
How to use RDS as a Data Source for AppSync
Use an AWS-managed relational database with GraphQL


SQL-based resolvers in AppSync
RDS is the relational database managed by AWS, boasting a ton of features such as multi-AZ deployment, automatic failover, backups, and monitoring. If you need an SQL-based database and you are running your apps in the AWS cloud, that is usually the first choice.
AppSync is a managed GraphQL service that allows running a graph-based API without capacity planning. You need a schema then resolvers for each field, and each of these resolvers interface with a Data Source. Then these Data Sources make it possible for the API to interact with other services, such as Lambda functions, DynamoDB tables, and RDS databases.
In this article, we'll focus on that last point: how to send SQL queries that read and change data in an RDS database from an AppSync resolver.

RDS setup
AppSync supports only the RDS Data API and not the traditional connection-based way of sending queries. This means you need to use an engine that supports that,
such as the 5.7.mysql_aurora.2.07.1. Also, the Aurora serverless v2 is not available for AppSync (yet) as that does not support the Data API.
The Data API requires the database password to be managed by Secrets Manager. This adds some extra costs, as secrets come with a $0.4 per month fixed and per-call variable price tag. On the other hand, this setup provides a simpler and more secure architecture: nowhere in AppSync you'll need to input the password, only the ARN of the secret. Moreover, it enables seamless rotation of passwords.

In Terraform:
resource "aws_secretsmanager_secret" "db-pass" {
name = "db-pass-${random_id.id.hex}"
}
resource "aws_secretsmanager_secret_version" "db-pass-val" {
secret_id = aws_secretsmanager_secret.db-pass.id
secret_string = jsonencode(
{
username = aws_rds_cluster.cluster.master_username
password = aws_rds_cluster.cluster.master_password
engine = "mysql"
host = aws_rds_cluster.cluster.endpoint
}
)
}
resource "aws_rds_cluster" "cluster" {
engine = "aurora-mysql"
engine_version = "5.7.mysql_aurora.2.07.1"
engine_mode = "serverless"
database_name = "mydb"
master_username = "admin"
master_password = random_password.db_master_pass.result
enable_http_endpoint = true
skip_final_snapshot = true
scaling_configuration {
min_capacity = 1
}
lifecycle {
# RDS auto-upgrades the version
# so this tells Terraform not to downgrade it the next apply
ignore_changes = [
engine_version,
]
}
}Data Source configuration
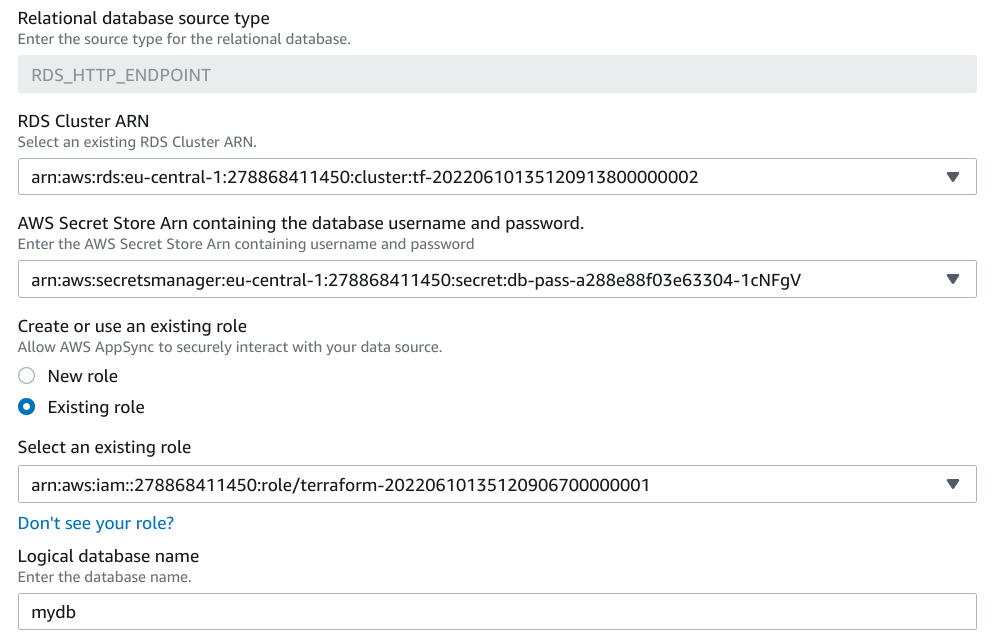
Next, you need to add a Data Source with the configuration of how AppSync can reach the database. This requires four things.
As usual in AWS, AppSync depend on IAM Roles to gain access to resources in the account.

In this case, it needs 2 permissions: one to read the current password from Secrets Manager, and the other to execute statements against the RDS cluster:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "rds-data:ExecuteStatement",
"Resource": "arn:aws:rds:..."
},
{
"Effect": "Allow",
"Action": "secretsmanager:GetSecretValue",
"Resource": "arn:aws:secretsmanager:..."
}
]
}Then the Data Source needs some information about how to reach the database:
- The cluster ARN (even though it's called
db_cluster_identifier) - The Secret ARN
- And the database name
resource "aws_appsync_datasource" "rds" {
api_id = aws_appsync_graphql_api.appsync.id
name = "rds"
service_role_arn = aws_iam_role.appsync.arn
type = "RELATIONAL_DATABASE"
relational_database_config {
http_endpoint_config {
db_cluster_identifier = aws_rds_cluster.cluster.arn
aws_secret_store_arn = aws_secretsmanager_secret.db-pass.arn
database_name = aws_rds_cluster.cluster.database_name
}
}
}
Data model
In this example, we'll have 2 tables: User and UserGroup. Both have id and name columns, and Users can belong to UserGroups.
In GraphQL:
type User {
id: ID!
name: String!
group: Group!
}
type Group {
id: ID!
name: String!
users: [User!]!
}
type Query {
groupById(id: String!): Group
}
type Mutation {
addGroup(name: String!): Group!
addUser(name: String!, groupId: ID!): User!
}
schema {
query: Query
mutation: Mutation
}And the DDL queries:
CREATE TABLE IF NOT EXISTS User(
id varchar(255) PRIMARY KEY,
name TEXT,
groupId varchar(255)
);
CREATE TABLE IF NOT EXISTS UserGroup(
id varchar(255) PRIMARY KEY,
name TEXT
);
ALTER TABLE User ADD CONSTRAINT fk_group_id FOREIGN KEY (groupId) REFERENCES UserGroup(id);Resolvers
Update: AppSync now supports SQL tagged templates that are a direct replacement to the old resolvers and are superior to them. See this article to learn how to use them.

With the Data Source configured, the last part is to write the resolvers that use the RDS cluster. We'll look into the two basic operations: reading and writing data.
Reading data
To implement the groupById query, we need a request mapping template:
{
"version": "2018-05-29",
"statements": [
"SELECT * FROM UserGroup WHERE id = :ID"
],
"variableMap": {
":ID": $util.toJson($ctx.args.id.replace("'", "''").replace("\", "\\"))
}
}The first thing to notice here is that the statements item is an array, which suggests AppSync can execute more than one. This is true, but the limit is
rather low: it's only 2. This is to cover one specific use case: when the first statement modifies data and the second one queries the database so that
the Mutation can return the type defined in the schema.
I couldn't find information whether the two statements are running in a transaction or not, but it's safer to assume they are not. In GraphQL the resolvers are run independently and without guarantees that all parts see the same state.
Second, RDS resolvers support variables for easier and safer parametric queries. In the above example, the :ID is referenced in the statement and
gets its value in the variableMap. It is a best practice to always use this, not only because of security but also as building strings is challenging with
VTL.
Update: It turns out the variableMap does not do any sanitization! See this and
this tickets and this
page. This is a massive oversight from AWS that probably
affects a lot of APIs out there. The .replace("'", "''").replace("\", "\\") seems to be enough to catch bad cases.
Response
The response from the RDS Data Source is a rather verbose JSON:
{
"sqlStatementResults": [
{
"columnMetadata": [
{
"...",
"name": "id",
"...",
"typeName": "VARCHAR",
"..."
},
{
"...",
"name": "name",
"...",
"tableName": "UserGroup",
"..."
}
],
"numberOfRecordsUpdated": 0,
"records": [
[
{
"stringValue": "group1"
},
{
"stringValue": "Group 1"
}
]
]
}
]
}Fortunately, AWS provides a built-in function that transforms this to an easier-to-use format: $utils.rds.toJsonObject($ctx.result). This return a 2D
array, where the first dimension is the SQL statement ([0] or [1]), and the second one is the returned element.
So, to return the first record for the first query and return null if none was returned:
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
#set($results=$utils.rds.toJsonObject($ctx.result)[0])
#if($results.isEmpty())
null
#else
$utils.toJson($results[0])
#endThis works as the $results is a Java List with an isEmpty function.
Inserting data
Next, let's implement the addUser Mutation! This gets the name and the groupId arguments and returns a User object.
Here, we can use two SQL statements:
#set($id=$utils.autoId())
{
"version": "2018-05-29",
"statements": [
"INSERT INTO User VALUES (:ID, :NAME, :GROUP_ID)",
"SELECT * FROM User WHERE id = :ID"
],
"variableMap": {
":ID": $util.toJson($id.replace("'", "''").replace("\", "\\")),
":NAME": $util.toJson($ctx.args.name.replace("'", "''").replace("\", "\\")),
":GROUP_ID": $util.toJson($ctx.args.groupId..replace("'", "''").replace("\", "\\"))
}
}The $id is an auto-generated identifier that AppSync generates in the first line. Then both statements can use it to identify the item.
This structure is the usual approach for implementing insertion:
- Generate the ID in the resolver
- Insert the row in the first statement
- Then retrieve in the second
Response mapping template
In the response template, get the first result of the second query:
#if($ctx.error)
$util.error($ctx.error.message, $ctx.error.type)
#end
#set($results=$utils.rds.toJsonObject($ctx.result)[1])
#if($results.isEmpty())
null
#else
$utils.toJson($results[0])
#end
