
How to use CloudFront Functions to change the origin request path
The new way to run code on the edge provides many benefits over Lambda@Edge


Up until now, CloudFront supported only one way to run arbitrary code on the edge. It is Lambda@Edge and with it, you can associate Lambda functions with CloudFront cache behaviors and these are called whenever a request is made to/from the CDN. This looks great on an executive presentation slide, but in practice there are not many good use-cases for it and using Lambda with CloudFront brings a good amount of complexity to the architecture.
But there is one particular problem that comes up over and over again and before CloudFront Functions, Lambda@Edge was the only good solution.

Let's say there is a single-page webapp (SPA) with a fairly typical setup: an S3 bucket holds the static files (index.html, bundle.js, and other assets) and an
API Gateway provides the backend. Then a CloudFront distribution routes to them, with a cache behavior that maps /api/* to the API Gateway, and everything
else to the S3 bucket.
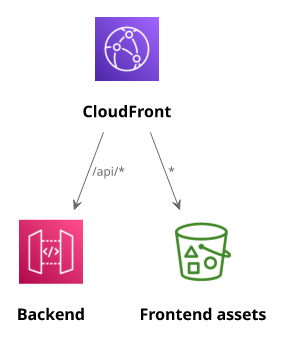
This is a great solution, as it brings the backend and the frontend under the same domain, and it can also utilize CDN optimizations and custom domains.

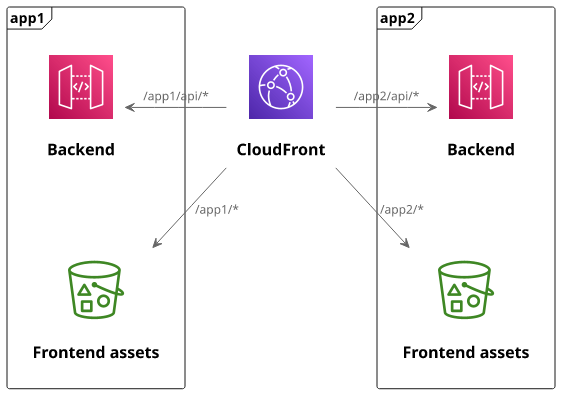
But then comes a change request: you need to move this and another similar SPA to a single domain. The expected result is to have /app1/ to open the first
app, and /app2/ the second one.
Should be simple, right? Just change the cache behaviors so that:
/app1/api/*=> App 1 API Gateway/app1/*=> App 1 bucket/app2/api*=> App 2 API Gateway/app2/*=> App 2 bucket
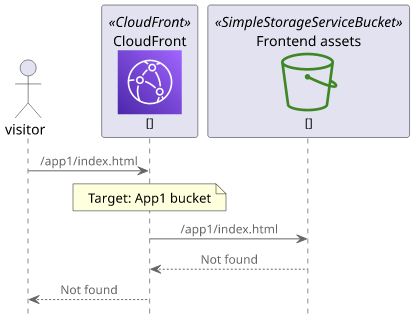
Except that it does not work. When you open /app1/index.html you'll see an error instead of the webapp.
The reason is the origin request path. The cache behavior uses the path pattern (/app1/*) to do the routing, but it does not change the path when it sends
the request to the origin.
Before the change, /index.html went to the S3 bucket as /index.html. After the change, /app1/index.html reaches the bucket as
/app1/index.html. Unless you move all the objects into the app1 directory, S3 won't find the file.
Similarly, if the API expects all requests to go to /api/, then after the change it will see all requests going to /app1/api. Unless you change the
API, this messes up the paths.
This is where Lambda@Edge comes into play. Unless you want to change the origins, which is not a good solution, you need to fix the origin request path. A
Lambda function that is called for each request that can change what is sent to the origin makes this possible. Before CloudFront sends the request to S3 for
a request to /app1/index.html, the function can cut the first part and make it go to /index.html. In effect, you can separate the origin request
path from the cache behavior path pattern.
Until now, Lambda@Edge was the only solution for this problem that did not require changes on the origins. But the recently announced CloudFront Functions provides an easier alternative. And since there is full support for it from Terraform, it's ready for prime time.

CloudFront Functions
You can think of CloudFront Functions as a lite version of Lambda@Edge. They support only the viewer-request and the viewer-response triggers, and you can not access the request/response body. Also, as it is limited to very basic code and a runtime of at most 2ms, it is only useful for some basic modification of the request or the response. Fortunately, this covers most of the use-cases of Lambda@Edge.
Along with these limitations come several advantages. CloudFront Functions are cheaper and faster than Lambda@Edge functions, and they require only one extra resource.
Creating a function
The function itself needs very little additional config besides the code itself.
resource "aws_cloudfront_function" "rewrite_uri" {
name = "rewrite-request-${random_id.id.hex}"
runtime = "cloudfront-js-1.0"
code = <<EOF
function handler(event) {
var request = event.request;
request.uri = request.uri.replace(/^\/[^/]*\//, "/");
return request;
}
EOF
}You need to give it a unique name, for which the random_id data source provides an easy-to-use solution.

Then the runtime needs to be cloudfront-js-1.0. CloudFront might support multiple runtimes in the future, but at the moment this is the only one.
As for the code, note that this runtime does not provide a modern Javascript platform, just some basic parts of it. The documentation
page lists what is possible and what is missing.
The most notable omission is the lack of const/let support.
The easiest way to define the code is with Terraform's HEREDOC syntax. And since the function is unlikely to be more than a few lines, inlining works just fine.
The code in this function removes the first segment from the path (/app1/api/ => /api/). This works by modifying the request.uri value. The
documentation page shows what data is available and which
are modifiable by the function.
Associating with a cache behavior
CloudFront Functions use the same element to associate with cache behaviors as Lambda@Edge. You need to specify the event_type, which is either viewer-request or
viewer-response, and the function ARN.
resource "aws_cloudfront_distribution" "distribution" {
# ...
ordered_cache_behavior {
# ...
function_association {
event_type = "viewer-request"
function_arn = aws_cloudfront_function.rewrite_uri.arn
}
}
}There is one important thing to note here. CloudFront uses the path for routing, i.e, selecting the cache behavior. But what happens if the function changes the path for the viewer request? Wouldn't it interfere with the routing if the request no longer matches the path pattern?
Fortunately, no. The cache behavior is already selected when the function runs, so it can change the path and it will only affect the request sent to the origin.

How it works
With this CloudFront Function configuration, you can solve the multi-apps problem. When you associate it with all cache behaviors, it cuts off the
/app1 and /app2 parts from the request so the origins won't get confused.
When a request comes for the first app, for example to /app1/index.html, CloudFront first selects the cache behavior. In this case, it will be the first
app's S3 bucket. Then the function runs, and it cuts the /app1 part from the request path. CloudFront sends the request to S3 as /index.html, which
returns the file.
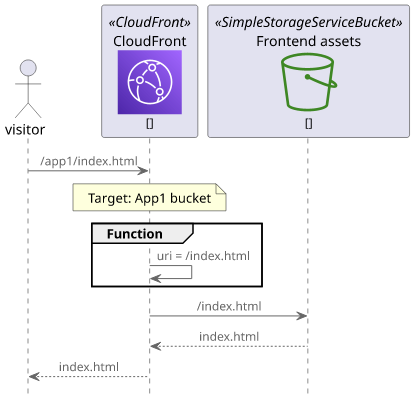
A similar process happens for the API endpoints too. A request to the second app's backend, such as /app2/api/users, triggers the correct cache behavior.
Then the associated function removes the first part so the API Gateway origin sees the request path as /api/users. Since it matches what it was before the
change, it works as expected.
Conclusion
CloudFront Functions solve a subset of problems that Lambda@Edge can solve with a lot less complexity. Fortunately, this subset covers most of the practical use-cases.
My recommendation is to first see if CloudFront Functions are enough for your use-case and if it is, use that over Lambda@Edge.

