
DynamoDB basic operations
The primitives to read, write, and query tables


Working with DynamoDB
DynamoDB is a key-value store which means that every item needs a unique key and operations are per item. Because of this, what operations it supports and how it is best used is entirely different than SQL-based databases.
On one hand, DynamoDB promises practically infinite scalability: getting and putting items by their keys can be distributed to many machines. But this
operational elegance comes with the cost of radically limited operations supported. There is no count(*), joins, inner SELECTs, or arbitrary
fields in a WHERE. Because of this, data modeling in DynamoDB is more difficult and needs to take access patterns into account.
In this article we'll look into the operations that are possible in DynamoDB and how to use each of them. These operations form a toolbox: when designing and implementing an application that uses DynamoDB it can use these primitives.

GetItem
The GetItem is the simplest operation DynamoDB offers. You know the ID of the item, and you get back the whole item.

PutItem
The other half is to store items in the table. Here, you need to define the whole item.

Since every item needs a unique key, this is an upsert operation: it creates the item if none exists with the provided key, or updates an existing one.

Conditions
The PutItem on itself is a very crude operation: it stores whatever item is passed to it. But the database is usually accessed by many processes at the
same time. What if the item is modified concurrently?
Conditions are the cornerstone of concurrency control in DynamoDB. When doing a PutItem you can define an expression that will be evaluated before
any write happens.
For example, to prevent overrides add an attribute_not_exists(id) condition. If DynamoDB notices that an item with this key already exists then it will
abort the operation.

Apart from existence check, conditions can check any attribute of the check. A canonical example is a bank transfer: the PutItem overwrites the item so
it's essential to check that the balance is not changed in the meantime.

This is called optimistic concurrency control: optimistic because it assumes that most of the time there are no concurrency errors. The other approach is called pessimistic concurrency control and that is what SQL-based databases use and relies on locking of rows and tables.
UpdateItem/DeleteItem
The UpdateItem operation is similar to the PutItem but it supports an update expression. This expression can define how to change an existing
attribute, such as "add 1 to this field" or "remove this item from a set".

To delete an item, use the DeleteItem with the key of the item to delete.

Both operations support conditions.
Scan
The Scan is the simplest way to read multiple items from a table. It goes through all items and returns them.

Pagination
Since the result of the Scan can be large, it might not be able to return all items in one go. Because of this, it is a paginated operation.

There are two types of pagination: offset-based and token-based. Offset-based is what SQL uses as it supports the OFFSET and the LIMIT keywords in
the queries. The result will skip the OFFSET amount of items, then returns up to the number in LIMIT.
DynamoDB on the other hand, uses tokens. If an operation does not reach the end of the table, it returns a next token. To fetch the next page, do the operation again and pass the previously received token. When there are no more items, the operation will return no token.

Scan anti-pattern
Using Scan is usually a pitfall as it behaves differently when the table has only a few items than when it has many. A small table is easily enumerated:
especially when all the items fit into a single page it is constant-time. But as the number of items grows so is the required number of requests to fetch all of
them.
During development, tables tend to be small: a couple of test data just to verify functionality. This makes it hard to spot that under the hood full table scans are happening. But as users start to use the product and accumulate some data, this quickly becomes the bottleneck.
When it's OK to use Scan?
For top-level entities that don't naturally belong to other entities, Scan is the way. Usually, in a multi-tenant system the top-level entity is the
tenant, usually called a customer or user.
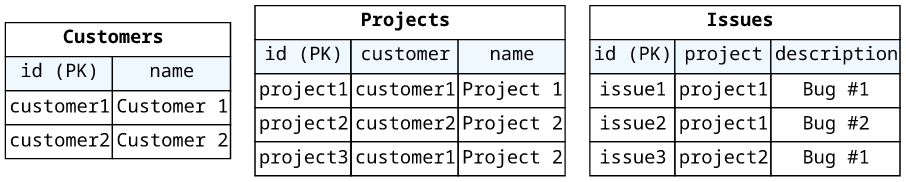
As an example, an issue tracker might have project and issues for each customer so that issues belong to projects and projects belong to customers. In this
case, the customer table holds top-level entities so whenever it's needed to enumerate customers, for example for a customer-service agent, it's OK to
Scan.
Query
The other way to get multiple items from a table is to use a Query. In DynamoDB, Query is one very specific operation and it is nothing like SQL
queries.
To understand how to query a DynamoDB table, we need to talk about composite keys first.
Composite key
Every item in a table needs a unique key. In the previous examples, that was one of the attributes of the item, called the partition key. This is the needed to get, put, update, and delete the item.
To enable queries, DynamoDB supports defining a key as a composition of 2 attributes: the partition key and the sort key. They form the key of the item together, which means that multiple items can have the same partition key as long as their sort keys are different.

When a table defines a composite key then all operations that require a key (GetItem, PutItem, DeleteItem, UpdateItem from above) need
to get both the partition key and the sort key.
Querying for composite keys
The Query operation returns items with a given partition key.
For example, in the customer-project-issue database the projects might be defined as customerid as the partition key and projectid as the sort key.
In this case, it is possible to get all projects belonging to a given customer.

The results are ordered by the sort key and the Query can define limits (greater than, lower than, between) as well as whether it needs the results in
ascending or descending order.
For example, if the issues are stored with projectid as the partition key and date as the sort key then it is possible to get the last N
issues for a specific project, and also to get issues for a specific day.

The Query is the best-practice counterpart of Scan. While the result of the Scan increases with every item put into the table, the result of
the Query increases only with the items with the same partition key. With the right data model an application can scale to practically infinity.

Query is a paginated operation.
Secondary indices
Notice that the structure of the table determines the Query that is possible. In the above example, the Issues table supports only getting issues
for a project ordered by the issue date. What if the backend needs to show issues assigned to a given user? That would require a table with the partition key as
the user's ID.
To support multiple types of queries on a single table you can define secondary indices. How they work is that they automatically replicate the data to a virtual table that has a different key configuration. The base table can be queried by the project, then the index supports querying by the user, for example.

DynamoDB manages the data in the index so you only need to define the key structure. This makes the process almost transparent: there is a replication lag so that a recently changed item might not be available in the index.
Transactions
The operations that change items (PutItem, UpdateItem, DeleteItem) are item-based. That means one operation can only change a single item, and
also any condition that is present in the request can only access the attributes of a single item.
This makes them unable to handle scenarios such as "decrease funds from this account and increase the funds on that other account" or "add a new customer but make sure that its name is unique". For these, DynamoDB supports transactions.
Transactions contain multiple item-level operations that are applied atomically. Each operation can modify an item with the ability to check conditions and if any of these conditions fail then all operations in the transaction fails.
A canonical example is keeping accurate counts. Since DynamoDB doesn't have a count(*) other than iterating over the whole table, to implement this we
need a separate counter item. Whenever the number of items it counts changes the transaction also needs to include an extra update. Since the two modifications
are run in an atomic way, this makes sure that the counter is accurate.


Transactions can have ConditionCheck elements that are only there for to check a condition. For example, to implement a foreign key constraint whenever a
dependent item is added the operation needs to check whether the parent entity exists.

When used correctly, transactions are the cornerstone of keeping the database in a consistent state.

