
Efficient SQLite backup on Android
This is a post about backing up the SQLite database on Android

Background
In a previous article we've seen that the Backup Manager on Android can be a viable option for automagically backing up data. Although it is a bit of a black box, it is easy to use and should meet most needs. The platform offers helper classes for handling Shared Preferences and files, but there is no out of the box support for data stored in the SQLite database. In this post, I'll cover an efficient way to back up and restore data, and I'll also provide some timing and size measurements.

The database schema
Let's use a simple database schema! Basically there are Locations that can contain zero or more Stuffs and each Locations and Stuff has a name:
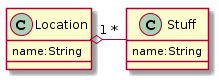
It is a simple schema, but it provides a variable amount of entities and also a relation between them.
The backup architecture
The main idea behind the backup is simple: We'll use a Cursor to fetch all the entities from the database one by one, convert them to JSON by a streaming architecture using GSON and finally GZIP the whole stream. Except the last step, the whole process is streaming, so it does not require a proportional amount of RAM to the number of entities. Only the GZIPed data must fit in the memory, but we'll see that it won't be a problem either (also, as the Backup Manager has a practical limit of 2MB, producing larger dump would make the saving problematic).
Backup implementation
First, let's define a helper method. I needed to iterate over Cursors, and this introduced bloat and reduced readability. So, use this method to simplify this:
public static void iterateOverCursor(Cursor cursor,Function<Cursor,Void> function){
if (cursor .moveToFirst()) {
while (!cursor.isAfterLast()) {
function.apply(cursor);
cursor.moveToNext();
}
}
cursor.close();
}Next, we need an OutputStream we write the data to, and a writer:
ByteArrayOutputStream bufStream = new ByteArrayOutputStream();
GZIPOutputStream out = new GZIPOutputStream(bufStream);
this.writer = new JsonWriter(new OutputStreamWriter(out, "UTF-8"));Now, everything we write into writer will get GZIPed and will end up in bufStream.
Next, we'll define the methods that actually write the data. The resulting JSON will be like this:
{"locations":[
{
"name":"location1",
"stuffs":[
{
"name":"stuff1"
},
{
"name":"stuff2"
}
]
},
{
"name":"location2",
"stuffs":[]
}
]}The export should be separated by objects/arrays, as it makes the streaming more readable and also help catch unclosed object/arrays more easily.
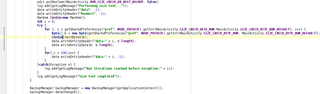
private void writeBackup(final JsonWriter writer,final SQLiteDatabase db) throws IOException{
writer.beginObject();
writer.name("locations");
writeLocations(writer,db);
writer.endObject();
writer.close();
}private void writeLocations(final JsonWriter writer,final SQLiteDatabase db) throws IOException{
writer.beginArray();
DatabaseHelper.iterateOverCursor(db.query(MySqlLiteHelper.TABLE_LOCATIONS, null, null, null, null, null, null), new Function<Cursor, Void>() {
@Override
public Void apply(Cursor cursor) {
try {
writer.beginObject();
writer.name("name").value(cursor.getString(cursor.getColumnIndex(MySqlLiteHelper.LOCATIONS_COLUMN_NAME)));
writer.name("stuffs");
writeStuffs(writer, db, cursor.getLong(cursor.getColumnIndex(MySqlLiteHelper.LOCATIONS_COLUMN_ID)));
writer.endObject();
return null;
}catch(IOException e){
throw new RuntimeException(e);
}
}
});
writer.endArray();
}private void writeStuffs(final JsonWriter writer,SQLiteDatabase db,Long locationId) throws IOException {
writer.beginArray();
DatabaseHelper.iterateOverCursor(db.query(MySqlLiteHelper.TABLE_STUFF, null, MySqlLiteHelper.STUFF_LOCATION_ID + "=?", ImmutableList.of(locationId + "").toArray(new String[]{}), null, null, null), new Function<Cursor, Void>() {
@Override
public Void apply(Cursor cursor) {
try {
writer.beginObject();
writer.name("name").value(cursor.getString(cursor.getColumnIndex(MySqlLiteHelper.STUFF_COLUMN_NAME)));
writer.endObject();
return null;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
});
writer.endArray();
}Note: You might be using an ORM, it does not make any difference. Just read the data and serialize it somehow into JSON.
And thats it, it can be written into the BackupDataOutput:
byte[] buffer = bufStream.toByteArray();
int len = buffer.length;
data.writeEntityHeader(DATABASE_KEY, len);
data.writeEntityData(buffer, len);Restore implementation
The restore is very similar to the backup, just the opposite direction. First, we construct the reader:
ByteArrayInputStream baStream = new ByteArrayInputStream(dataBuf);
GZIPInputStream in = new GZIPInputStream(baStream);
this.reader = new JsonReader(new InputStreamReader(in, "UTF-8"));Then we read the entities one by one, and save them to the database:
public void readBackup(SQLiteDatabase writableDb) throws IOException{
readBackup(reader,writableDb);
reader.close();
}
private void readBackup(JsonReader reader,SQLiteDatabase writableDb) throws IOException {
reader.beginObject();
reader.nextName();
readLocationArray(reader,writableDb);
reader.endObject();
}private void readLocationArray(JsonReader reader,SQLiteDatabase writableDb) throws IOException{
reader.beginArray();
while(reader.hasNext()){
readLocation(reader,writableDb);
}
reader.endArray();
}private void readLocation(JsonReader reader,SQLiteDatabase writableDb) throws IOException{
writableDb.beginTransaction();
try {
reader.beginObject();
reader.nextName();
String locationName=reader.nextString();
long locationId;
{
ContentValues values = new ContentValues();
values.put(MySqlLiteHelper.LOCATIONS_COLUMN_NAME, locationName);
locationId = writableDb.insert(MySqlLiteHelper.TABLE_LOCATIONS, null, values);
}
reader.nextName();
readStuffArray(reader,writableDb,locationId);
writableDb.setTransactionSuccessful();
reader.endObject();
}finally{
writableDb.endTransaction();
}
}Note: Notice the explicit beginTransaction() and endTransaction(). This greatly increases the speed of the inserts. See this blog post about this.
... And so on, same for the Stuffs.
And we construct the dataBuf like this in the onRestore() method:
while(data.readNextHeader()){
String key = data.getKey();
int dataSize = data.getDataSize();
if (DATABASE_KEY.equals(key)) {
byte[] dataBuf = new byte[dataSize];
data.readEntityData(dataBuf, 0, dataSize);
...
}
}Also, do not forget to clear all the previous data from the database!
Checking the correctness of backup
Running a backup and then a restore indeed worked fine. To check it, I've introduced a database hash which is a consistently ordered read of all entity name hashed with SHA-1. This produces a string that can be used to check the data without manually examining the database.
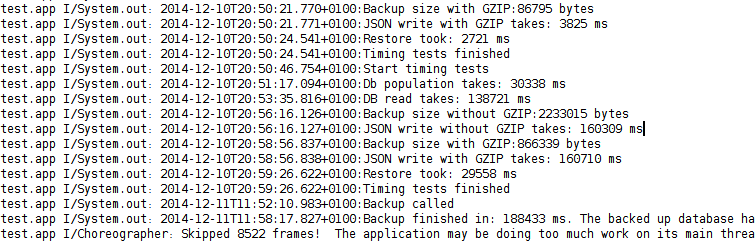
I've ran the backup:
Backup called
Backup finished in: 3140 ms. The backed up database hash is: b314074684cc30ceb9b671d0be1c7bdd6251ca3eThen, I've modified the database, effectively changed the hash, then ran a restore:
Restore finished in: 2834 ms. The restored database hash is: b314074684cc30ceb9b671d0be1c7bdd6251ca3eThe hash is the same, so the data is the same.
Note: The hashing algorithm I use does not take the IDs, only the names. It is probable that the autogenerated IDs are different after the restore than before the backup.
Measuring timing and size requirements
I've ran multiple tests with different amount of entities ranging from a small database to a relatively big one. I've also ran a couple of tests for each run:
- Db population: How much time was needed to populate the db with the desired amount of entities
- DB read: How much time was needed to read the whole database, without writing anything
- Backup size without GZIP: The amount of bytes the raw JSON takes
- JSON write without GZIP: How long the export took without GZIP
- Backup size with GZIP: The amount of bytes the full-featured backup takes
- JSON write with GZIP: How long it was
- Restore: How long a full restore is
I've made the following runs:
- 10 Locations, 10 Stuffs each (110 total)
- 100 Locations, 10 Stuffs each (1100 total)
- 100 Locations, 100 Stuffs each (10100 total)
- 1000 Locations, 100 Stuffs each (100100 total)
The findings are summarized in this table:
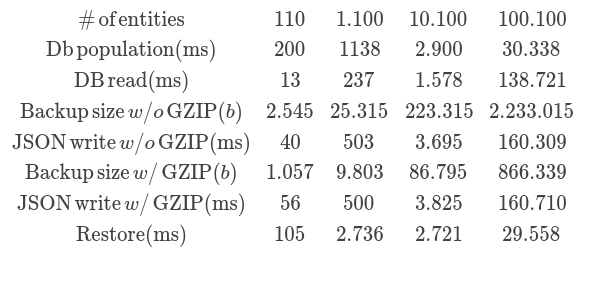
We can conclude several things from the table above. First, restoring from the GZIPed stream did not have any overhead as generating the entities randomly (in fact, it was faster. It may happen because of increased heap size when the last step is running, or some caching, or the random is slow). Also, GZIPing the stream also had no effect on the running time. All the tests shown <1sec differences to the raw stream. But the size requirements are significantly lower, with GZIPing we'll see unacceptably long backups/restores before reaching the 2MB limit.
On the other side, serializing into JSON does add a considerable overhead. On smaller data sets it is still a little (4 sec vs 2 sec), on larger sets it is more considerable. For the largest set I've tested it added a 16% computation to the raw read.
Conclusion
The method described above is a valid solution to backing up SQLite databases on Android. It can be used for a sizeable amount data, and is also compatible with the Backup Manager. It is expected that the 2MB limit will be enough for most apps. Also, the JSON serializing gives the freedom to freely choose the schema, and it can be also processed with other apps easily. Also, with dump versioning, apps can be made to restore any previously made backups, no matter the concrete database schema.

