
How authentication and authorization work in AWS
The mechanism underpinning all AWS API operations


Authentication and authorization are the two primary components of access control. When a service is not available to the public (i.e. not allowing anonymous access) then it needs to implement a way to identify the user who is doing the request and use a set of rules to allow or deny it.
In this article, we'll look into how authentication and authorization are implemented in AWS. This helps to understand how users, roles, and policies work.

What are authentication and authorization
Let's first define what these two terms mean. From the perspective of the user, they seem more of a complication than a useful thing, such as why AWS has 5 types of policies. But they are essential building blocks for a service.
An online web service is essentially an API that handles requests. In the handler, the API needs to answer two questions:
- Who is making this request? (authentication)
- Is the user allowed to do this operation? (authorization)
A simplified version would look like this:
const http = require("http");
const server = http.createServer((req, res) => {
const user = getUser(req);
if (hasPermissions(user, req)) {
// process request
}else {
res.statusCode = 403;
res.end();
}
});
server.listen(8080);Here, the getUser does some magic and returns who is making the request. Then the hasPermissions does something internally and returns a true/false
decision.
Authentication
In everyday language we use "authentication" for the sum of two different things:
- Identification: who is the user
- Authentication: prove it
For example, when you log into Gmail, you need to provide an email address (identification) and a password (authentication). Similarly, logging in to AWS requires an account ID and a username (identification) and a password, and optionally an MFA token (authentication).
AWS is a bit unique in how it implements its APIs. There are a few exceptions but the rule of thumb is that everything is going through its public APIs, even actions done on the Management Console sends requests to them. Because of this, what you can configure using a browser can also be automated. Also, all AWS services use the same authentication and authorization mechanism.
Access Key ID and Secret Access Key
When you make a request to an AWS API you need to have two things: an Access Key ID and a Secret Access Key. When you have an IAM user you can create long-term keys:
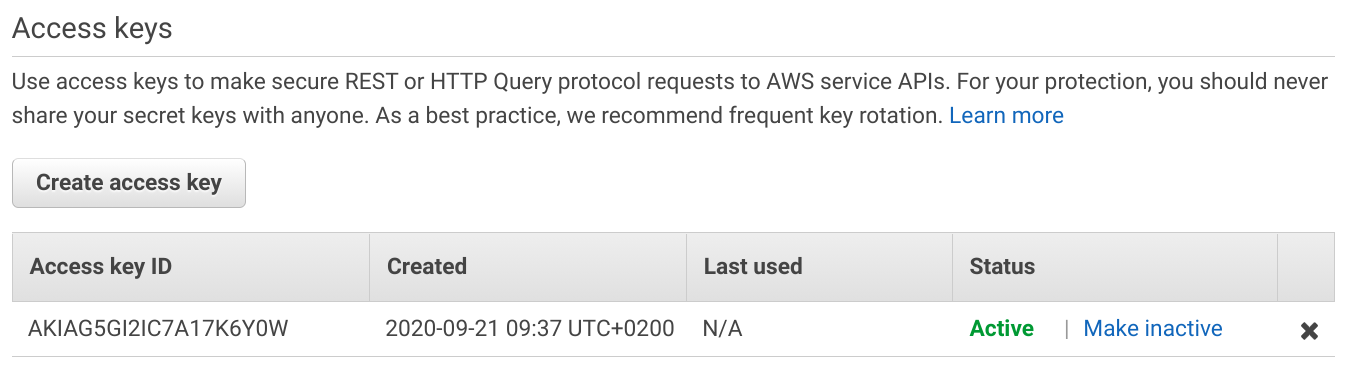

And when you use roles, you need to assume them to get a valid set of credentials:
aws sts assume-role --role-arn <role arn> --role-session-name test_session{
"Credentials": {
"AccessKeyId": "ASIA...",
"SecretAccessKey": "6mu...",
"SessionToken": "IQoJb3JpZ2luX2V...",
"Expiration": "2020-09-30T08:14:44+00:00"
},
"AssumedRoleUser": {
"AssumedRoleId": "AROA...:test_session",
"Arn": "arn:aws:sts::<accountid>:assumed-role/test_role/test_session"
}
}
The Access Key ID identifies the user, the role, or the account if it's for the root user. It is part of the request, in plain text.
The Secret Access Key works like a password, but with some hardened security. It is tied to an Access Key ID and AWS generates them in pairs. It also stores them in pairs, so that the API can retrieve the matching one for the Access Key ID.
When an SDK, the Management Console, or some other tool makes a request, it uses the Secret Access Key to calculate a signature. AWS defines a process to convert the request to a canonical format that's primary purpose is to eliminate ambiguities (for example, define the order of the query parameters). Then it uses an HMAC (hash-based message authentication code) that gets the canonical request and the secret and generates a signature. Then this signature is attached to the request.
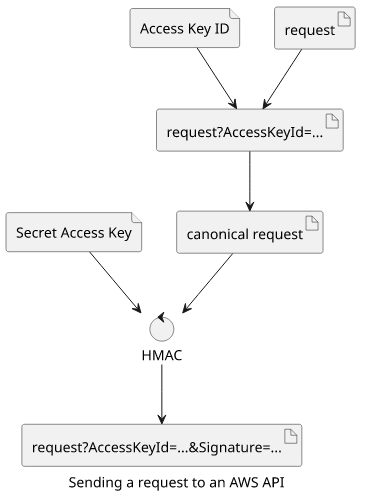
On the service-side, AWS needs to extract the Access Key ID from the request, fetch the matching Secret Access Key from its records, convert the request to the canonical format, then calculate the signature, and finally, check if the calculated signature matches the one in the request:
const http = require("http");
const server = http.createServer((req, res) => {
// get Access Key ID from the request
const accessKeyId = getAccessKeyId(req);
// get the stored secret
const secretAccessKey = getSecretForAccessKeyId(accessKeyId);
// get signature from request
const signatureInRequest = getSignature(req);
// calculate signature using the stored key
const calculatedSignature = calculateSignature(secretAccessKey, req);
const signatureMatch = signatureInRequest === calculatedSignature;
if (signatureMatch) {
if (hasPermissions(req)) {
// process request
}else {
res.statusCode = 403;
res.end();
}
}else {
res.statusCode = 400;
res.end();
}
});
server.listen(8080);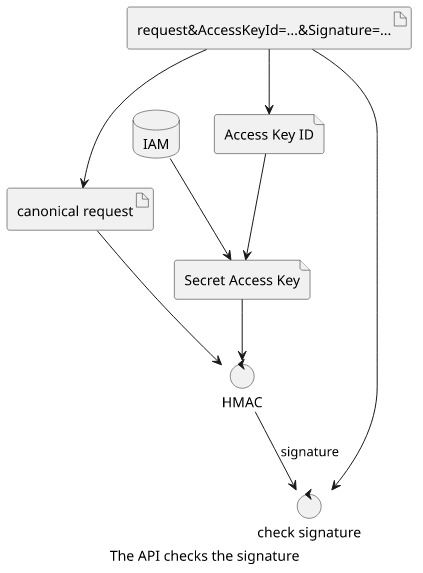
The advantage of this more complicated process is that the Secret Access Key is not recoverable from the request. In a more widely used API Key approach, the
key is sent in an HTTP header (Authorization: Bearer <token>) and if somebody can intercept the request then they can send other requests with that key.
With AWS's implementation, the attacker can only send the same request but won't be able to impersonate the user.
Authorization
Authorization is to decide whether the identity is allowed to do the action or not. While authentication is usually implemented similarly in services (some sort of user is usually present in all services), how authorization works vary widely.
Authorization is a process that gets who is making the request (the user or other identity), how the request was made (time, IP address), the operation (what is being done on what), and what configuration exists in the account (policies), and it provides a binary decision.
In our dummy cloud implementation, it is this part:
if (hasPermissions(req)) {
// process request
}else {
res.statusCode = 403;
res.end();
}In AWS, authorization is based on policies. They define what an identity can do (identity-based policies) or who can access a resource (resource-based policies). There are 5 policy types in AWS and more than one can affect a single request.
The system that defines how these policies work is the policy evaluation logic. This gets the request and the policies defined in the AWS account and returns the binary decision.
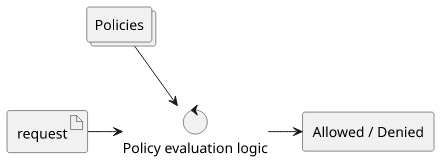

Conclusion
Authentication and authorization are present no matter what you do in AWS. If you want to upload objects to an S3 bucket, you need a user or a role and the necessary policies. If you deploy a serverless backend as a Lambda function, the function needs to assume an identity in the account and have the necessary permissions to access the resources it needs. Understanding how these mechanisms work helps when you encounter errors.

