
Use the HTTP data source to interact with HTTP APIs directly from AppSync
How to send HTTP requests from AppSync resolvers


HTTP data source
The HTTP data source provides a way to send an HTTP request directly from AppSync. This is a versatile approach as most things on the Web offers an HTTP API. It provides a direct way of interacting with things like Google Sheets, OpenWeatherMap, or even sending messages to a Telegram bot, and a lot more. Even individual services in AWS provide HTTP-based APIs, those are what the AWS CLI, the SDK, Terraform, and other tools are using under the hood.
A data source is a "window" for AppSync to the external world, such as DynamoDB tables, Lambda functions, and, in our case, HTTP endpoints. It contains some configuration about how to reach the target service and provides a JSON-based API for the resolver to provide the parameters. When the resolver runs, the operation will be determined by the data source configuration while the input is coming from the resolver mapping template.
Of course, with a Lambda function you can send arbitrary HTTP requests. The advantage of using the HTTP data source instead is that in this case AppSync sends the request directly without invoking a Lambda first. This is better for simple cases.

Configuration
The data source needs only one thing: the domain of the endpoint. This is the first part of the request, and the rest will be filled by the resolver.
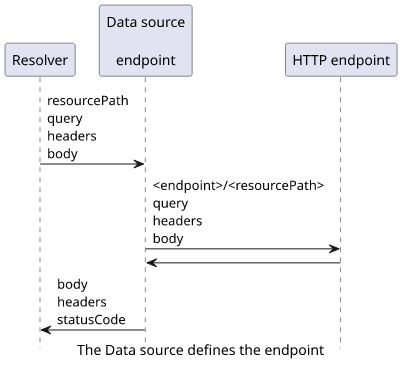
Fetching the latest XKCD
Let's see how to implement a simple resolver that returns the latest XKCD comic! There is an endpoint for that available at https://xkcd.com/info.0.json. So our resolver, combined with the data source, needs to send a GET request there and return the response body.
The GraphQL schema is simple, just return a JSON:
type Query {
latestXkcd: AWSJSON!
}The data source configuration needs the endpoint:
Then the resolver defines the path (resourcePath) and a required Content-Type header:
{
"version": "2018-05-29",
"method": "GET",
"params": {
"query": {},
"headers": {
"Content-Type" : "application/json"
},
},
"resourcePath": "/info.0.json"
}Then the response mapping template can return the response body:
#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
#if ($ctx.result.statusCode < 200 || $ctx.result.statusCode >= 300)
$util.error($ctx.result.body, "StatusCode$ctx.result.statusCode")
#end
$ctx.result.bodyTo test it, let's send a GraphQL request:
query MyQuery {
latestXkcd
}This returns a JSON:
{
"data": {
"latestXkcd": "{\"month\":\"7\",\"num\":2645,\"link\":\"\",\"year\":\"2022\",\"news\":\"\",\"safe_title\":\"The Best Camera\",\"transcript\":\"\",\"alt\":\"The best camera is the one at L2.\",\"img\":\"https://imgs.xkcd.com/comics/the_best_camera.png\",\"title\":\"The Best Camera\",\"day\":\"13\"}"
}
}Error handling
The result object has the response headers, the status code, and the body. Note that $ctx.error is only defined if there was a problem with the HTTP
request, but it will be undefined if the endpoint returned a non-success response.
To also throw an error when the status code is not in the 2XX range, add an extra check:
#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
#if ($ctx.result.statusCode < 200 || $ctx.result.statusCode >= 300)
$util.error($ctx.result.body, "StatusCode$ctx.result.statusCode")
#endThis throws an error corresponding to the error code:
{
"data": null,
"errors": [
{
"path": [
"latestXkcd"
],
"data": null,
"errorType": "StatusCode404",
"errorInfo": null,
"locations": [
{
"line": 2,
"column": 3,
"sourceName": null
}
],
"message": "<html>\r\n<head><title>404 Not Found</title></head>\r\n<body bgcolor=\"white\">\r\n<center><h1>404 Not Found</h1></center>\r\n<hr><center>nginx</center>\r\n</body>\r\n</html>"
}
]
}Fetching the top Reddit posts
Let's see a more complex example where the GraphQL field has an argument and the result object is more strongly typed than the AWSJSON!
Here, we'll use Reddit's public API to fetch the top 3 posts for a subreddit:
type Post {
title: String
ups: Int
downs: Int
url: String
author: String
}
type Query {
topPosts(topic: String!): [Post!]!
}The data source endpoint is https://www.reddit.com/.
The request mapping template:
{
"version": "2018-05-29",
"method": "GET",
"params": {
"query": {"limit": "3"},
"headers": {
"Content-Type" : "application/json"
},
},
"resourcePath": "/r/$ctx.args.topic/top.json"
}This sends a request to /r/<topic>/top.json and adds a limit=3 query parameter and a Content-Type.
Reddit's response is a big object with lists, so we need to do some processing to get a response in the required (Post) format:
#if ($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
#if ($ctx.result.statusCode < 200 || $ctx.result.statusCode >= 300)
$util.error($ctx.result.body, "StatusCode$ctx.result.statusCode")
#end
#set($result = [])
#foreach($item in $util.parseJson($ctx.result.body).data.children)
$util.qr($result.add($item.data))
#end
$util.toJson($result)The $util.parseJson($ctx.result.body) is a generic structure to get the response body as a JSON. In this case, the body has a data and that has a
children property which is an array.
Then the #set($result = []) and the $util.qr($result.add(...)) is another common pattern that builds a result list.
Finally, the #foreach iterates over the elements in a list.
Let's test the resolver:
query MyQuery {
topPosts(topic: "programming") {
author
downs
title
ups
url
}
}The result is a JSON in conformance with the GraphQL schema:
{
"data": {
"topPosts": [
{
"author": "kisamoto",
"downs": 0,
"title": "Poll: Do you expect/want to see salary information in a job ad?",
"ups": 1707,
"url": "https://news.ycombinator.com/item?id=32095140"
},
{
"author": "dawgyo",
"downs": 0,
"title": "I built a Chrome extension to directly save jobs from LinkedIn and Indeed to Google Sheets so you can easily organize and keep track of your job applications",
"ups": 168,
"url": "https://chrome.google.com/webstore/detail/resumary-oneclick-save-jo/mkjedhephckpdnpadogmilejdbgbbdfm"
},
{
"author": "agbell",
"downs": 0,
"title": "The Slow March of Progress in Programming Language Tooling",
"ups": 130,
"url": "https://earthly.dev/blog/programming-language-improvements/"
}
]
}
}Debugging requests
Unfortunately, AppSync provides little insight into what goes on the wire. Because of this, when there is a problem, it's hard to pinpoint what exactly has gone wrong.

To see the parts of the HTTP request going out from AppSync we can use a debug service. In this article, we'll use webhook.site.
To use it, open the page and note the unique token:
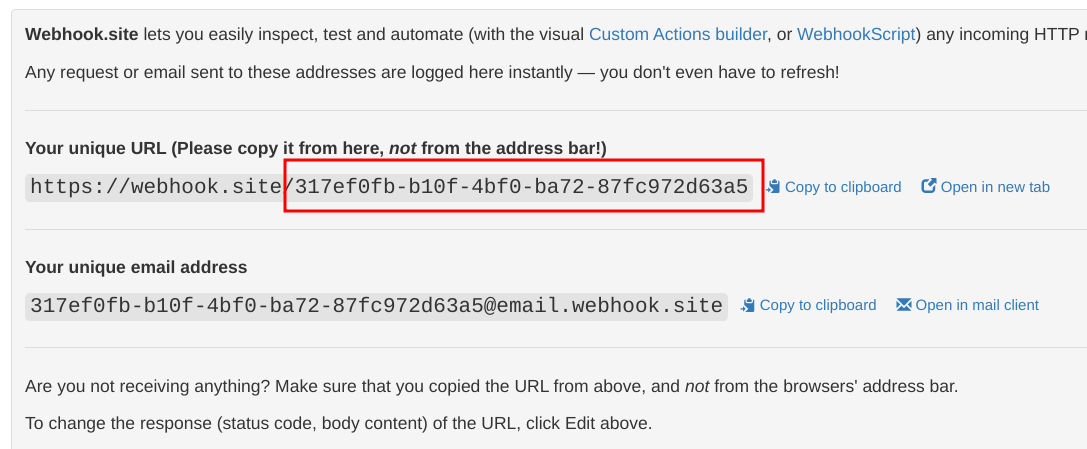
The debug endpoint is the concatenation of the base URL (https://webhook.site) and this token. The first part maps to the data source endpoint while the
latter comes from the resolver.
In the resolver, let's add a couple of things to the request so that we can inspect them on the other end!
{
"version": "2018-05-29",
"method": "GET",
"params": {
"query": {
"queryvalue": "testvalue"
},
"headers": {
"Content-Type" : "application/json",
"testheader" : "value"
},
"body": "example body"
},
"resourcePath": "/$ctx.args.id"
}The resourcePath is the token, so AppSync sends the request to the correct debug endpoint.
Calling this GraphQL query shows that AppSync indeed called this endpoint:
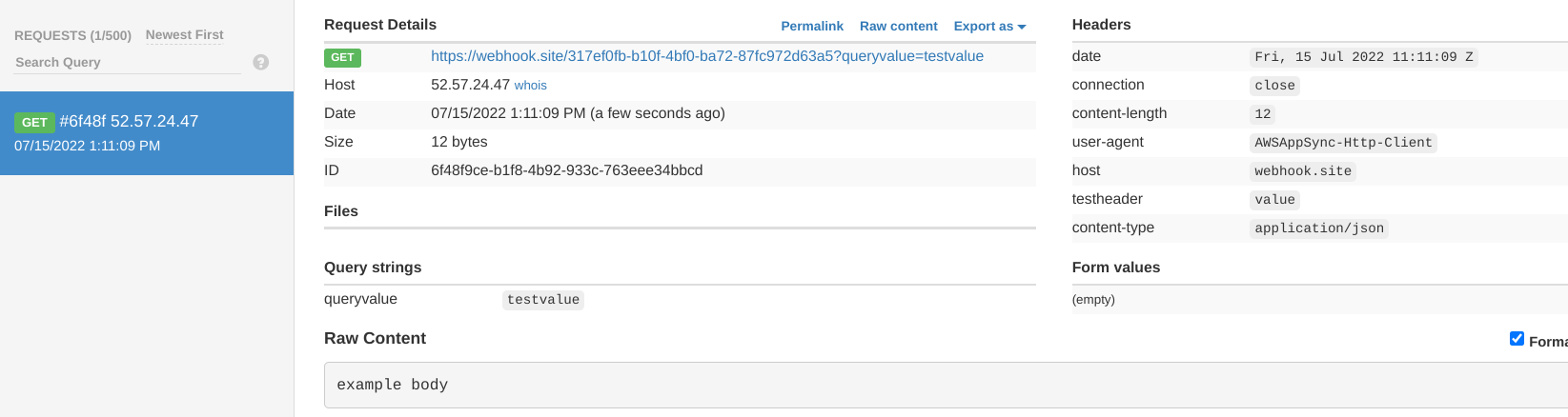
The request has very little extra information besides what the resolver set: AppSync only adds a user-agent header and a few others for connection
management.
AWS-signed requests
There is a "hidden" feature of the HTTP data source: it can sign the requests using the AWS signing algorithm with the keys of the role configured for it. This is hidden as it's not visible on the UI, and can be set only via the API:
This is a Terraform config that enables this feature:
resource "aws_appsync_datasource" "webhook_signed" {
api_id = aws_appsync_graphql_api.appsync.id
name = "webhook_signed"
service_role_arn = aws_iam_role.appsync.arn
type = "HTTP"
http_config {
endpoint = "https://webhook.site"
authorization_config {
authorization_type = "AWS_IAM"
aws_iam_config {
signing_region = "us-west-2"
signing_service_name = "sns"
}
}
}
}The values for the authorization_config and the authorization_type are fixed, so there are only 2 variables here: the signing_region and the
signing_service_name. Both are for the called service, so if you want to call SNS in us-west-2 then the service name is sns and the region is
us-west-2.
Since the AWS signing algorithm works for non-AWS services too, there is nothing stopping us from sending a signed request to the debug endpoint and see what changes:
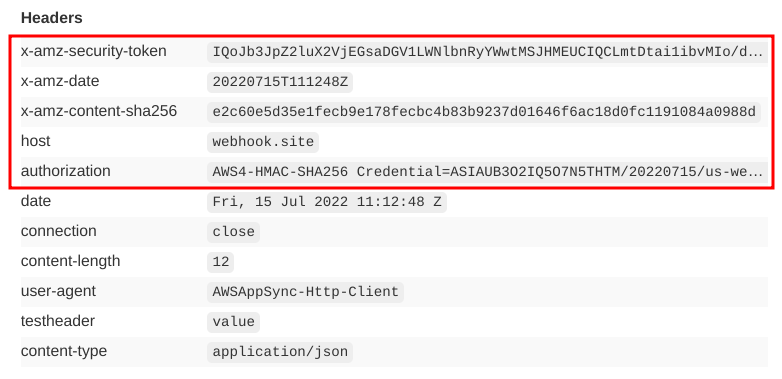
These extra headers are defined in the algorithm's docs.
Why is this feature great?
Signed requests are controlled by IAM policies, which means the role configured for the data source can have access to some AWS service to do some specific actions. This provides an easy way for giving access to resources in AWS accounts using the same process as, for example, the Lambda execution role, the AWS CLI, and countless other services. You can use the rich feature set of IAM policies to control access, and all the cryptography is handled for you.



