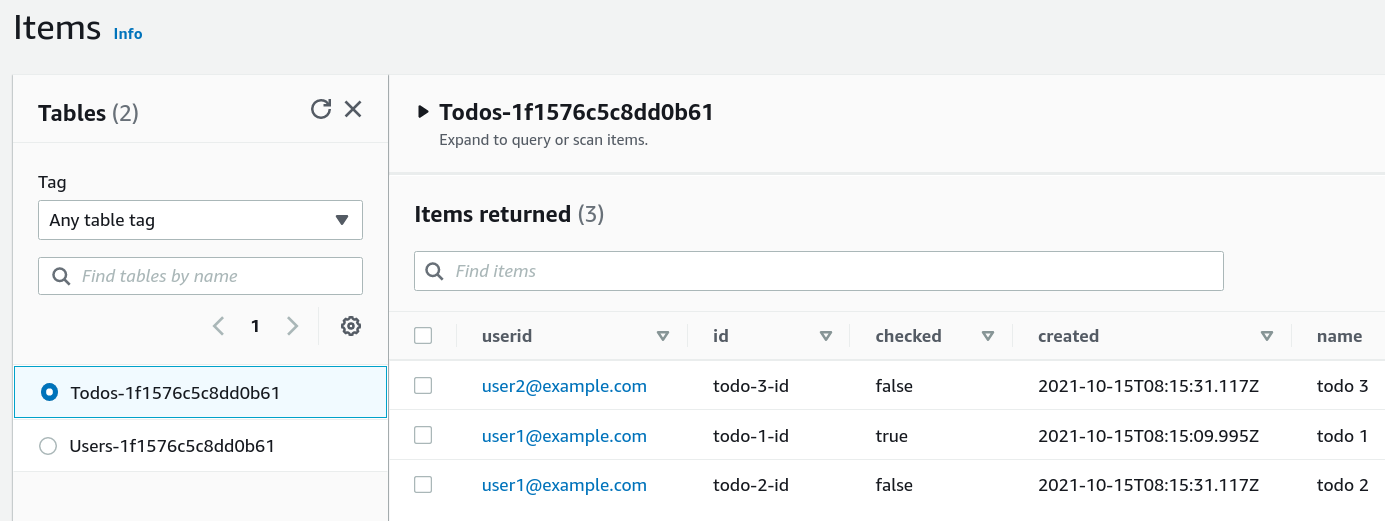
(These are populated for you if use the sample repo)
Step #3: Data sources
Now that we have a database to use, we need to configure AppSync to use it. This is where data sources come into play.
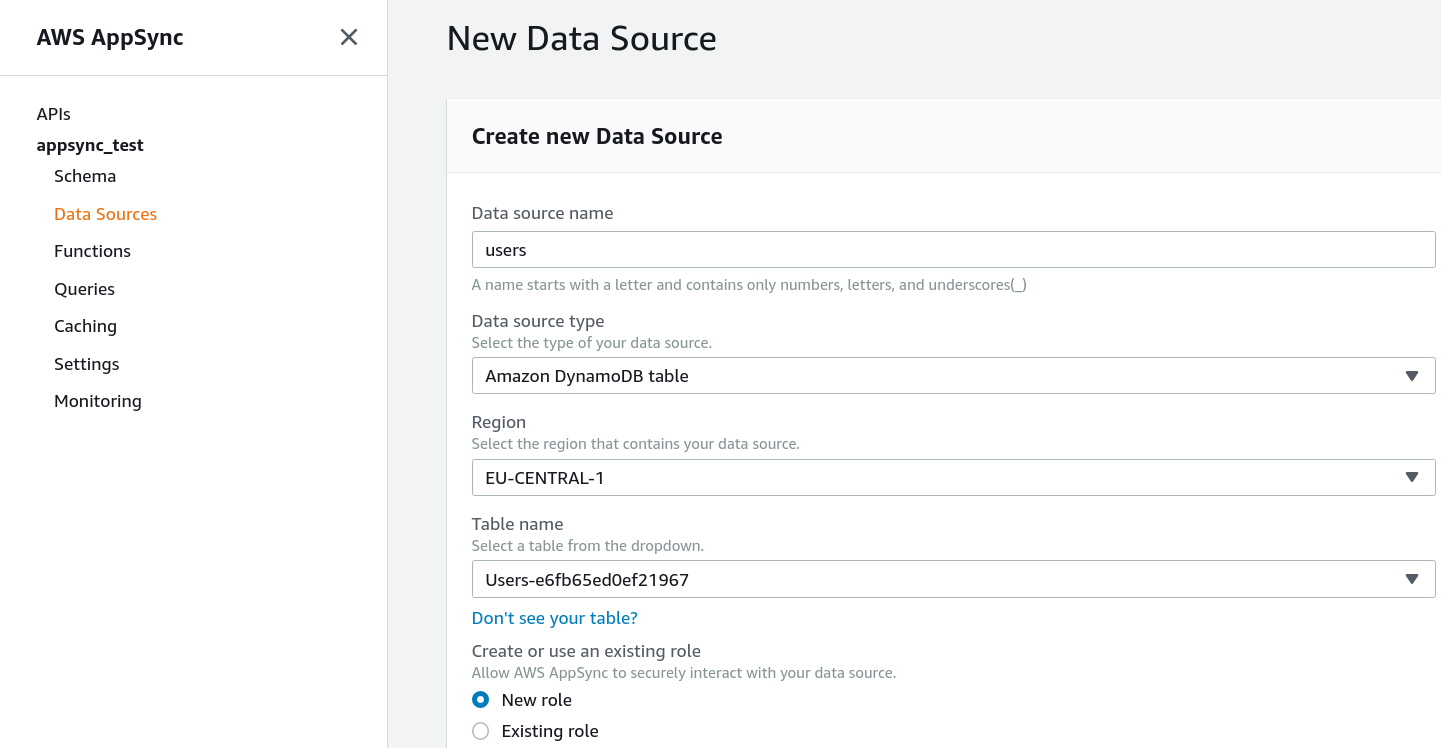
A data source defines how AppSync can use another service to fetch/mutate data. In our case, we need 2 data sources, one for each table. The type is "DynamoDB", and we need to define the region and the table name.
Finally, we need to give AppSync permissions to reach the data source. This is done using a role that has a policy that allows read/write access to the table.
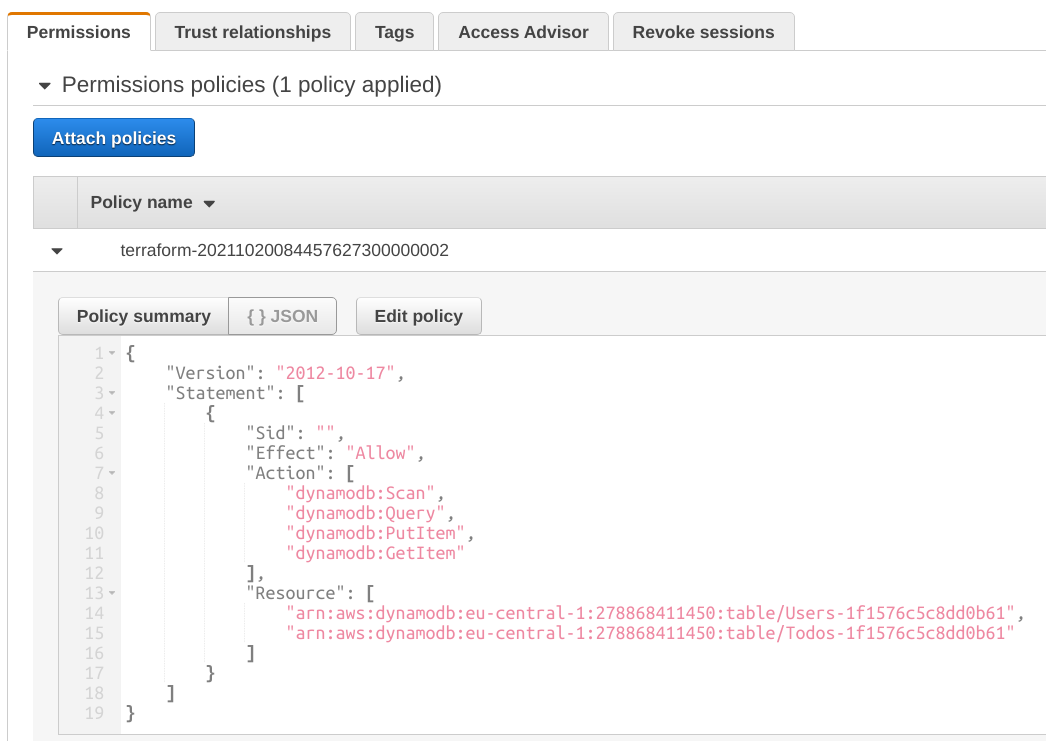
I found it a best practice to create 1 role for the AppSync API and use that for all data sources. Especially when a DynamoDB transaction needs to read/write multiple tables it's a cleaner solution to creating a separate role for each data source.
Step #4: Add resolvers
So far we have a schema for AppSync and we configured the data sources. The last step is to add resolvers. Resolvers define how AppSync can get the data for a query or a field. They use the data sources to provide the implementation for the schema.
In practice, you'll need a lot of them and most of the time developing an AppSync API is spent writing resolvers.
Resolvers are for fields, and you can (though not required to) define a resolver for every field in your schema. You can find the resolvers in the Schema page on the right.
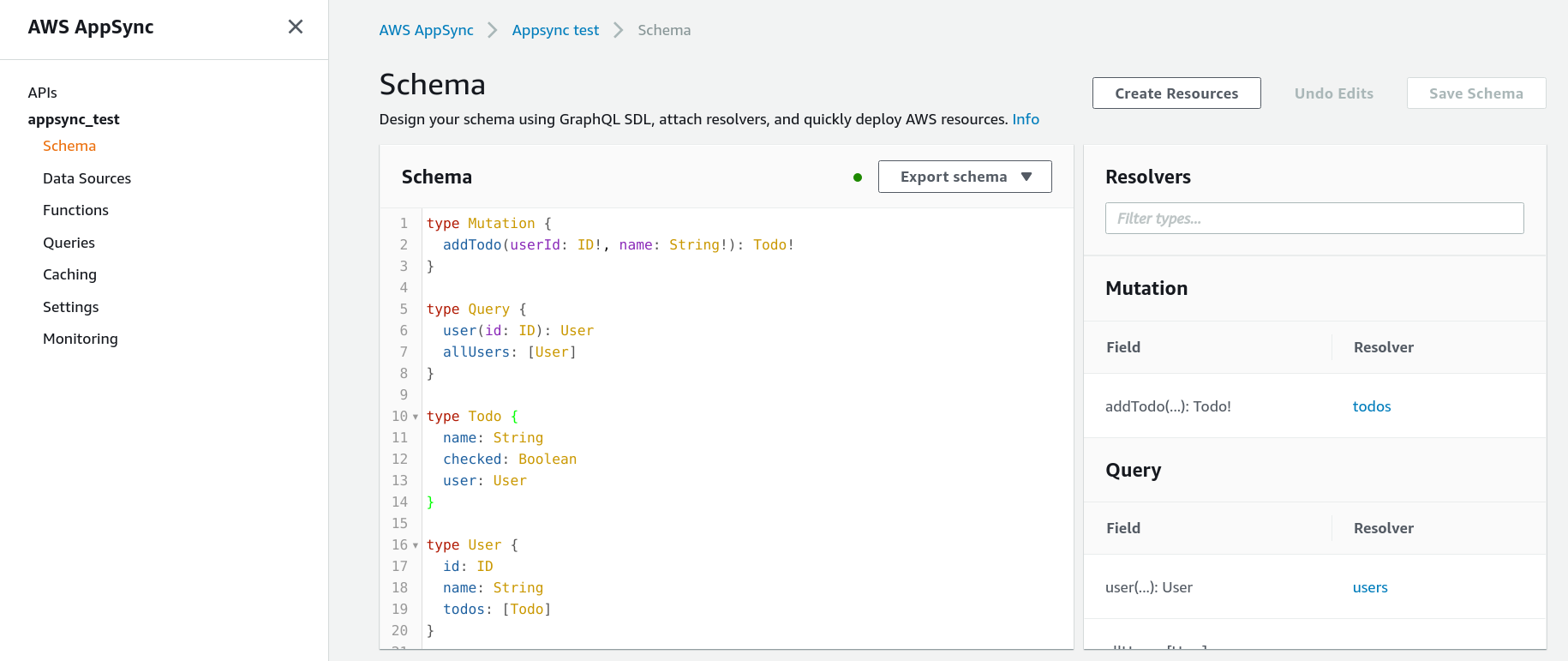
Query.user
To see how resolvers work, let's start with a simple one, Query.user! According to our schema, it gets an id and returns a User:
type Query {
user(id: ID): User
}
type User {
id: ID
name: String
todos: [Todo]
}Then we have our data source that allows AppSync to read data from the users table. The resolver uses the argument to send a DynamoDB query and transform the request back to a User object.
Resolvers are for fields, so create one by going to the Schema page and click Attach next to the user field under Query.
A resolver needs 3 things: a data source, a request mapping template, and a response mapping template. In this case, the data source is the users table.
For the request mapping template use this one:
{
"version" : "2018-05-29",
"operation" : "GetItem",
"key" : {
"id": {"S": $util.toJson($ctx.args.id)}
},
"consistentRead" : true
}The $ctx.args.id is the id argument of the query. Then the $util.toJson transforms it to a String in a safe
way. Which means this request sends a GetItem
operation to the DynamoDB table.
How to know the structure of the request? The documentation page details it for each type of data source.
For the response mapping template:
#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$util.toJson($ctx.result)The first part is error checking. If DynamoDB returns an error then $ctx.error will be defined and $util.error will terminate the processing and
return an error response. This is important as AppSync by default won't terminate the processing when it encounters an error (when you use the 2018-05-29
version).
If there was no error, the response will be $ctx.result, which is the result of the DynamoDB request.
Query.allUsers
The structure is the same for getting all users. Here, we don't have an id but we'll send a Scan request to the DynamoDB table.
The request mapping template:
{
"version" : "2018-05-29",
"operation" : "Scan"
}DynamoDB returns the items in an items field, so we need to return that in the response mapping template:
#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$utils.toJson($ctx.result.items)(Note that it's not the recommended way to return a list of items since DynamoDB might not return all the items and also AppSync has some hard limits on the response size. It's better to implement paging.)
User.todos
Next, we need to define how to get the Todo items for a given user. This is done through the todos field of the User type.
Here, we are traversing the graph, so we have a source object (the User). Its attributes are available in the $ctx.source variable. And since we are
returning Todos, the data source is the todos table.
In the request mapping template, send a Query:
{
"version" : "2018-05-29",
"operation" : "Query",
"query" : {
"expression": "userid = :userid",
"expressionValues" : {
":userid" : $util.dynamodb.toDynamoDBJson($ctx.source.id)
}
}
}The response mapping template works the same as for the Scan:
#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$utils.toJson($ctx.result.items)Other fields
What about the other fields for the User type? A user has a name and an id as well. How does AppSync know what to return when a query wants the
User's name?
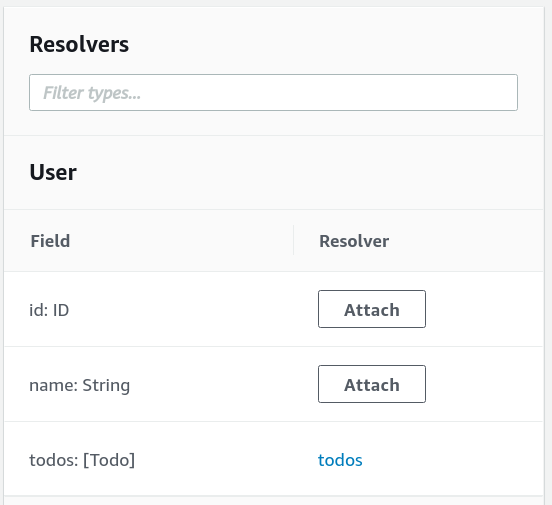
When the source object (the User, in our case) contains the field then AppSync will return that as-is. And since the user table contains the id and the
name for the users, there is an implicit mapping between those values and the GraphQL schema.
When Query.user runs, it returns the full user object that is stored in the database:
{
"id": "user1@example.com",
"name": "user 1"
}So when a GraphQL needs the name, it is read from the database without a resolver:
query MyQuery {
user(id: "user1@example.com") {
name
}
}Notice that there is no todos field in the DynamoDB object. That's why we need to add a resolver for that.
While it's not required to add a resolver for a field that comes from the database, you can still add one if you need to. It comes useful when you need to convert
the data, such as if the database stores a timestamp in POSIX but the schema specifies AWSDateTime that is ISO8601. In that case, a resolver can read the POSIX
timestamp from the source ($ctx.source.created_at, for example) and convert that to ISO8601.
Todo.user
To allow querying the user for a given Todo item, we need to add a resolver for that field too. This is useful when a query or a field returns a Todo and the client wants to know which user it belongs to.
Since we want a User as a response, the data source will be the users table.
And the request mapping template:
{
"version" : "2018-05-29",
"operation" : "GetItem",
"key" : {
"id": {"S": $util.toJson($ctx.source.userid)}
},
"consistentRead" : true
}The $ctx.source is the Todo item.
And the response mapping template:
#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$util.toJson($ctx.result)Mutation
So far we've covered the queries and the fields. They allow getting data from the AppSync API. Now we'll implement the mutation that allows adding new Todo items.
Mutations are similar to queries, but they are semantically for changing data instead of reading it. The only mutation in our data model needs a userId and a
name and returns a Todo item:
type Mutation {
addTodo(userId: ID!, name: String!): Todo!
}So we need to write a resolver that adds an item to the Todos table with the given arguments, the userId and the name that are available in
the $ctx.arguments object. And we'll use a PutItem operation to store the data in the resolver mapping template:
{
"version" : "2018-05-29",
"operation" : "PutItem",
"key" : {
"userid": {"S": $util.toJson($ctx.arguments.userId)},
"id": {"S": $util.toJson($util.autoId())}
},
"attributeValues": {
"checked": {"BOOL": false},
"name": {"S": $util.toJson($ctx.arguments.name)}
}
}The $util.autoId() returns a random UUID, which is suitable for the id of the Todo item. It is one of the many functions built-in to AppSync, and
there is a long reference page that shows all the other ones.
The PutItem operation returns the full objects, the response mapping template can return the result as-is:
#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$util.toJson($ctx.result)Testing
The AWS Management Console provides a convenient query editor/runner on the Queries page. On the left you can define what you want to include in the query, and the generated request is shown in the middle. The right panel shows the response.
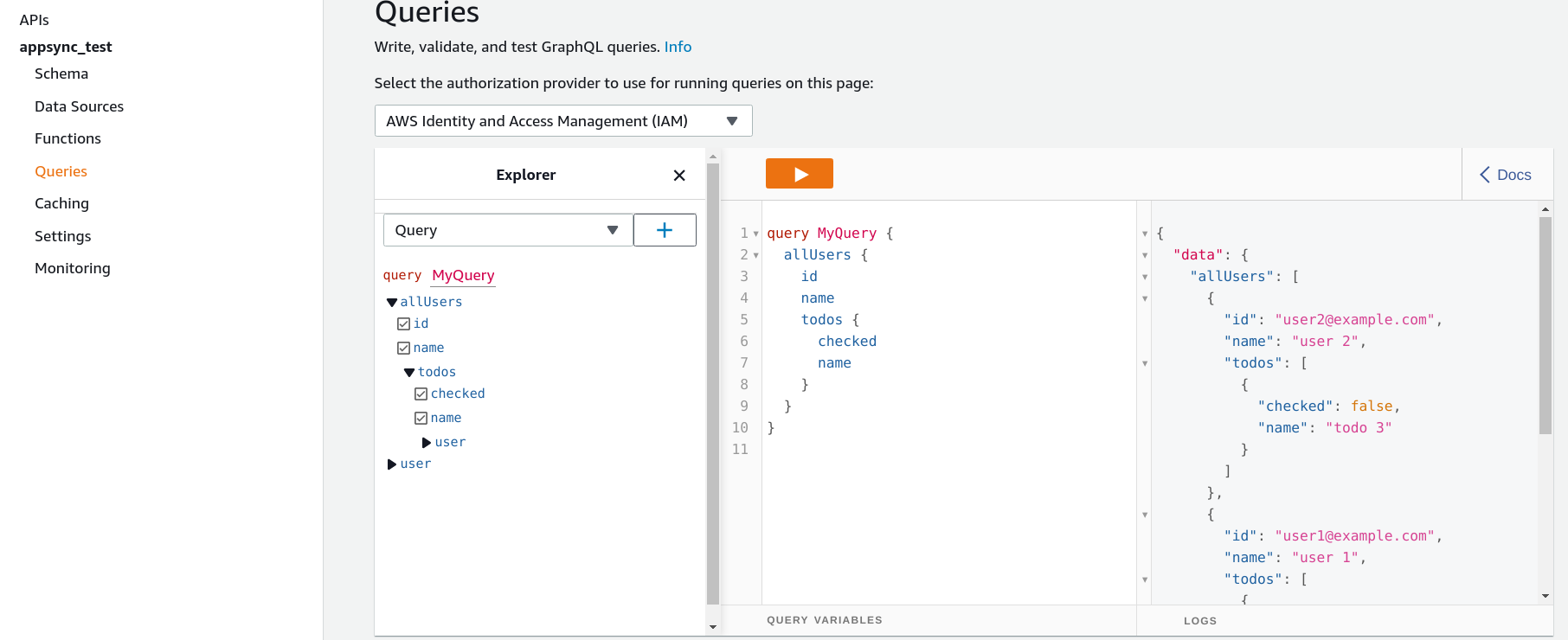
For example, this query gets all users, their id and name fields, and all their Todo items:
query MyQuery {
allUsers {
id
name
todos {
checked
name
}
}
}Under the hood
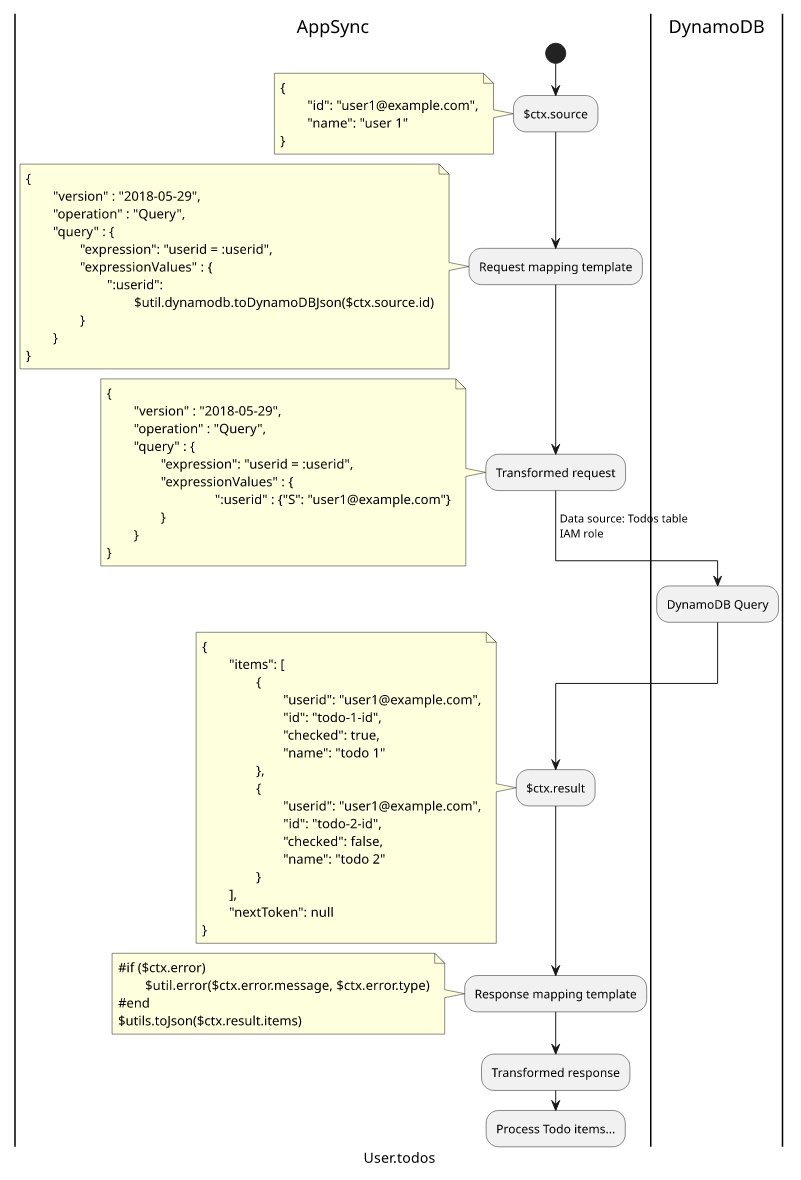
Finally, let's see what happens under the hood! Getting from a request to the response involves quite a few steps, but it's important to have a general undestanding how each piece works together.
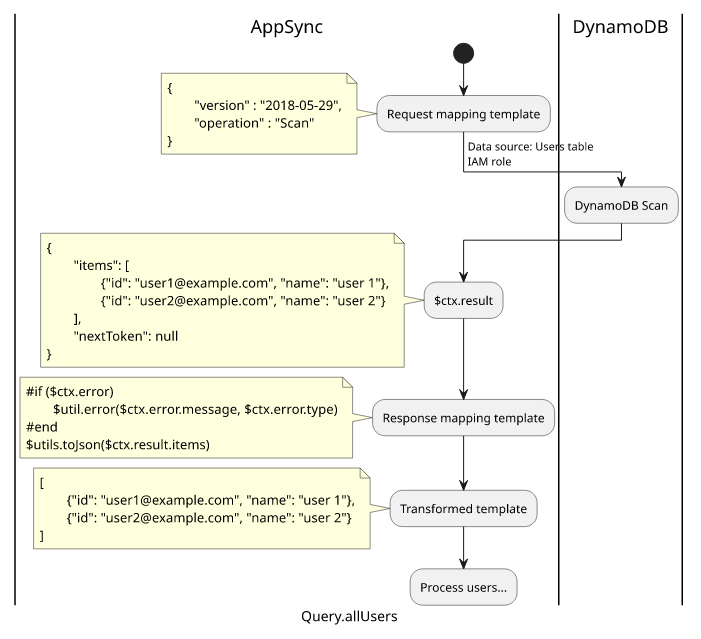
The above query comes in. The topmost operation is Query.allUsers, so AppSync will start with processing that. It transforms the request template and gets
this result:
{
"version" : "2018-05-29",
"operation" : "Scan"
}The data source is the Users table, so it uses the IAM role configured and issues a Scan request. DynamoDB sends back a response:
{
"items": [
{"id": "user1@example.com", "name": "user 1"},
{"id": "user2@example.com", "name": "user 2"}
],
"nextToken": null
}The response mapping template is:
#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$utils.toJson($ctx.result.items)The $ctx.result in the response mapping template will be the JSON object. After transformation, the result will be:
[
{"id": "user1@example.com", "name": "user 1"},
{"id": "user2@example.com", "name": "user 2"}
]The schema defined the response as an array of User objects ([User]), AppSync needs to transform the two items to Users. This happens independently, so
we'll cover only the first item.
The query asked for 3 fields: id, name, and todos. The id and the name does not have resolvers, so they are returnd as-is from the
result.
For the todos, AppSync invokes the User.todos resolver. The request mapping template for that field is:
{
"version" : "2018-05-29",
"operation" : "Query",
"query" : {
"expression": "userid = :userid",
"expressionValues" : {
":userid" : $util.dynamodb.toDynamoDBJson($ctx.source.id)
}
}
}($util.dynamodb.toDynamoDBJson transforms the string to the DynamoDB type structure)
Here, the $ctx.source is the user object ({"id": "user1@example.com", "name": "user 1"}), so the transformed template will be:
{
"version" : "2018-05-29",
"operation" : "Query",
"query" : {
"expression": "userid = :userid",
"expressionValues" : {
":userid" : {"S": "user1@example.com"}
}
}
}The configured data source is the todos table, so AppSync sends a Query to the table and uses the configured IAM Role.
DynamoDB returns a list of Todo items:
{
"items": [
{"userid": "user1@example.com", "id": "todo-1-id", "checked": true, "name": "todo 1"},
{"userid": "user1@example.com", "id": "todo-2-id", "checked": false, "name": "todo 2"}
],
"nextToken": null
}The configured response mapping template for this resolver:
#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$utils.toJson($ctx.result.items)With the DynamoDB query result as $ctx.result, the transformed template will be:
[
{"userid": "user1@example.com", "id": "todo-1-id", "checked": true, "name": "todo 1"},
{"userid": "user1@example.com", "id": "todo-2-id", "checked": false, "name": "todo 2"}
]Since the User.todos returns an array of Todos ([Todo]), AppSync transforms each object to a Todo. The query asked for the checked and the
name fields, and they don't have resolvers configured, they are returned as-is.
When this process finishes for the other user, AppSync has everything it needs to fulfill the query.