
How to use Lambda resolvers with AppSync
How to call a Lambda function for a GraphQL field


Lambda with AppSync
A resolver defines how a GraphQL field gets its value, such as what database query should AppSync run when a query needs that field, or what HTTP request to send.
AppSync supports several resolver types, and one of them is the Lambda resolver. This calls a Lambda function with parameters defined in the request mapping template and returns a value defined by the response mapping template.
The Lambda resolver type is a way to opt out of AppSync's obscure mapping templates built on VTL. You can define a Lambda function that gets the full resolver context and returns what you want to return for that part of the GraphQL query. While from an architectural point of view the VTL-based templates provide a cleaner solution, opting for a Lambda function makes it a lot easier to get started with AppSync.
Other than to get rid of VTL, sometimes the best way to produce some data is to call a Lambda function. This is especially the case when you need to interface with other services. If you need to register a Cognito user, for example, you can implement that part in a function and use that for a GraphQL mutation. With the ability to run arbitrary code for any query or mutation allows AppSync to adapt to any kind of workload, as long as it fits into its "small and fast" query limits.
Let's see the different parts that we need to use a Lambda function as an AppSync data source!

Lambda data source
The first part is to create a Lambda function and add that to the AppSync API as a data source. For this, go to the "Data Sources" page and add a new data source.
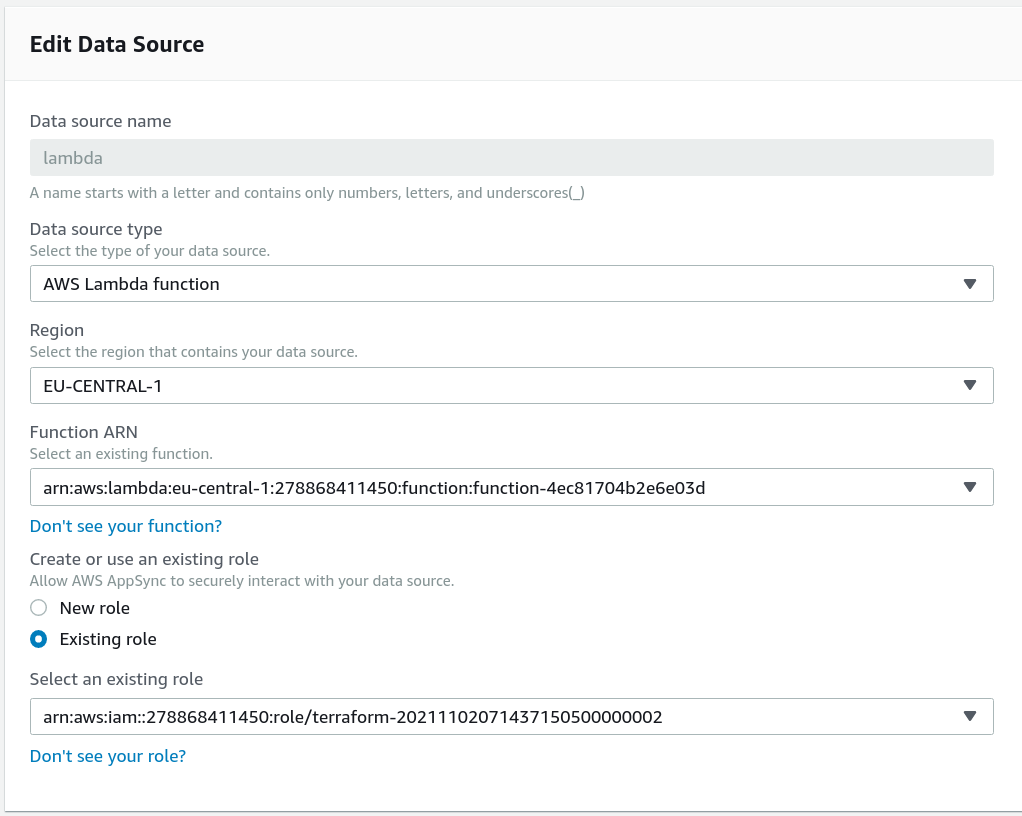
The first part is straightforward: define the data source as a Lambda function and define which function to call. The bottom part is about a role that AppSync
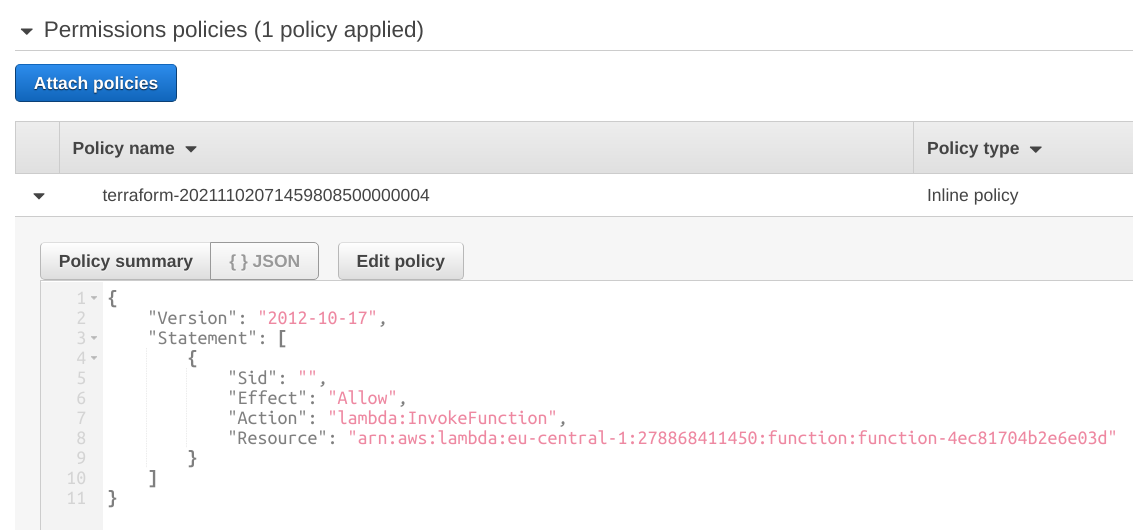
uses when it calls the function. AppSync needs the lambda:InvokeFunction permission for the function:
Resolver config
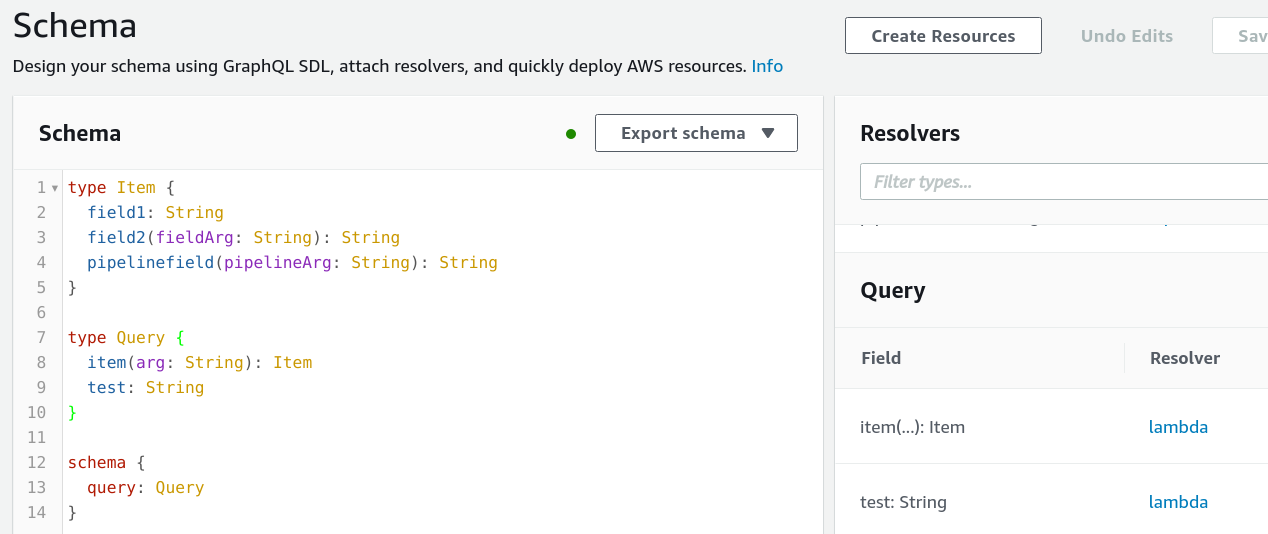
The next step is to add the Lambda data source as a resolver for a field. Let's say there is a test field for a Query:
type Query {
test: String
}To add a resolver to this field, go the the "Schema" page and attach a resolver for that field:
There is not much to configure here:
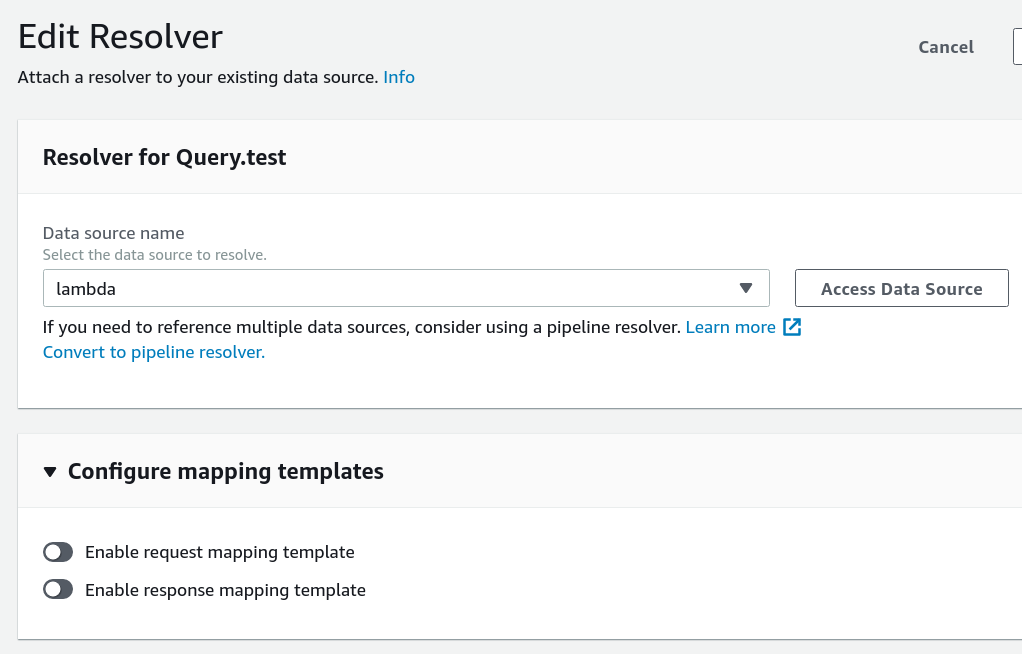
Request and response mapping templates are optional for a Lambda data source. If you don't define one or the other, there is a default AppSync will use. The default request mapping template forwards the whole context to the function, and the default response mapping template returns what the function returns.
Testing
Let's see how this resolver configuration works! To see what the Lambda function gets, the handler returns the different parts of the context in stringified form:
exports.handler = async (event, context) => {
const {arguments, prev, stash, identity, source} = event;
return JSON.stringify({arguments, prev, stash, identity, source});
};Why not the whole event object? It contains a ton of unnecessary metadata that it makes it hard to find the important parts.
Let's do a test query:
query MyQuery {
test
}This gives a result:
{
"data": {
"test": "{\"arguments\":{},\"prev\":null,\"stash\":{},\"identity\":{\"accountId\":\"xx\",\"cognitoIdentityAuthProvider\":null,\"cognitoIdentityAuthType\":null,\"cognitoIdentityId\":null,\"cognitoIdentityPoolId\":null,\"sourceIp\":[\"xx.xx.xx.xx\"],\"userArn\":\"arn:aws:iam::xx:user/xx\",\"username\":\"XX\"},\"source\":null}"
}
}Un-stringifying the payload:
{
"arguments":{},
"prev":null,
"stash":{},
"identity":{
"accountId":"xx",
"cognitoIdentityAuthProvider":null,
"cognitoIdentityAuthType":null,
"cognitoIdentityId":null,
"cognitoIdentityPoolId":null,
"sourceIp":["xx.xx.xx.xx"],
"userArn":"arn:aws:iam::xx:user/xx",
"username":"XX"
},
"source":null
}This reflects the context structure detailed in the reference.
Arguments
The function also gets the arguments and the source object, just like any other resolver.
Let's say we have a more complex schema with a type and field arguments:
type Item {
field2(fieldArg: String): String
}
type Query {
item(arg: String): Item
}
schema {
query: Query
}The Query.item returns an object with some arbitrary structure:
{
"field1": "test",
"field2": "another test",
"arguments": $util.toJson($ctx.arguments)
}Then Item.field2 calls the same Lambda function that we saw previously.
Sending this query:
query MyQuery {
item(arg: "argvalue") {
field2(fieldArg: "fieldargvalue")
}
}Returns this response:
{
"data": {
"item": {
"field2": "{\"arguments\":{\"fieldArg\":\"fieldargvalue\"},\"prev\":null,\"stash\":{},\"identity\":{\"accountId\":\"xx\",\"cognitoIdentityAuthProvider\":null,\"cognitoIdentityAuthType\":null,\"cognitoIdentityId\":null,\"cognitoIdentityPoolId\":null,\"sourceIp\":[\"xx.xx.xx.xx\"],\"userArn\":\"arn:aws:iam::xx:user/xx\",\"username\":\"XX\"},\"source\":{\"field1\":\"test\",\"field2\":\"another test\",\"arguments\":{\"arg\":\"argvalue\"}}}"
}
}
}Un-stringifying the result gives:
{
"arguments": {
"fieldArg":"fieldargvalue"
},
"prev":null,
"stash":{},
"identity":{
"accountId":"xx",
"cognitoIdentityAuthProvider":null,
"cognitoIdentityAuthType":null,
"cognitoIdentityId":null,
"cognitoIdentityPoolId":null,
"sourceIp":["xx.xx.xx.xx"],
"userArn":"arn:aws:iam::xx:user/xx",
"username":"XX"
},
"source":{
"field1":"test",
"field2":"another test",
"arguments": {
"arg":"argvalue"
}
}
}Remember that this is the event object that the inner resolver (Item.field2) gets. That's why the arguments contains only the argument for
the field2 and not the Query.item. On the other hand, the source is the result of the Query.item resolver.
The event also contains a prev and a stash fields but those are null/empty as this is not a pipeline resolver.
Conclusion
Using a Lambda function as an AppSync resolver is a great way to integrate the GraphQL API with services that have no in-built support. With a Lambda function, you can also opt out of VTL altogether and use AppSync similar to just an API provider.

