
Efficient filtering in DynamoDB
How to structure a table to allow getting only the matching elements


Filter expressions
DynamoDB provides support for filter expressions that you can use with operations that return a list of items. As a starting point, this query returns all items
in the table where the group_id is group1 (users in Group 1):
aws dynamodb query \
--table-name $TABLE \
--index-name groupId \
--key-condition-expression "#groupId = :groupId" \
--expression-attribute-names '{"#groupId":"group_id"}' \
--expression-attribute-values '{":groupId":{"S":"group1"}}' \The result is a long JSON object, but it can be summed up with this table:
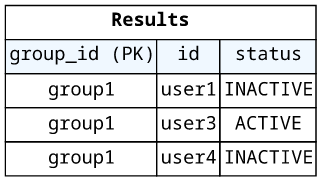
To get only the ACTIVE users, we can add a filter expression that returns only matching elements.
aws dynamodb query \
--table-name $TABLE \
--index-name groupId \
--key-condition-expression "#groupId = :groupId" \
--expression-attribute-names '{"#groupId":"group_id", "#status": "status"}' \
--expression-attribute-values '{":groupId":{"S":"group1"}, ":status": {"S": "ACTIVE"}}' \
--filter-expression "#status = :status"This returns only the active user:

This is exactly the result the query asked for, but it's worth looking into how it works to see what is the problem with this. One clue is in the result JSON:
{
"Items": [
"..."
],
"Count": 1,
"ScannedCount": 3,
"ConsumedCapacity": null
}Here, the ScannedCount shows that DynamoDB read 3 items, then it returned only one (the active user). Filter expressions work by reading all queried items
and dropping non-conforming ones. This means they consume almost the same cost (save for the bandwidth) as non-filtered queries.

Problems with filter expressions
The behavior of filter expressions can be problematic especially in two cases.
First, when there is a large number of dropped items before non-dropped ones. In the above example, if there are a lot of inactive users and they come first according to the ordering of the table/index. In this case, when a client wants to show some active users they need to get several pages of zero results before getting the first items to show. This makes it slow and expensive to use the database and especially when combined with a limit parameter it can have surprising properties.

The second case is when the client needs to get all matching items so it will automatically fetch all the pages. For example, an admin dashboard might want to show the number of active users and does so by fetching all of them. While there are better ways to implement this, they require support from the table design. By fetching all items the client will necessarily paginate over all non-matching items too, so as the number of inactive users go up so does the number of queries needed.

Filter expressions are useful when clients only need to get a limited amount of matching elements (such as a page) and dropped items are relatively rare and evenly distributed. If these conditions don't stand then filtering can quickly become a problem.
Efficient filtering
DynamoDB provides a way to implement fetching only the matching elements but how it works is unintuitive at first. In the first query without the filter
expression, DynamoDB only returned items that match the key condition expression and did that without reading all other items first (the ScannedCount was
still 3). So, if we could include the field in the filter expression in the key expression, then DynamoDB could fetch only the needed items.
Since an item can only have one partition key, we need to do a trick here: store both values in one field using string concatenation. The usual separator is
#, so that would make a group_id#status field, with both the group ID and the status:
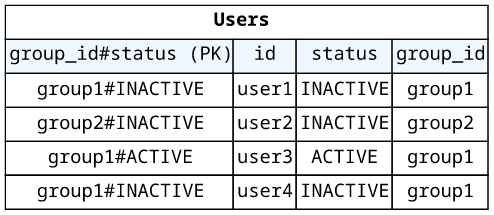
This is usually done on an index rather than a table, but there is no difference here for the query.
With this structure, it is possible to get users both by group and status:
aws dynamodb query \
--table-name $TABLE \
--index-name groupIdStatus \
--key-condition-expression "#groupIdStatus = :groupIdStatus" \
--expression-attribute-names '{"#groupIdStatus":"group_id#status"}' \
--expression-attribute-values '{":groupIdStatus":{"S":"group1#ACTIVE"}}'The result contains only one item, and the ScannedCount shows only 1 item was read:
{
"Items": [
{
"..."
}
],
"Count": 1,
"ScannedCount": 1,
"ConsumedCapacity": null
}Optional filters
Note that when the table or the index uses this concatenated partition key then it is no longer possible to get all users regardless of status. If you know all the possible values (such as in this case ACTIVE and INACTIVE) then you can send multiple requests, one with each possible value, and merge the results. But this approach won't work for free-text fields.
To allow filtering but also allow no filters, add a second index without the filtered field. Then send the request to the correct index depending on whether the value is provided or not.
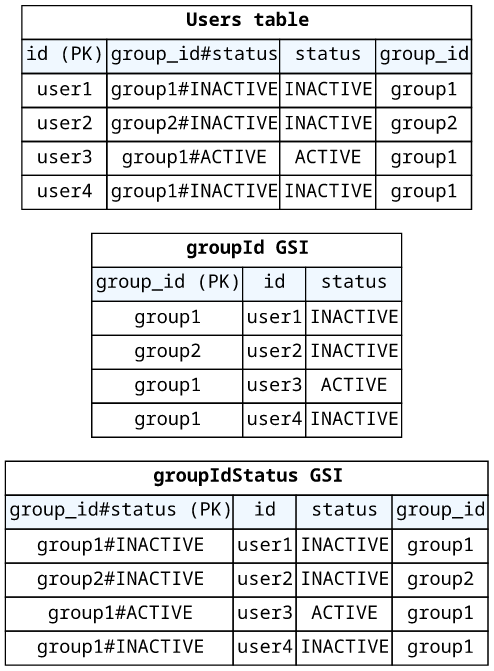
More than one filtering property
Using the same technique you can define multiple filtering fields. For example, if users in the database also have a VERIFIED/PENDING state, then simply concatenate that into the partition key.
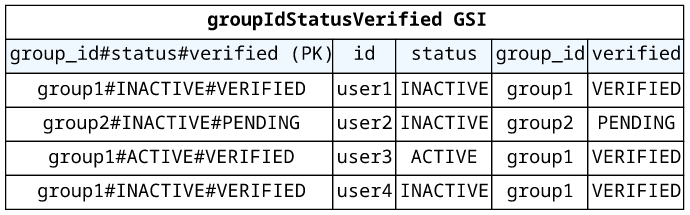
Note that as you add fields to the partition key it requires more and more indices to make fields optional. Because of this, it is better to use a dedicated search solution, such as OpenSearch. As you can see, DynamoDB is not the best solution to provide ad-hoc searching and filtering of data.
Partition key or sort key?
An alternative approach is to add the filtering to the sort key instead of the partition key. This works by utilizing the begins_with key condition expression to match the beginning of the sort key.
For example, the group_id can be the partition key and the status#id the sort key:
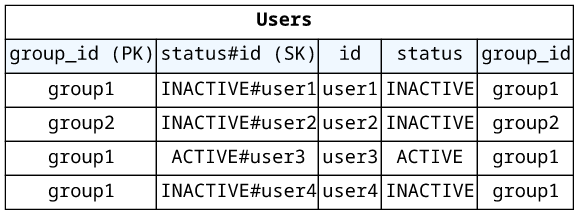
The order of the parts in the sort key is important as you can only match from the beginning. Here, you can define a begins_with(#statusId, :statusId)
where the :statusId is ACTIVE#. This returns only the active users and you can also easily query all users: just remove the condition.
This approach works especially well for hierarchical filters, such as year-month-day or country-city-street. Depending on how granular you want to go, you can
define some or all parts. Moreover, sort keys allow range queries when the property allows it. For example, the #date >= "2022-06-01" AND #date < "2022-06-08" queries the first 7 days of June.
I usually prefer to include filtering in the partition key unless there is a clear advantage to do it in the sort key. This way, the partitions are better distributed, which is a good database design.
Conclusion
DynamoDB filter expressions offer an easy way to define a condition for the returned items but it uses a very inefficient algorithm and can easily make queries slow and expensive. To implement efficient filtering, you can add the filtered values to the key of the items either in the table itself or in a separate index. This allows the query to return only the matched elements without reading and discarding results.

