
Modeling common GraphQL patterns in DynamoDB
How to structure data in the tables to support efficient GraphQL queries


DynamoDB is all about access patterns. Since it is a NoSQL database, it does not support arbitrary queries that extract just the necessary data. DynamoDB's queries are centered around the choice of the partition and the sort key, so depending on how you define them different data can be retrieved.
In this article, we'll look into the most common query patterns in GraphQL and how to structure the DynamoDB tables and indices to support them.

References
This is the easiest case. An object references another object (User.group):
type User {
id: ID!
group: Group!
}
type Group {
id: ID!
}Here, store the ID of the target object in a field in the source (User.group_id):
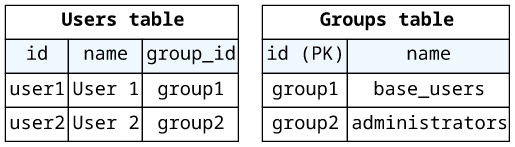
Then in the User.group resolver the ID is available for the GetItem operation:
{
"version": "2018-05-29",
"operation": "GetItem",
"key": {
"id": {"S": $util.toJson($ctx.source.group_id)}
},
"consistentRead": true
}2-way mapping
If you need to map back to the original object, store the IDs on both ends.
For example, when you have a car and a driver:
type Driver {
id: ID!
car: Car
}
type Car {
id: ID!
driver: Driver
}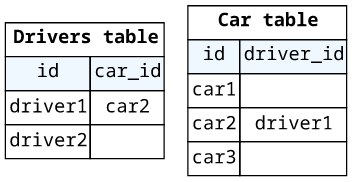
Here, the other ID is available both at the Driver.car and the Car.driver resolvers.
Lists
To map a one-to-many relationship, define an index with the partition key as the ID of the aggregate object.
For example, if the schema defines Users and Groups and the latter has a field that returns a list (Group.users):
type User {
id: ID!
}
type Group {
id: ID!
users: [User!]!
}Add an index that has the group_id as its partition key:
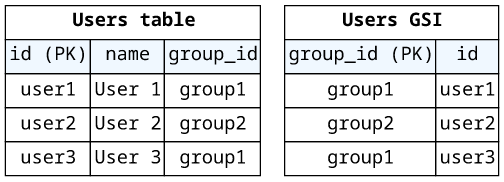
In the Group.users resolver, query the index with the source's ID:
{
"version": "2018-05-29",
"operation": "Query",
"index": "groupId",
"query": {
"expression": "#groupId = :groupId",
"expressionNames": {
"#groupId": "group_id"
},
"expressionValues": {
":groupId": {"S": $util.toJson($ctx.source.id)}
}
}
}Pagination
The DynamoDB Query operation is paginated, which means the database might return only partial results along with a pagination token. Repeating the query with the previous token fetches the next page, and to get all items do this until there is no token in the response.
It is a best practice to expose this in the GraphQL API so that it supports arbitrary number of result items.

Ordering
To define the ordering of the result items, add a sort key to the table/index. This makes the position of the items deterministic, and also supports range queries on this key.
type User {
id: ID!
last_active: AWSDate!
}
type Group {
id: ID!
users(active_after: AWSDate, active_before: AWSDate, increasing: Boolean): [User!]!
}To make this possible on the database level, add the sort key:
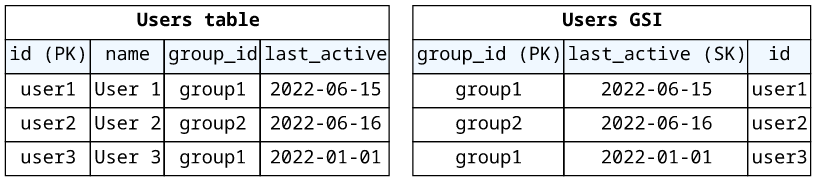
Then in the resolver, you can define the sort key in the key condition
expression and the scanIndexForward
argument of the Query operation.
Filtering
The schema might define an argument field and the result should contain only matching items. For example, Users might have a have a status field and
the Group.users field can accept an argument that filters the list:
type User {
id: ID!
status: String!
}
type Group {
id: ID!
users(status: String!): [User!]!
}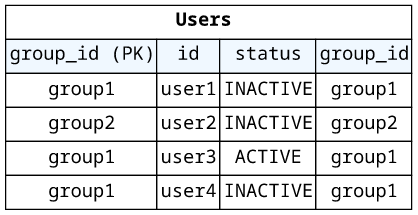
Filtering can be done in multiple ways in DynamoDB.
One approach is to use a filter expression. In this case, there is no need to change how you store the data, simply define the expression and DynamoDB returns only the matching items.
But using the filter expression can affect performance and lead to some surprises.

A more efficient way is to add the field to the partition key of the table or the index. This way, the value can be part of the key expression.
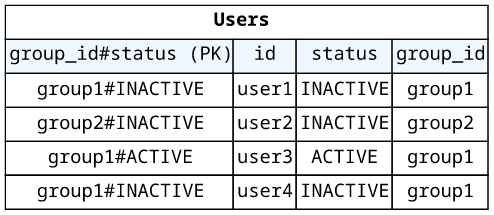
The resolver then can define both parts of the key:
{
"version" : "2018-05-29",
"operation" : "Query",
"index": "groupIdStatus",
"query": {
"expression" : "#groupIdStatus = :groupIdStatus",
"expressionNames": {
"#groupIdStatus": "group_id#status"
},
"expressionValues" : {
":groupIdStatus" : {"S": "$util.escapeJavaScript($ctx.source.id)#$util.escapeJavaScript($ctx.args.status)"}
}
},
"limit": $util.toJson($ctx.args.count),
"nextToken": $util.toJson($ctx.args.nextToken),
"scanIndexForward": false
}There are quite a few other considerations here. See this article for more info.

Conclusion
In DynamoDB, what queries are efficient are defined by the table structure. To support the different GraphQL structures you need to adapt how you store data.

