
Designing safer listItems and getItem permissions
When getItem can be implemented based on listItems


When you implement authorization for an endpoint that returns a list of items, there is an optimization that simplifies the policy structure a bit: define only the permission to list but not to get items. This makes it a bit easier for a policy writer to think about permissions as there is less duplication.
For example, in a ticketing system that provides an endpoint to list tickets (/project/project1/tickets) and to get a ticket by ID
(/tickets/:ticketid) both endpoints need an authorization check (can the user list tickets / get this ticket?). If both of them return the same objects
(the full ticket) then only one permission is needed: either allow getting a ticket and then the list endpoint (/project/project1/tickets) only returns
the allowed items, or allow listing the tickets and then the /tickets/:ticketid can authorize whether the ticket can be listed.
This results in either a getTicket or a listTickets permission but not both. This avoids problems like "a user can not list a ticket but if they know
its ID then can still access it" called "insecure direct object references" which is part of #1 on the OWASP
list, and also "the ticket is available via the list endpoint but denied when accessed via the
direct-ID endpoint". Note that this makes policies simpler, but not the backend code.
This took me a couple of detours to notice this pattern and when it can be used. I started with a different problem: how should I define permissions to a list
endpoint? I noticed that if the permission is getTicket then when combined with pagination it exposes information that it should not. Then when I moved to
the direct-ID endpoint I realized that it only works when the information returned by the two endpoints are the same and this is not a generic approach.
An API that better supports authorization would return less data about each item in the list operation and require a call to the direct-ID endpoint for details. But that is not how many existing systems work and so in practice this simplification might be doable.
This article is about this learning process and how I'd design an API that fits better in an authorization system.

Authorizing lists
Let's see the two approaches: defining permissions for the list operation versus for individual items. In this system, each ticket is either sensitive or non-sensitive and users can be restricted to seeing only non-sensitive tickets.
In code, the difference looks like this:
permit (
principal is App::User,
action == App::Action::"getTicket",
resource is App::Ticket
)
when {
resource.sensitive == false &&
resource in App::Project::"project1"
};This translates to: The user has access to a ticket when that ticket is non-sensitive and belongs to project1.
Compare that with this policy:
permit (
principal is App::User,
action == App::Action::"listTickets",
resource == App::Project::"project1"
)
when {
context.sensitive == false
};This means: The user can list tickets for project1 as long as it specifies that the results are non-sensitive.
The first one is more clear and generally a policy-writer would prefer that. But using that has subtle security consequences when that listing endpoint has pagination.
Backend implementation
The example is using the Cedar authorization engine with the first policy:
permit (
principal is App::User,
action == App::Action::"getTicket",
resource is App::Ticket
)
when {
resource.sensitive == false &&
resource in App::Project::"project1"
};In implementation, this looks like this:
// GET /v0/project/:projectid/tickets
const tickets = await getTicketsForProject(projectid);
return tickets.filter((ticket) => {
return isAuthorized(ticket);
});Notice that the authorization check runs for each individual ticket and the API returns only the ones that pass the check.
With pagination
On its own, there is nothing wrong with this code. But let's see how it behaves when we add pagination:
// GET /v1/projects/:projectid/tickets?nextToken=...&limit=...&dateFrom=...&dateTo=...
const {tickets, token} = await getTickets({
projectid,
nextToken,
limit,
dateFrom,
dateTo,
});
return {
tickets: tickets.filter((ticket) => {
return isAuthorized(ticket);
}),
nextToken: token,
}Now this code is not secure anymore and it's not that easy to see why.
This type of pagination is called token-based pagination and it works by returning a nextToken whenever there might be more results the client can fetch. When
the nextToken is nullish then it's guaranteed to not have any more items. This is how
DynamoDB, Slack,
and a lot of other services work.

Pagination combined with a limit and some filters gives a user information about items they are not supposed to access.
Let's see an example!
There are 3 tickets in the system:
- day 3, non-sensitive
- day 10, sensitive
- day 20, non-sensitive
Sending a request to fetch the tickets and everything works as expected:
// GET /v1/project/project1/tickets
{
tickets: [ticket1, ticket3]
}But notice what happens when there is a limit=1:
// GET /v1/project/project1/tickets?limit=1
{
tickets: [ticket1],
nextToken: "token1"
}
// GET /v1/project/project1/tickets?limit=1&nextToken=token1
{
tickets: [],
nextToken: "token2"
}
// GET /v1/project/project1/tickets?limit=1&nextToken=token2
{
tickets: [ticket3],
nextToken: "token3"
}
// GET /v1/project/project1/tickets?limit=1&nextToken=token3
{
tickets: []
}Notice the second response: it is empty but there are more tickets. This gives information to the user that there is something there that was filtered out.
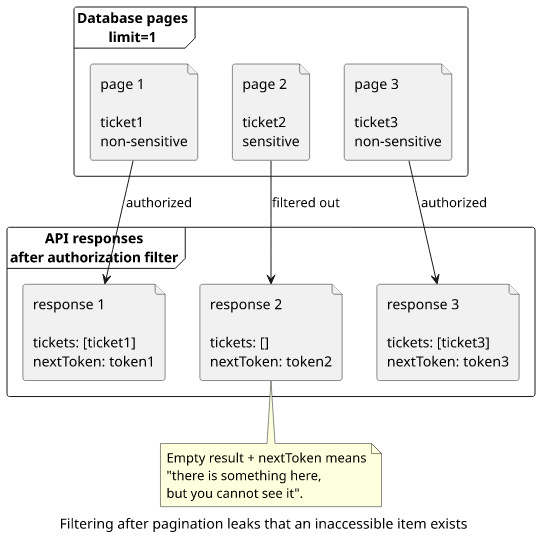
Let's combine it with a date filter!
// GET /v1/projects/1/tickets?limit=1&dateFrom=2026-01-04T00:00:00.000Z&dateTo=2026-01-12T00:00:00.000Z
{
tickets: [],
nextToken: "..."
}
// GET /v1/projects/1/tickets?limit=1&dateFrom=2026-01-04T00:00:00.000Z&dateTo=2026-01-09T00:00:00.000Z
{
tickets: []
}
// GET /v1/projects/1/tickets?limit=1&dateFrom=2026-01-09T00:00:00.000Z&dateTo=2026-01-11T00:00:00.000Z
{
tickets: [],
nextToken: "..."
}
// GET /v1/projects/1/tickets?limit=1&dateFrom=2026-01-09T00:00:00.000Z&dateTo=2026-01-10T00:00:00.000Z
{
tickets: []
}So the date of the sensitive ticket is 2026-01-10. We could even go more precise with some binary searching inside that day. This is because it is possible to
detect that something is missing. And adding more fields to filter on discloses more and more information about these missing items.
Note that while this example uses token-based pagination, offset-based pagination (where a client defines how many items to skip) has the same problem. This is
because authorization check happens after the database returns a list of items. So no matter what you do, if the client can define a limit and gets fewer
results it can get information it shouldn't have.
It is tempting to solve this by going back to the database for more items but that then defeats the purpose of the pagination. Imagine a case where none of the tickets is accessible to the user. In this case, every single request would read all of the tickets just to drop them and return an empty list. That would solve the information disclosure problem but then remove the upper cap on the amount of work a request can do.
Can authorization check written in the SQL itself? That way, the database would return the correct list and there is no need to filter after. This works for simple cases, but it's not generic. The policy might be dynamic (think IAM policies) . In practice, Cedar policies offer way more degrees of freedom for the policy writer than what is encodable in SQL.
Checking the listing
So, let's move the authorization to before the database query!
For that, we need to change the permission:
permit (
principal is App::User,
action == App::Action::"listTickets",
resource == App::Project::"project1"
)
when {
context.sensitive == false
};On the backend, the permission check changes:
// GET /v2/project/:projectid/tickets?...&sensitive=false
// sensitive => context.sensitive
if (!isAuthorized({
projectid,
sensitive,
})) {
throw new Error("Unauthorized");
}
const {tickets, token} = await getTickets({
projectid,
nextToken,
limit,
dateFrom,
dateTo,
sensitive,
});
return {
tickets,
nextToken: token,
};This way the database returns only the matching items and there is no filtering.
// GET /v2/project/project1/tickets?sensitive=false&limit=1
{
tickets: [ticket1],
nextToken: "token1"
}
// GET /v2/project/project1/tickets?sensitive=false&limit=1&nextToken=token1
{
tickets: [ticket3],
nextToken: "token2"
}
// GET /v2/project/project1/tickets?sensitive=false&limit=1&nextToken=token2
{
tickets: []
}And when the user tries to get the sensitive tickets, the request is denied:
// GET /v2/project/project1/tickets?sensitive=true
UnauthorizedOf course, it requires the database to be able to filter on these fields. This is a given on SQL-based databases (WHERE ...), but can be tricky in, for
example, DynamoDB that requires an index.

How AWS does this?
Most of the services allow all-or-nothing listing permissions of resources:
Then it has separate get:* permissions to get the actual resource:
- lambda:GetFunction
- kms:Get*
- s3:GetBucket*
In these cases it's not a problem if you disclose the existence of the resource. It's usually not a problem that somebody learns what Lambda functions your account has as long as the details of that function are denied. (Aside: listing of functions returns all environment variables. Secrets shouldn't be stored there)
But when it is important not to disclose existence, AWS does implement the same pattern we've been discussing.
The ListObjectsV2 opertion supports a prefix and
it is exposed in the ListBucket permission under the s3:prefix condition
key. It is then possible to restrict listing to a
directory inside an S3 bucket:
{
"Sid":"statement1",
"Effect":"Allow",
"Action": "s3:ListBucket",
"Resource":"arn:aws:s3:::amzn-s3-demo-bucket",
"Condition" : {
"StringEquals" : {
"s3:prefix": "projects"
}
}
}getById
One change is how a direct get object by ID will be authorized, such as a /tickets/:ticketid endpoint that gets the ID of the ticket and returns the
object. When the policy runs for each ticket, the authorization parameters are filled from the ticket itself:
// GET /v1/tickets/:ticketid
const ticket = await getTicket(ticketid);
// authorize check with
// user: app::User::<userid>
// action: app::Action::getTicket
// resource: app::Ticket::<ticket.id>
if (!isAuthorized({user, action, resource, context, ...})) {
// 403
}else {
return ticket;
}This translates to "can the user view this ticket", which is a rather natural way to think about a getById authorization.
But when the action is listTickets instead, the parameters are scoped to listing the tickets under a project:
// GET /v2/tickets/:ticketid
const ticket = await getTicket(ticketid);
// authorize check with
// user: app::User::<userid>
// action: app::Action::listTickets
// resource: app::Project::<ticket.projectid>
// context:
// - sensitive: <ticket.sensitive>
if (!isAuthorized({user, action, resource, context, ...})) {
// 403
}else {
return ticket;
}This translates to "is there any list that the user has access to that includes this ticket". This is a way more awkward way to think about permission checks.
And this gets worse: what if there are multiple independent way to get a ticket? For example, maybe there are dashboards that list tickets and you want to give access to them along with project-based listing.
In the policies, this would look like this:
permit (
principal is App::User,
action == App::Action::"listTickets",
resource == App::Project::"project1"
);
// or
permit (
principal is App::User,
action == App::Action::"listTickets",
resource == App::Dashboard::"dashboard1"
);Then the getById needs to check both and return the ticket if either passes:
// GET /v2/tickets/:ticketid
const ticket = await getTicket(ticketid);
// authorize check with
// user: app::User::<userid>
// action: app::Action::listTickets
// resource: app::Project::<ticket.projectid>
// context:
// - sensitive: <ticket.sensitive>
const authorizedForProject = isAuthorized({user, action, resource, context, ...});
// authorize check with
// user: app::User::<userid>
// action: app::Action::listTickets
// resource: app::Dashboard::<ticket.dashboardid>
// context:
// - sensitive: <ticket.sensitive>
const authorizedForDashboard = isAuthorized({user, action, resource, context, ...});
if (!(authorizedForProject || authorizedForDashboard)) {
// 403
}else {
return ticket;
}And also: what if there can be many dashboards and the ticket can be added to any of them? That way the authorization check would first find all dashboards with that ticket and then do a separate check for each one of them. It is still possible to implement it correctly, but it takes more and more care.
Why is it so complex?
At this point it felt like I was fighting some force of nature that just did not want to make authorization simple. Is there any reason why a simple Get
permission wouldn't work?
The key point here is that the getById returns the same objects as the list. If there were separate permissions for the two operations then they would lead to subtle errors: the list gives back an item that is not accessible via direct-ID query, or worse, a list would deny but if the user knows the ID then the object is still accessible.
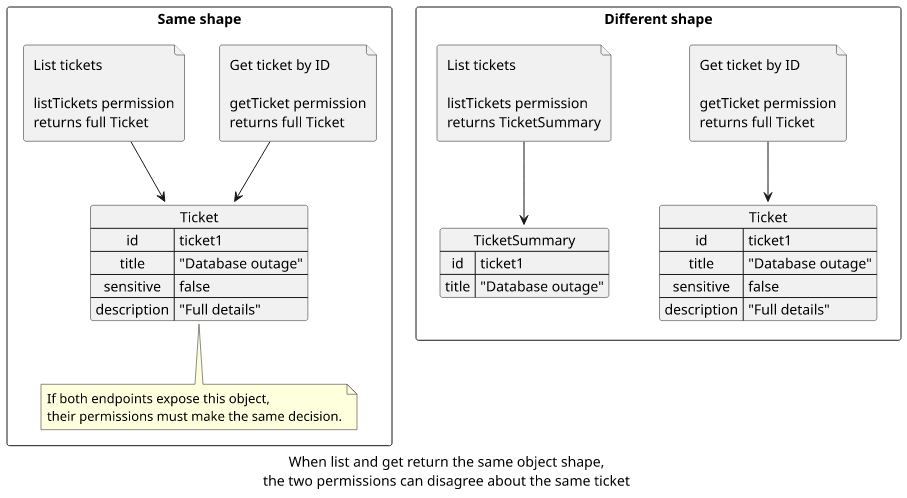
There is a better API design: the list should return a different shape with less data.
For example, S3 ListObjects returns metadata about the
user using the s3:ListBucket permission while the
GetObject returns the contents of the object and checks
the s3:GetObject permission. These are doing different things and should be separate permissions.
Similarly, KMS ListKeys returns only the KeyArn and
the KeyId. Then to get, for example, the public key, you need to use the
GetPublicKey operation. The permissions match the
operations: kms:ListKeys and kms:GetPublicKey.
But in our case, the tickets are returned fully from the list operation and the same objects are returned by the getById. This gives a possible
simplification on the policies: instead of duplicating the permissions (can list non-sensitive tickets and can get tickets that are non-sensitive), we can
add a bit of complexity on the authorization check but get one fewer permission to worry about.
Best practices
So, what are the best practices for designing the API and the authorization?
First, a list operation should check a list permission. The /project/project1/tickets endpoint should require the listTickets permission and it
should not filter the results based on the getTicket permissions.
Second, the list operation should not return whole objects. I find AWS Lambda's
ListFunctions API an anti-pattern: it includes too much data. The environment variables,
the file system configs, the logging configuration, and a lot of other fields are not necessary for listing functions. But because it exposes this information
for all result items, a lambda:ListFunctions permission is broader than necessary.
KMS's API where the list only returns an Arn and a name is better: the client can show a table of keys but it needs more specific permissions to get more information. Also, it makes it a separate decision what extra fields to add to the object and to the listing.
In my case, the API was already designed when I started thinking about authorization so I couldn't easily change the result shape. This was what made it possible to think about whether I could get away with a single permission instead of duplicating to two. But ultimately I find it an anti-pattern to design the API this way.
But third, in case the list returns whole objects, use only policies for the listing. Don't duplicate permissions as they can lead to more subtle security problems and accept the extra complexity on the backend code instead.

