
How to implement access control in a GraphQL API
How to think in graphs and restrict what data is available through a GraphQL API


The basic purpose of a GraphQL API is the same as any other API: provide an interface where clients can get and change data. As most real-world APIs are used by many types of users, defining who can access what is a central topic of every API design.
GraphQL is about graphs, so there are objects and connections between those objects and queries can define what part of the object graph they need. Access control is similarly based on connections and about what objects a given user can reach. And this is defined by what objects the users can query directly ("entry points") and where they can go from there ("traversals").
In this article we'll look into the different ways to define access control in a GraphQL API and what are the common problems you'll see.

Data model
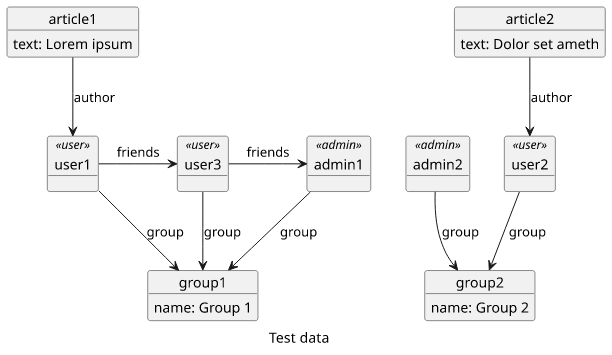
In our example, we have users, and these users belong to groups. Let's say the groups are strict separation of users, like different customers on Slack or Telegram channels. We don't want users to get access to groups other than their own. Users can have friends, and they can only be in-group.
Also, users can publish public articles that anybody can read.
In terms of a graph, we have a few test users and other objects:
Entry points
Entry points are queries and mutations in the GraphQL schema. They provide an "entry" to the object graph and they allow the query to move to other objects from here.
Entry points can rely on their arguments and the caller identity to decide what to return, there is no source object here (no $ctx.source). For example,
the user Query gets a username argument and returns a User object:
type Query {
user(username: String!): User
}Similarly, the allUsers Query returns a list of users and it does not accept any arguments:
type Query {
allUsers: [User]
}Schema-based access control
The easiest way to control access to the entry points is to deny them based on the caller identity. In case of AppSync, you can add a directive for the field itself and AWS automatically rejects requests that are from users not in the specified Cognito group:
type Query {
allUsers: [User]
@aws_cognito_user_pools(cognito_groups: ["admin"])
@aws_auth(cognito_groups: ["admin"])This is an all-or-nothing control. If a user is in the admin Cognito group then it can call allUsers, if not then AppSync returns an access denied
error.

For example, sending this query with user1:
query MyQuery {
allUsers {
username
}
}Returns an error:
{
"data": {
"allUsers": null
},
"errors": [
{
"path": [
"allUsers"
],
"data": null,
"errorType": "Unauthorized",
"errorInfo": null,
"locations": [
{
"line": 2,
"column": 3,
"sourceName": null
}
],
"message": "Not Authorized to access allUsers on type Query"
}
]
}Resolver-based access control
The biggest problem with schema directives is that they are all-or-nothing. You can restrict what fields a user in a Cognito group can access, but you can't restrict arguments or limit the data returned.
A more fine-grained approach is to code the access control decision into the resolvers for this field. For example, let's implement a check that the user
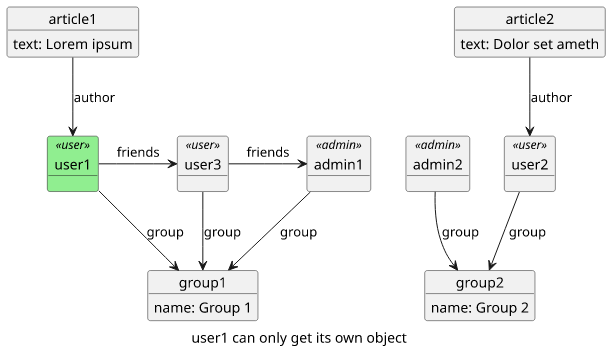
Query accepts only the username of the signed-in user and nothing else. With this, users can query themselves, but can't access others.
For this, we need to add a check to the resolver for the Query.user field:
#if ($ctx.identity.username != $ctx.args.username)
$util.unauthorized()
#else
{
"version" : "2018-05-29",
"operation" : "GetItem",
"key" : {
"username": {"S": $util.toJson($ctx.args.username)}
},
"consistentRead" : true
}
#endThe first part (#if(...)) checks that the signed-in user's username ($ctx.identity.username) is different than the argument
($ctx.args.username) and if it is then it sends an unauthorized error.
To test it, first send a query with the correct username:
query MyQuery {
user(username: "user1") {
username
}
}The result is the user object:
{
"data": {
"user": {
"username": "user1"
}
}
}On the other hand, querying a different user returns an error:
{
"data": {
"user": null
},
"errors": [
{
"path": [
"user"
],
"data": null,
"errorType": "Unauthorized",
"errorInfo": null,
"locations": [
{
"line": 2,
"column": 3,
"sourceName": null
}
],
"message": "Not Authorized to access user on type User"
}
]
}This allows a user to enter the object graph at its own user object and nowhere else using this query.
Filtering results
But some operations are not allowed-or-denied but something in between. This is where response resolver templates come into play. For example,
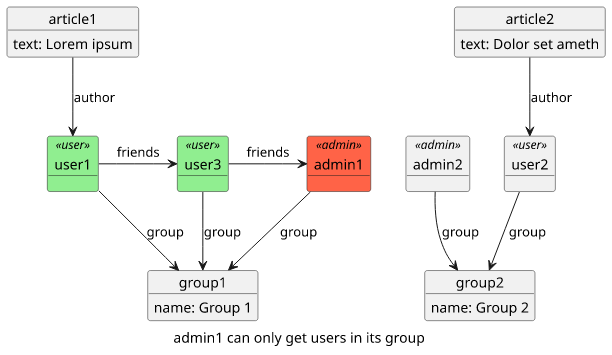
the getAllUsers query allows an administrator to get a list of all users. But in our object model, users belong to a group and we don't want an admin of
one group to get users for another one.
To implement this, we need two things:
- get the group of the caller user
- filter the results to return only users in the same group
The first point needs a separate call to the database to fetch the current user's object. Remember that our concept of a "group" is different than a Cognito group, so this needs to come from the database. And for this, we'll need a pipeline resolver.

The first resolver sends a query to the database then puts the result to the stash:
{
"version" : "2018-05-29",
"operation" : "GetItem",
"key" : {
"username": {"S": $util.toJson($ctx.identity.username)}
},
"consistentRead" : true
}#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$util.qr($ctx.stash.put("user", $ctx.result))
{}Then the next resolver can retrieve the list of users then filter the list based on the value in the stash:
{
"version" : "2018-05-29",
"operation" : "Scan",
"consistentRead" : true
}#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
#set($results = [])
#foreach($res in $ctx.result.items)
#if($ctx.stash.user.group == $res.group)
$util.qr($results.add($res))
#end
#end
$util.toJson($results)Testing the query shows that admin1 gets only users in its group:
query MyQuery {
allUsers {
username
}
}{
"data": {
"allUsers": [
{
"username": "admin1"
},
{
"username": "user1"
},
{
"username": "user3"
}
]
}
}
Traversals
In GraphQL the queries also define other objects the caller needs. This makes it easy to fetch a complex object structure in one single query and saving network roundtrips, one of the biggest contributors to perceived slowness. But in this structure, users have access not only what the queries return but also all the other objects that are accessible via their fields, recursively.
For example, users have friends:
type User {
username: String!
friends: [User]
}Does that mean that a user can access its friends' friends also?
Yes, as it can go from its own User object to the objects of its friends, then move along on the same edge:
query MyQuery {
user(username: "user1") {
username
friends {
username
friends {
username
}
}
}
}{
"data": {
"user": {
"username": "user1",
"friends": [
{
"username": "user3",
"friends": [
{
"username": "admin1"
}
]
}
]
}
}
}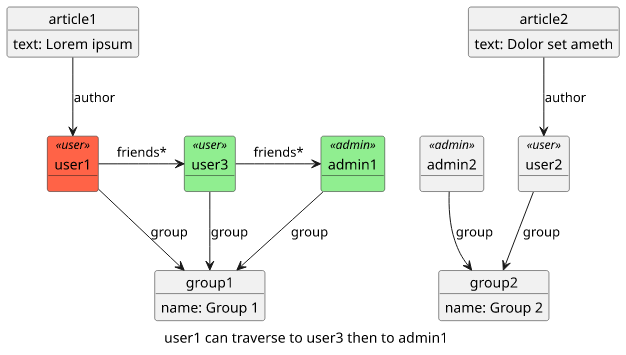
This behavior can lead to surprising results. All users who can be friends are inside the same group, so a user can not "break out" of its group just by moving along the "friends" edge. But a seemingly unrelated change can expose data we don't want clients to access.
Let's add a separate feature! We want users to be able to write public articles that all users can see, no matter their group membership. This is fairly simple to implement: add an Article type, a Query to retrieve all articles, and an author field:
type Article {
text: String
author: User
}
type Query {
allArticles: [Article]
}Also, because of the grouping, we have a group field for the users and a users for the Group:
type User {
group_unsafe: Group
}
type Group {
name: String
users: [User]
}Now there is a problem here. Any user can get all articles, move to their authors, then to the authors' groups, then list the users in those groups:
query MyQuery {
allArticles {
author {
group_unsafe {
name
users {
username
}
}
}
}
}The result is a list of both groups:
{
"data": {
"allArticles": [
{
"author": {
"group_unsafe": {
"name": "Group 1",
"users": [
{
"username": "admin1"
},
{
"username": "user1"
},
{
"username": "user3"
}
]
}
}
},
{
"author": {
"group_unsafe": {
"name": "Group 2",
"users": [
{
"username": "user2"
},
{
"username": "admin2"
}
]
}
}
}
]
}
}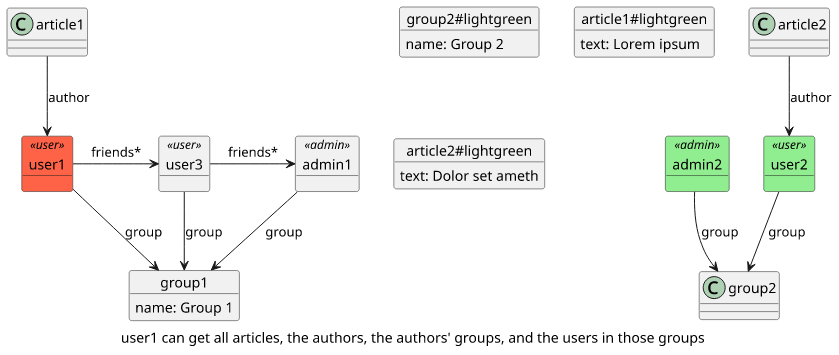
This is a good illustration to show what can happen if two seemingly innocuous features are combined. Because of this always make sure you consider what other objects are accessible in the graph.
How to solve this?
In this case, we can fix the User.group field by adding a restriction: only return the Group if it's the same as the caller's group. And for this, we'll
use the same mechanism as we've used for the allUsers.
First, query and stash the current user:
{
"version" : "2018-05-29",
"operation" : "GetItem",
"key" : {
"username": {"S": $util.toJson($ctx.identity.username)}
},
"consistentRead" : true
}#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
$util.qr($ctx.stash.put("user", $ctx.result))
{}Second, check that the requested group is the same:
#if($ctx.source.group != $ctx.stash.user.group)
#return
#else
{
"version" : "2018-05-29",
"operation" : "GetItem",
"key" : {
"id": {"S": $util.toJson($ctx.source.group)}
},
"consistentRead" : true
}
#endSince this resolver is to a field of a type (group for User), we have a source object ($ctx.source). The first part then compares the source
User's group with the stashed User's group and return null if they don't match.
The result is that everybody can get the author for an article, but can not move to its Group:
query MyQuery {
allArticles {
author {
group {
name
users {
username
}
}
}
}
}{
"data": {
"allArticles": [
{
"author": {
"group": {
"name": "Group 1",
"users": [
{
"username": "admin1"
},
{
"username": "user1"
},
{
"username": "user3"
}
]
}
}
},
{
"author": {
"group": null
}
}
]
}
}Conclusion
Access control in GraphQL is about what objects users can reach. In this article we've looked into how to secure the entry points to the object graph and how to restrict navigation between the objects. We've looked into how to define access in the schema, and how to implement controls in the resolvers.

