
My AWS wishlist
Various things that would make AWS developers' life easier


This time of the year is about wishes, so here are the things that would make life easier for developers working on systems running in AWS. I'm sure I'm not the first one to think about these and they cover only a small subset of all AWS services.
General
Tags, resource-based policies, and CloudFormation support for all services
Some things are supposed to work across all services in AWS. For example, using tags to define permissions (also called Attribute-Based Access Control) is based on tagging resources and identities and defining policies to grant access based on matching values. If you read the documentation, it seems to be a great way for scalable permission management.
It seems to be a feature of the AWS cloud that you can use tags. But it's not, it's a feature of individual services. The reference documentation shows the services and which ones support "Authorization based on tags" and which ones do not. The result is that you can only used tags for permissions in some cases but not in others.
A similar problem is with the lack of universal support for resource-based policies. Again, some services support it, some don't so you can't depend on being able to define permissions on the resource-side without first checking that the services you plan to use support it.

Then there is CloudFormation. You can use it to automatically configure services in AWS. Except that it does not support all services, and it's a constant stream of announcements that a new service or change becomes supported.
All these things are supposed to be "AWS-wide" but in reality they are "service-specific" making it hard to reason about how to configure them and it's a contant source of confusion. They should be supported in all services, from the start, with all updates immediately reflected on them.

Remove discrepancies between services
Many things work differently in different services that should be universal concepts in AWS. S3 bucket policies and KMS key policies both control who can do management operations on the resources, such as they can prevent deleting an S3 bucket or a KMS key. But root users are exempt from bucket policies, while if you lock yourself out with a key policy you need to contact support. Why is there a difference?
And this is not an isolated thing. Most resource-based policies are effective for management operations. But a policy attached to an IAM role can only influence
who can assume it and not, for example, who can delete it. Is it because it's called "trust policy"? But it's a policy attached to a resource, which is pretty
much what resource-based policies are. Still, it's different. Is the policy attached to a Lambda function can control lambda:DeleteFunction or only
lambda:InvokeFunction? I don't know and I don't see any other way of knowing this than trying it out.
When the same thing works differently in different parts of AWS it makes it hard to know what is possible without extensive experimentation with every single service you intent to use. And that's a frustrating experience. Concepts that seem AWS-wide should be supported the same way in all services.
IAM
Debug requests
AWS provides a bunch of managed policies that allow an easy way assign permissions to users. If you want to allow only reading s3 buckets, you can add the
AmazonS3ReadOnlyAccess, and if you want to allow managing Lambda functions then the AWSLambdaFullAccess. This allows service-level access control
without writing any kind of policies yourself.
But if want anything more granular, it becomes exponentially more difficult.

IAM policies protect AWS APIs. When a request reaches an API, it first assembles a request context with all the data that is available at this moment. This includes the Principal (who is doing the request), the Action (what is being done) and the Resource (on what). Apart from these, IAM also collects a lot of metadata, such as the IP address of the connection, whether the keys used in the request are authenticated with an MFA device, the tags that are attached to the Principal and the Resource, and a lot more.
In an IAM policy, you add Conditions that check the values in the request context. For example, you can deny S3 bucket deletes without MFA authentication, restrict the IP address range to the company IP block, or only allow access to S3 objects that have a specific tag attached to them.
This sounds great, but in practice it's mostly reading the AWS documentations, trying out something, seeing it not working, then trying to fix it by reading the documentations again. It's a frustrating experience.
For example, the aws:ResourceTag/<key> is a global condition
key that is present in all requests.
Use this key to compare the tag key-value pair that you specify in the policy with the key-value pair that is attached to the resource.
Since S3 objects can be tagged, it means that this contains the object tags? Nope, there is a separate key for that, the s3:ExistingObjectTag/<key>.
Or when API Gateway calls a Lambda function, you can use the aws:SourceArn to give access to a specific API Gateway. Similarly, an SQS queue can allow a
specific CloudWatch Event Rule via the same condition. Does that mean that an IAM role's trust policy can limit the Lambda function that can use it? Nope.
And when you encounter something that should work but isn't, the only resource is the documentation AWS provides. There is zero visibility what is wrong with the policies that are misbehaving.
There should be a service to debug IAM requests. I'd love a "request recorder" that I could use to selectively record live requests and see all the metadata in the request context exactly how IAM sees them. This would remove the quesswork of what condition keys are available in the exact scenario I'm interested in.
As an added benefit, it could also show the steps in the policy evaluation logic.

Allow session policies for assumed sessions
The session policy is an additional security mechanism to control access. It's a drop-capabilities style control, as the principal willingly put additional restrictions on itself.
It is an optional parameter of the assume-role call:
aws sts assume-role \
--role-arn <arn> \
--role-session-name "test" \
--policy file://policy.jsonWhen the resulting role session makes a call, the session policy must also allow the operation, in addition to its identity policies.
When is this useful? Let's say you have a multi-tenant application, storing data for multiple customers in separate S3 buckets. The application handles all customers, so it needs access to all buckets. But when the program determines which customer is making the request, it can put a session policy to limit itself to a single customer bucket. If there is a bug later in the code, this session policy prevents compromising the other buckets.
The problem is that it's only supported for assume-role calls, so you can only use it when you assume a role. And this complicates its usage in common
use-cases.
A session policy should be able to be applied to already assumed sessions, such as when a Lambda function is running. This way, it would be easy to put these additional safeguards without needing to reassume the execution role.
Similarly, it would be great if IAM access keys could support session policies via the get-session-token call.
Lambda
Allow restricting an IAM role to a single function
Currently, an IAM role's trust policy can only define the lambda.amazonaws.com service but not the specific function. Since most execution roles are
for a single function, it would be great if this could be enforced in the role itself.
Separate warmup requests
Cold starts, also called first requests, happen when the Lambda service needs to start a new instance of the function. When it happens, the request needs to wait the setup process when the service deploys the code to a new machine. Worse still, the request also needs to wait while the execution environment is set up and for any application-specific setup process. This makes it noticably longer than other requests.
This cold start can easily be orders of magnitude slower than other requests. At one point I worked on an app that precompiled a bunch of JSON schemas during the first request. It took ~10 seconds, then all the later requests were between 50 - 100 ms. This code demonstrates this behavior:
const wait = (time) => new Promise((res) => setTimeout(res, time));
const startup = wait(10000);
module.exports.handler = async (event, context) => {
await startup;
await wait(100);
return "Hello world";
};How the Lambda service works today is that the request waits until the cold start is finished. If there is 1 instance running and 2 requests comes at the same time one will take 50 ms and the other 10 seconds! If the second request is simply queued, it would be finished in 100 ms. As a result, there will always be some requests that take 10 seconds and that forces me to bring this down to an acceptable level even when I don't expect spikes in traffic.
Lambda should do a warmup request when it needs to start a new instance and queue the requests to the already running instances and only start using the new environment when it's properly warmed up.
Organizations
Programmatically delete a member account
Creating accounts via Organizations is easy to automate. It is just an API call and it also creates a role with Administrator access so that you can also script how to setup resources inside. Since separate accounts provide limits to the blast radius (the damage a security breach can do) it's a good practice to use many of them.

I remember seeing a presentation where a representative a from company told the audience that they are using thousands of AWS accounts and they have a fully automatized process to create more.
That's great but I wouldn't trade places with the person who is tasked to get rid of those accounts when the company decides to downsize its AWS footprint.
While creating accounts is a scriptable process down to the last detail, deleting an account is an entirely manual task. You need to set the root user's password by clicking a link in a recovery email, then submitting a form to delete the account. There is no API to do any of these steps automatically. There is a great video from Ian Mckay who made a solution using Puppeteer and a cloud CAPTCHA-solving service to automate this.

Another problem case is when you want to provide a lab-like environment to untrusted people. You can create a sandbox account, put a restrictive SCP to prevent excessive damage, then give access to the person to experiment with the services. But what happens when this user is finished? If you create a new account for every lab session you'll end up with a growing number of unused accounts. If you reuse them you need to delete all resources which is a challenge.
Deleting an AWS member account should be as hard as creating one.
Demote the management account
When you start using Organizations that account becomes the management account. It can create member accounts and also provide SCPs to restrict what they can do.
The problem is when you start creating resources in the account before start using Organizations. The best practice is to use resources only in member accounts, but what to do when you already have things that are hard to move, such as Elastic IPs, S3 buckets, and other resources?

It would be a great if the management account could be demoted to a member account with all the billing information moved to a new account. This would make adapting a multi-account setup and SCPs easy: just create a new account and promote it to be the top of the tree. Then you could add policies and start separating resources without the need to migrate anything.
Billing
Hard limits on spending
You can set billing notifications that let you know when the projected spending crosses a threshold. This can turn into a security control so that you'll get an advance warning when something is consuming too much which might indicate an error or a breach.
It's great when you run production systems that you want to keep online at all costs. But what if inside a developer's sandbox account or a side project that goes awry? It's usually a sign of problems and the primary course of action is damage limitation then.
And this is what AWS does not support at the moment. You can not put hard restrictions on the monthly bill. Considering that even a single API call can cost more than a million dollars (yep), a problem that starts out as a small breach in a non-essential account can spiral out of control and all you can do is contact AWS and ask for a refund which you may or may not get.
There should be controls over the maximum possible spending in an account. I imagine it would be a 2-tiered setup. When the actual monthly bill reaches the lower one then all API calls are denied and restartable resources are stopped. This would prevent invocations to Lambda functions, stop all EC2 instances, and deny creating any new resources. Then the higher limit would completely eliminate all cost-incurring things in the account, such as S3 buckets, databases, EBS instances.
These limits would allow choosing between "up and running no matter the cost" and "shut down if there is a problem".
Combined with the ability to programmatically remove an account, it would be possible to safely create an account and give it to an untrusted party. With budget controls you could make sure it can not overspend and you could delete it without a trace when it's not needed.
Also, it could prevent overusing the free tier. When new users sign up for AWS, it's a common source of complaints that not everything is free during that period. Launching a large EC2 instance and keep it running is expensive and it requires some knowledge of the platform to know that it's not covered in the free tier.
CloudFront
Speed up deployment
The time it took for CloudFront to deploy even the slighest of changes used to be 25 minutes. Now it's under 5 minutes. This is a great improvement, but it's merely a step from "unbelievably slow" to "terribly slow" territory. During development, it should not be more than 10 seconds.
I see all the reasons why it's a very hard thing to do. But the thing is, during experimentation there is no need for the full power of the global CloudFront network. Introduce a Price Class 0 that is limited to a single region (this would also help with Lambda@Edge logging) and push updates to it instantly.

Delete replicated functions instantly
When a Lambda function is used in a CloudFront distribution it is replicated across the edge locations. This makes them run close to the users and that reduces latency. This replication happens during the deployment of the distribution and it's managed entirely by AWS.
If you've ever tried to destroy a stack with a Lambda@Edge function you've certainly met this error:

Error: Error deleting Lambda Function: InvalidParameterValueException: Lambda was unable to delete <arn> because
it is a replicated function. Please see our documentation for Deleting Lambda@Edge Functions and Replicas.It turns out that deleting the CloudFront distribution does not involve deleting the function replicas it just marks them for deletion. Then a process comes and in a few hours cleans them up. But until then, you can not delete the Lambda function with the rest of the stack.
This should be an implementation detail and should not prevent deleting the function.
Change the origin request path
When a request reaches the CloudFront distribution, it uses the path pattern of the cache behaviors to determine which origin to send the request to. This is called path-based routing.

But the path pattern of the cache behaviors only help with choosing the origin, but they won't change it in any ways. A request with /api/user gets
matched by the /api/* path pattern, but when CloudFront sends the request to the origin it uses the full path as /api/user.

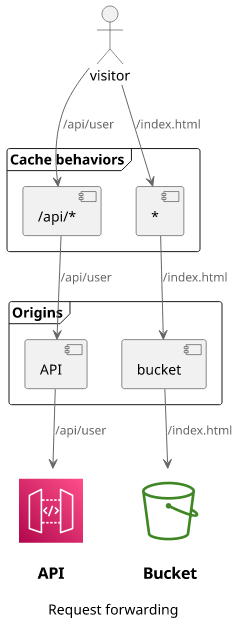
This can cause problems when the backend expects requests coming to / instead of /api/.

Apart from APIs, it's also a problem with S3 buckets. For example, if you have app1 and app2 and want to serve their static files from /app1/ and
/app2/, respectively, then you need to prefix the files in the bucket with that path too. This forces a change in how the files are stored because how
the client connects to CloudFront.
The solution for now is either to adapt the backend or use Lambda@Edge to change the path of the origin request. The latter is a cleaner solution as it does not force the backend services to change solely because of how clients view the content, but it brings a lot of complications and costs.

It would be great if there was a config option in the CloudFront distribution that allow changing the origin path based on a configurable pattern. Even something
simple, like a regex with a capture group would do it. Specifying ^/api(/.*)$ could capture everything after the /api part and cut the prefix before
forwarding.
S3
HTTPS endpoint for the bucket website
S3 supports a bucket website endpoint that exposes the contents as a website. This uses a generated URL in the form of
http://<bucket>.s3-website-<region>.amazonaws.com. You need to give public access to the contents, but it provides a simple way to host web content straight
out of a bucket.
But this endpoint is HTTP only and does not support HTTPS. Because of this, it is not suitable for browsers, as they flag the page as "Not secure" or "Mixed content". To solve this, you need to add TLS termination either with a CloudFront distribution or with a third-party service. These solutions also help with adding a custom domain name, but what if you don't need it?


I don't see any constraints that makes it impossible for AWS to host an S3 static website available via HTTPS. It would make it easier to host sites or assets in a bucket with a simple configuration.
Remove SSE-S3
SSE-S3 is one of the encryption schemes available for S3 objects. This is seamless encryption, which means all the encryption and key handling is done by the service and none of these details are observable to the consumers.

It always puzzled me why this option exists. Enabling it does not change any of the API calls, and it does not prevent any accesses that were previously allowed. Turning on this option has no observable effect.
Remove this setting and store all objects encrypted.

