
How to use Lambda@Edge with Terraform
The differences between Lambda@Edge and regular functions


Lambda@Edge
Lambda@Edge is advertised mainly as a tool that brings processing closer to the users thus increasing speed. But as a developer, I see a different use-case: to influence how CloudFront works. Without functions, CloudFront offers only a handful of configuration options. You can add origins and cache behaviors to set up routing, but you'll run out of options as soon as you need anything beyond the basics.
This is when Lambda comes handy. You can modify the requests and the responses any way you'd like, which opens up ways to fix most of the shortcomings of CloudFront config.
There are some differences from a regular Lambda function though, and some new limitations you should know about before you start using edge functions.

Differences from a regular Lambda function
The usual Lambda resources are needed: an archive_file to hold the code, an aws_iam_role for the execution role, an aws_iam_policy_document
for the function's permissions and an aws_iam_role_policy to wire the last two together. This is what you need for any Lambda function, so let's concentrate
on the differences!
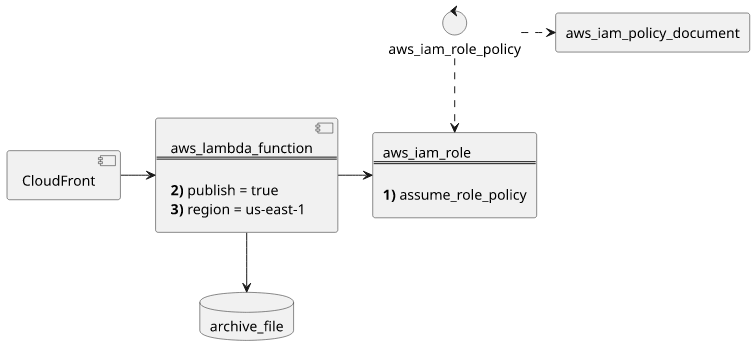
aws_iam_role
The aws_iam_role's assume role policy must include both lambda.amazonaws.com and edgelambda.amazonaws.com:
resource "aws_iam_role" "lambda_edge_exec" {
assume_role_policy = <<EOF
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": ["lambda.amazonaws.com", "edgelambda.amazonaws.com"]
},
"Effect": "Allow"
}
]
}
EOF
}aws_lambda_function
Since Lambda@Edge requires a specific version to be referenced, you need to instruct Terraform to publish a new version for every change. To do this,
use publish = true:
resource "aws_lambda_function" "lambda_edge" {
# ...
publish = trueThe function must be deployed in the us-east-1 region. If you deploy the whole stack there then it's not a problem, but it's better to make sure that is
not a requirement. Fortunately, Terraform can deploy resources to multiple regions, which is exactly what we need here.
First, define a provider with the us-east-1 region specified:
provider "aws" {
alias = "us_east_1"
region = "us-east-1"
}Then make the function use this provider:
resource "aws_lambda_function" "lambda_edge" {
# ...
provider = aws.us_east_1
}This makes sure this function goes to us-east-1 no matter where the rest of the resources are deployed.
CloudFront
To associate this function with a distribution, add a lambda_function_association to the cache_behavior:
resource "aws_cloudfront_distribution" "distribution" {
# ...
# or default_cache_behavior
ordered_cache_behavior {
# ...
lambda_function_association {
event_type = "origin-request"
lambda_arn = "${aws_lambda_function.lambda_edge.qualified_arn}"
}
}
}The lambda_arn must include the version, that's why the qualified_arn has to be used here.
The event_type must be one of the 4 defined trigger point: viewer-request, origin-request, viewer-response, and origin-response.
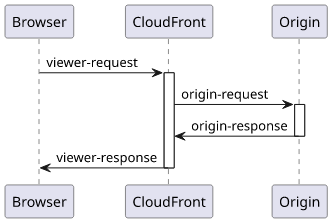
In this case, I want to change how CloudFront calls the origin, so I specify the origin-request trigger.
Example code
Now that we have all the resources in place, let's see an example!
CloudFront appends the full path to the origin request which can be a problem, for example, when your API expects requests
starting from the root (/) instead of some other path.
With a fairly common configuration of an API Gateway with the /api/* pattern, a request to /api/users goes to, well, /api/users. But then you
need to make sure your API is able to handle this path and does not expect /users instead.

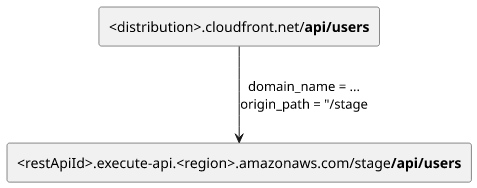
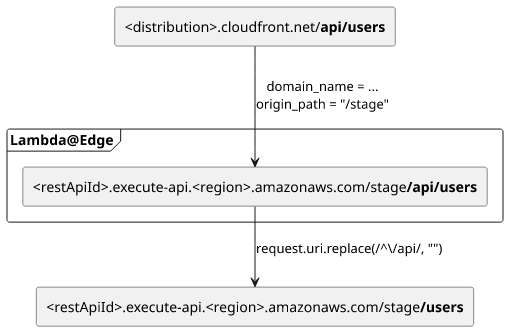
It would be better to just strip the /api path from the request sent to the origin. And that's when Lambda@Edge comes useful.
The code is straightforward. The event.Records[0].cf.request.uri contains the path /api/users and we need to strip the /api part from the
start:
module.exports.handler = (event, context, callback) => {
const request = event.Records[0].cf.request;
request.uri = request.uri.replace(/^\/api/, "");
callback(null, request);
};
Update: With CloudFront Functions it is now possible to solve this without the complicated setup of Lambda@Edge.

Pricing
Seems like the pricing is deliberately made to make it hard to compare traditional and Lambda@Edge pricing. The request charges are straightforward: $0.2 vs $0.6.
But for duration prices, one is in GB-seconds and 100ms increments the other one is 128MB-seconds and 50ms increments. In GB-seconds it's $0.0000166667 vs $0.00005001, which is again three times the price.
In total, Lambda@Edge is three times as expensive as a normal Lambda.
But for simple cases, like transforming a request, the math is a bit different. Lambda@Edge is metered at 50ms increments and if you don't use any external services then it's likely you'll never exceed that. That means for every 1 million requests you'll pay ~$0.9 extra.
Destroying
When you try to destroy a stack with Lambda@Edge functions, you'll see this error message:
Error: Error deleting Lambda Function: InvalidParameterValueException: Lambda was unable to delete <arn> because it is a replicated function. Please see our documentation for Deleting Lambda@Edge Functions and Replicas.When CloudFront starts using the Lambda function it replicates it to the global network. This happens during that ~20 minutes the distribution is deploying.
But when you delete the distribution, while it still takes ~20 minutes, the replicated functions are not deleted but only scheduled for deletion. In effect, Lambda complains about the replicas and refuses to delete the function.
You need to wait a few hours (!) after you delete the distribution to delete the function. Keep trying to terraform destroy until you succeed.
It's funny to see that even this was an improvement over how it originally worked. AWS devs did not think people would want to delete Lambda@Edge functions, like, ever.
Conclusion
Lambda@Edge gives you the missing piece of CloudFront configurations. Apart from request rewriting, you can add cache or security headers, define more advanced routing policies, optimize content, and a lot more. It is a valuable tool when working with CloudFront.

