
Fooled by encryption
"Is it encrypted?" is not the right question to ask


Thinking about encryption
When talking about a software architecture I often get this question: "Is it encrypted?". A "No" is the bad answer as everybody assumes that the system is not secure. But after getting a "Yes", everybody just moves on believing that security is top-notch and everything is hacking-proof.
But that simple "Yes" hides a lot of complexity. Depending on the details, the actual security can still range from top-notch to terrible.
Let's see two examples!
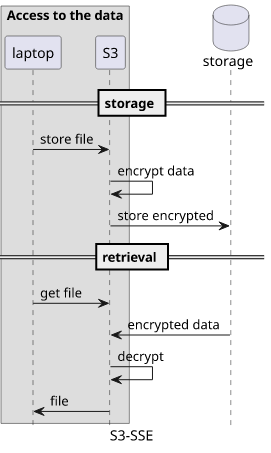
S3 store objects encrypted using a key that AWS manages, an option called S3-SSE. You upload the file, S3 encrypts, then stores it durably. When you download the file, S3 decrypts it and sends it to you. This is called seamless encryption: you don't even see that encryption is happening.
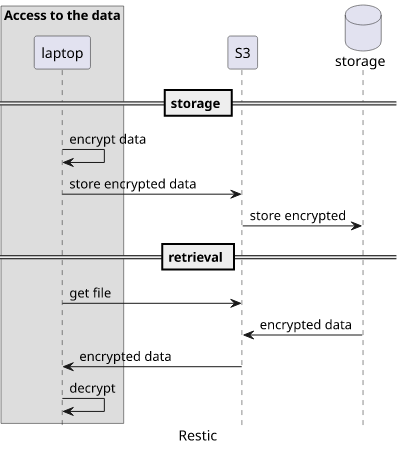
The other end of the spectrum is Restic. It's a backup manager running on your laptop and supports a lot of different backends to store the data, S3 among them. When a backup is performed, Restic encrypts the data locally with a key, then uploads the result to S3. When a file has to be restored, the data is read from S3 and then locally decrypted using the key.
In both cases the answer to the "Is it encrypted?" is "Yes". But in terms of security, the two cases feel entirely different.
In S3-SSE, if an attacker gets a GetObject permission then they can get the data in plain text from S3. Also, as AWS has access to the key they can
look into the data. And since the API only gets and returns non-encrypted data, if AWS chooses one day to turn off encryption altogether, you wouldn't even
notice: everything works the same.

In the Restic case, S3 is untrusted: if everything outside the laptop is compromised the data is still secure. If an attacker can get all the data from the bucket they still won't be able to read the files without the key. Security depends on the key.
A similar complexity arises with end-to-end encryption. Depending on the choice of what the two ends are, e2ee can mean very different things.

Overall, the details around encryption matter a lot: it can go from being useless to a strong pillar of the security of the system. That's why asking "Is it encrypted?" is not enough.

My background
At this point, a disclaimer is in order. I'm not a cryptographer but a developer. My role is not to come up with new encryption schemes or analyze existing ones but to design and implement systems using trusted primitives. I need to be able to decide which algorithm to use, how to implement it correctly, and limit who has access to the key used.
This means I ignore a huge amount of complexity: there is a lot of math behind each of these algorithms. Spotting things like a backdoor-looking bug in Telegram's code that allowed the server to compromise the e2ee or making sure that implementation of the primitives is constant-time are things that I can only marvel at but unlikely to reproduce myself.
On the other hand, encryption has a huge amount of complexity on the abstract level as well. Choosing algorithms, implementing key generation and handling, and using them correctly is within the domain of the general-purpose software development.
So in this article I'll only focus on these higher-level topics and not the math underpinning all of it.
Choose good algorithms
Let's go from the lower-level to the more abstract!
As a developer, the main line of defense is the choice and the implementation of the algorithms. The rule of thumb is simple: use the current best practices. That's AES128 or 256 with GCM for symmetric encryption, SHA256 or 512 for hashing, Argon2 or Scrypt for password hashing.
There are a couple of obviously bad choices here: 3DES, MD5, AES-ECB.
Then there are slightly wrong chocies: SHA1, AES-CBC. For example, while a SHA1 collision was found but that only invalidates some properties of the function but not others. It's still good for hashing files, for example.
But why use an inferior algorithm when a better one is available? Choose SHA256 instead of SHA1 and problem solved, there is no need to keep in mind in which cases SHA1 can be used and which ones it can't.
The safer alternative uses more resources? For an algo that runs only once when the user logs in, for example, it does not matter. Even if it's on a relatively used path, the difference will be unmeasurable. I'm yet to find a case when a real-world application with some backend and frontends are impacted by the speed of the encryption or the hashing. Even low-cost IoT devices are getting powerful enough to run these algos efficiently.
Impetus
What I found is that when people push back against using better algorithms is because of impetus. Somebody already implemented something that uses SHA1, for example, and they will argue that for that specific case it's not a problem. This reasoning hides the complexity of the future: while today the implementation is used in a way that it's OK, but maybe somebody later will have the wrong assumption and use the code in a way that it shouldn't be used.
This is hardcoding assumptions. The function will produce a different output for different inputs but only if the input is not user-controlled. Today it might only be called with files' paths and modification times, which is safe, but in the future someone might use it for file contents that is user-controlled and suddenly this is a vulnerable implementation.
A vivid illustration to this problem is the Ariane flight V88 disaster:
Ariane flight V88[1] was the failed maiden flight of the Arianespace Ariane 5 rocket, vehicle no. 501, on 4 June 1996. It carried the Cluster spacecraft, a constellation of four European Space Agency research satellites.
The launch ended in failure due to multiple errors in the software design: dead code, intended only for Ariane 4, with inadequate protection against integer overflow led to an exception handled inappropriately, halting the whole otherwise unaffected inertial navigation system. This caused the rocket to veer off its flight path 37 seconds after launch, beginning to disintegrate under high aerodynamic forces, and finally self-destructing via its automated flight termination system. The failure has become known as one of the most infamous and expensive software bugs in history.[2] The failure resulted in a loss of more than US$370 million.[3]
What went wrong? They used the module that was written for the Ariane 4 rocket and it had an assumption that one variable will fit into 16 bits that was true for the rocket the code was originally written for but not the new one.
Encoding unnecessary assumptions into the code adds mental overhead that has a continuous cost for anybody who needs to work with it. Choose a good algorithm and make future work a bit easier.
Write correct implementations
Next, implement the algorithms correctly. Most important, read the whole API documentation not just the parts that are enough for the minimal implementation. I often find details that are important but not apparent from just a focused reading.
Generate the IVs properly, don't reuse nonces, (in case of GCM) make sure that the auth tag is stored and verified, add additional data if it makes sense. Things that are obvious after reading how the algorithms work.
Key entropy is a critial but rather obscure challenge. The Debian OpenSSL bug is a good example of this:
the Debian maintainer had inadvertently reduced the number of possible keys that could be generated by a given user from “bazillions” to a little over 32,000.
The problem here is that keys usually "look good". The weak Debian keys have nothing wrong with them; their weakness comes from the fact that it is easy for an attacker to generate them. As a developer, use a good source of randomness.
A more common source of problems is when the key is derived from a password. This is a special case: a low-entropy source is used to generate something that should be high-entropy and an incorrect implementation is not easy to spot. If the password is simply hashed with SHA1 the result looks random but it's still low-entropy. In case of passwords it's important to use a slow hashing algorithm or a hardware security module.
Key access
Going to the architecture level, it's less about the algorithms and more about access to the key itself. First question to ask is: who generates the key? as that party will have access to the data.
In the S3-SSE case, the key generating party is AWS, which means AWS can read the uploaded data. In the Restic case, it's the laptop. As long as that is secure, the storage provider (AWS, for example) has no access to the data.
Next, think about who has access to the key. S3-SSE does not allow getting the key in any ways, so it's only AWS. For Restic backups it's the laptop and whatever has access to the file it's stored.
In a more complex cloud-based application the key might be stored in a database which means that whoever has the necessary access will be able to read the key and this is relatively easy to mess up.
Using AWS-KMS gives stronger guarantees: as it does not allow exporting the key but provides access to the crypto operations such as Encrypt and Decrypt the app has no way to leak the key itself. This makes the key from "known" to "access". If a key is leaked, it can not be revoken, while Encrypt/Decrypt access to the KMS key can be removed, limiting the damage done by a misconfiguration.
The same works in the physical world as well: a smart card or other tamper-proof hardware that contains the key in a way that it can not be extracted. This gives practical benefits: as long as you have the key it's secure as it can not be cloned. This is the best practice for IoT devices as well: a secure element that holds the private keys guarantees that only access to the hardware can make connections to the backend.

Key access also makes a big different between encrypted messengers. Telegram and Signal both use encryption, but the keys for Telegram's cloud chats are known to the server, while keys in Signal are only known to the two participants. Because of this, Telegram backend can read the cloud messages (not secret chats) while Signal backend has no such access.
Authentication
Another big topic is authentication: how does a participant knows it can trust the other end of the channel? The communication is encrypted, but maybe an attacker is doing a man-in-the-middle attack who can intercept and modify the data. With many hops between the sender and the receiver, a sufficiently sophisticated attacker can do that.
When architecting a system it's important to think about what things are trusted (the trust anchors) and how those things can delegate this trust.
TLS
When you open advancedweb.hu the browser needs to verify that it is indeed communicating with the right server. To do this, it has a list of root
certificates that is trusts and with the signing of
certificates this trust can be delegated.
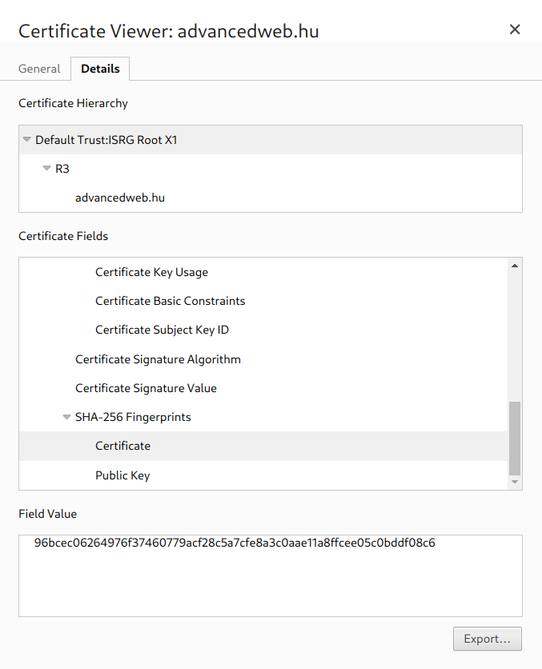
The certificate for the advancedweb.hu domain is signed by R3, which is signed by the ISRG Root X1. This last one is included in the browser
as a root certificate so it is trusted:

DNS
DNS also works by delegating trust: there is a known list of root servers that every resolver needs to hardcode.
The response either contains the data requested (an A record, for example) or a pointer to another name server (NS record). What makes a name server
authoritative (trusted) is that there is a link from a root server to it. That's why you can create DNS zones for any domain you want: it is not used unless the
chain of trust reaches it from the top.
The iterative process can be observed too. Resolving the A record of the advancedweb.hu goes through these stages:
. 22364 IN NS h.root-servers.net.
. 22364 IN NS j.root-servers.net.
...
;; Received 525 bytes from 9.9.9.10#53(9.9.9.10) in 1 ms
hu. 172800 IN NS a.hu.
hu. 172800 IN NS b.hu.
...
;; Received 738 bytes from 192.203.230.10#53(e.root-servers.net) in 1 ms
advancedweb.hu. 7200 IN NS t103.nlg.hu.
advancedweb.hu. 7200 IN NS ns2.nlg.hu.
...
;; Received 601 bytes from 195.111.1.92#53(c.hu) in 111 ms
advancedweb.hu. 86400 IN A 185.199.108.153
advancedweb.hu. 86400 IN A 185.199.110.153
advancedweb.hu. 86400 IN A 185.199.111.153
advancedweb.hu. 86400 IN A 185.199.109.153
...
;; Received 506 bytes from 87.229.45.28#53(t103.nlg.hu) in 113 msFirst, resolver used (9.9.9.10) returns the list of root name servers. Then e.root-servers.net answers with the .hu servers. Then it goes to
t103.nlg.hu, which finally responds with the A records.
IoT
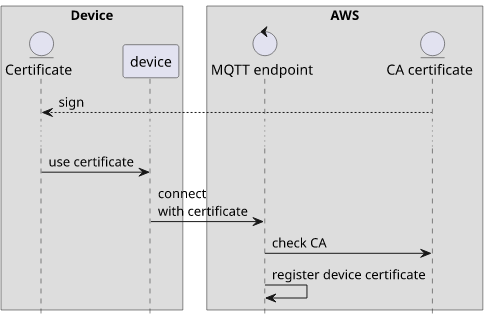
In the world of IoT, the device certificate is added to the backend and that forms the trust anchor. If the certificate is present then the backend allows the connection as it trusts the device.
For JIT (Just in time) provisioning, a certificate that signs the device certificate is added to the backend first. When a connection's certificate is signed by this CA (certificate authority), then it will be trusted even though the device certificate is not added to the cloud.
Messengers
The same happens with messengers as well. Signal, WhatsApp, and Telegram secret chats (among others) use e2e encryption, but by default you need to trust the service itself that it connects you with the intended recipient. To authenticate the connection, you can compare the safety numbers.
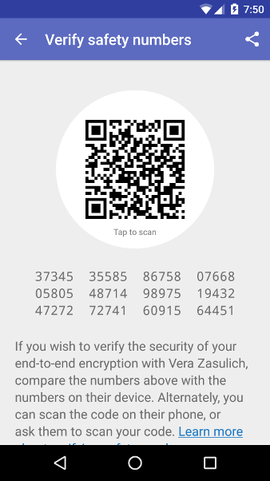
By doing this verification you can make sure that the other end is what you expect it to be and there is no man-in-the-middle attack. An informative quote about the importance of authentication is in the Signal protocol document:
If authentication is not performed, the parties receive no cryptographic guarantee as to who they are communicating with.


{kind=link}