
Testing for undesired log output
My rant about the importance of the stuff in the logs.


Rethinking log levels and contents
Working on projects that went live a long time ago and have tons of features, unsuspecting developers often have the opportunity to encounter some uncertainty and discomfort around the log files. Wild things take root in the dark, hiding in the shadows of the towering piles of data. Sometimes one have to tweak some configuration files or the environment to make them disappear, sometimes the log message is actually indicate an error or an unhandled edge case. But in many cases these error messages are not fatal, the application still works as expected, at least it's not interrupting the current task at hand, so there is no immediately detectable feature loss. After a while developers accommodate to these error messages, and they become an expected indicator that the application is alive and running. Usually no one has the time to investigate them, at least until the whole system goes haywire, and turns out these ignored messages were the silent screams that supposed to inform us about broken invariants and glitches. With additional features already built around them, the causes are a lot harder to eliminate.
This problem is usually overlooked and neither do I want to make a big deal out of it, but I think there is a cheap and easy solution for this.
Besides, from an operations perspective, having the right contents in the generated log files is an important feature, but this is not what I'd like to focus on this post.
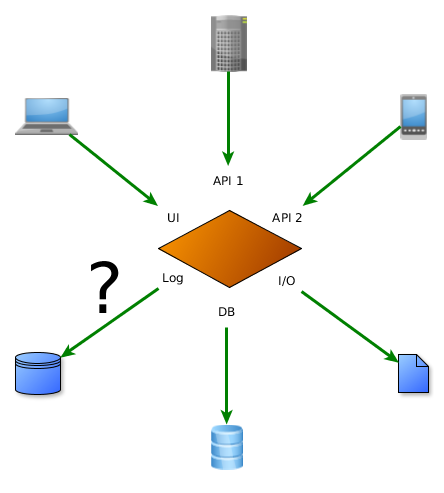
Feature tests exercise UI, API and data layers, but who cares about the logs?
My suggestion
Probably we can't solve every mysterious bug by cleaning the logs, but I think we can preserve some of our sanity if we take logging more rigorously in the automated integration testing environment.
During the test of normal operation - and while executing feature tests - there should be no unexpected and ignored errors as they indicate something went really wrong. Even if the test case in question passed, the hidden error might cause problems later on. To enforce this, we have to break tests if certain log events happen during the execution - fatal, error, ones with attached exceptions... - depending on the attitude or policy regarding the logs. For example, if the difference between an error and a warning is that the former one means to call the system administrator (possibly in the middle of the night), then it should break the tests.
Some testing scenarios and legacy applications might require opt-out switches based on event type or location, because certain test cases might produce expected errors, and there might be events that are inconvenient or not possible to handle differently. These switches also provide an opportunity to gradually improve the expectations, starting only with a subset.
Test level granularity
One approach is check the log events after every test scenario. For this, we have to create and register a custom logger implementation that stores every log event and provides methods for querying and clearing the recorded log data.
With log4j, we might implement an Appender.
package hu.advancedweb;
import java.util.ArrayList;
import java.util.List;
import org.apache.log4j.AppenderSkeleton;
import org.apache.log4j.spi.LoggingEvent;
public class IntegrationTestAppender extends AppenderSkeleton {
private List<LoggingEvent> events = new ArrayList<LoggingEvent>();
@Override
protected void append(LoggingEvent event) {
events.add(event);
}
public List<LoggingEvent> getEvents() {
return new ArrayList<LoggingEvent>(events);
}
public void clear() {
events.clear();
}
public void close() {
// Do nothing.
}
public boolean requiresLayout() {
return false;
}
}And to use it in a JUnit test as follows:
private static IntegrationTestAppender unexpectedEventAppender;
@BeforeClass
public static void initAppender() {
unexpectedEventAppender = new IntegrationTestAppender();
unexpectedEventAppender.setThreshold(Level.ERROR);
Logger.getRootLogger().addAppender(unexpectedEventAppender);
// or configure appenders via log4j.properties
}
@Before
public void clearEventLog() {
unexpectedEventAppender.clear();
}
@After
public void assertNoUnexpectedEvents() {
assertThat("Unexpected events", unexpectedEventAppender.getEvents(), hasSize(0));
// In addition, when the assertion fails it might be a good idea to print
// the events that failed the test.
}
@Test
public void someTest() {...}With multiple appenders and custom assertions many expectations can be expressed.
Suite level granularity
The previous method can be unreliable when things can happen in parallel. If a background service generates undesired events, it's not deterministic which tests will fail. This problem can be avoided, if it's enough that one dedicated test at the very end of the test suite informs us to check the log files when something goes wrong. I think test level precision for this kind of checks is usually not necessary.
In this case special care has to be taken to run this dedicated test after every other test. This can be done easily with Maven Surefire or Failsafe plugins:
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
<configuration>
<properties>
<property>
<name>listener</name>
<value>hu.advancedweb.LogEventListener</value>
</property>
</properties>
</configuration>
</plugin>The implementation of the RunListener might be as follows:
package hu.advancedweb;
import static org.hamcrest.MatcherAssert.assertThat;
import static org.hamcrest.Matchers.hasSize;
import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.junit.runner.Description;
import org.junit.runner.Result;
import org.junit.runner.notification.RunListener;
public class LogEventListener extends RunListener {
private IntegrationTestAppender unexpectedEventAppender;
@Override
public void testRunStarted(Description description) throws Exception {
unexpectedEventAppender = new IntegrationTestAppender();
unexpectedEventAppender.setThreshold(Level.ERROR);
Logger.getRootLogger().addAppender(unexpectedEventAppender);
}
@Override
public void testRunFinished(Result result) throws Exception {
assertThat("Unexpected events, check the log files!",
unexpectedEventAppender.getEvents(), hasSize(0));
}
}Testing separate process can be challenging, because some transport mechanism is needed to transfer log events from the system under test to the test application. This can be achieved with a simple file logger dedicated to log undesired events so the test can check if the log file exists or it's size growth during the execution. Checking logs once at the end of the test suite seems more easily achievable.
package hu.advancedweb;
import static org.hamcrest.MatcherAssert.assertThat;
import static org.hamcrest.Matchers.equalTo;
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import org.junit.runner.Description;
import org.junit.runner.Result;
import org.junit.runner.notification.RunListener;
public class LogEventListener extends RunListener {
private static String ERROR_LOG_PATH = "target/error.log";
private long initialErrorLogSize;
@Override
public void testRunStarted(Description description) throws Exception {
// If the SUT is started before the test execution
// then startup events can not be detected.
initialErrorLogSize = getErrorLogSize();
}
@Override
public void testRunFinished(Result result) throws Exception {
assertThat("Unexpected events, check the log files!",
getErrorLogSize(), equalTo(initialErrorLogSize));
}
private long getErrorLogSize() throws IOException {
Path path = Paths.get(ERROR_LOG_PATH);
if (Files.exists(path)) {
return Files.size(path);
} else {
return 0; // no log file, so no unexpected events
}
}
}Final thoughts
Checking undesired log events might cause some trouble when introduced to a mature application, but it can provide early detection of bugs and random behavior.
What do you think, is it worth paying attention to?
