
Integrating Facebook Comment Count Sum
This is a post about summing Facebook comments counts across a site


Recap
In the last article, we covered how to get the comments count for a given Facebook comment box. It is a simple GET request to a Graph API URL, and it's limits are scaling well with visitors, so we don't have to worry about getting capped.
In this article, we cover how to display the sum of the comments for all boxes present on the site.

Overview of the available methods
Naive method
The simplest method is to issue a GET request for each comment box (we know all the boxes' URL in advance), then we aggregate it with Javascript. The drawback with this is that if we have n boxes, then we need to issue n requests for a pageview.
Using Graph API Batch requests
Luckily, Facebook offers support to batch requests in packs of 50, and that seriously cuts off the needed requests. This works by issuing a multipart POST with a batch that contains a JSON array of the required operations. Then the response will be the aggregated responses for each request.
This should be a correct solution, sadly it does not work in our case. The batch API requires an access token to present in the request, even though none of the part operations require it. Since we don't login users yet, we don't have an access token, so we can't issue a batch request.
Using server-side logic
That would be another good solution, just fetch the counts on the server, update it periodically and the clients won't need to handle it. This might be a preferred solution to some, but it is less scalable then solving it on the client-side.
Analyzing the naive method
In summary, we are left with the first method, issuing a GET request for every comment box and summing client-side. But we are taught to minimize the amount of HTTP requests, as they have many round trips, and have much overhead as each requires a TCP connection to be built, right?
Actually, no.
Analyzing the HTTP overhead
Recent HTTP standards (and most of the browsers are supporting it too) have persistent connections, and tunneling. These two makes sure that issuing many requests to the same host will result in minimal overhead.
HTTP persistent connection allows a TCP connection to remain open after the HTTP request-response cycle. It means that if we made a request, then later we make another one, there is no need for a TCP SYN SYN,ACK ACK handshake, thus greatly reducing the RTT.
HTTP tunneling allows a single TCP connection to simultaneously have multiple HTTP connections. It means that if we have a connection to a host, we can issue several requests to the same host, there will be only 1 TCP connection. This minimizes he overhead, also takes care of the 2 connection/host limit.
SPDY
In 2009 the fine folks at Google started working on a new protocol to enhance HTTP, called SPDY. It came with a promise to speed up the web and implemented several features to this effort. The important here is true tunneling and header compression.
True tunneling means that instead of a FCFS nature of the HTTP tunneling, it gives true multiplexing, so a given request does not need to wait for all the previous to finish. If we issue numerous requests, we'll see the benefit of this.
Header compression is another neat thing. HTTP does have GZIP compression, but it is only for the content of a request. If we have many requests with little payload, the overhead becomes greater. With SPDY, the headers are also compressed, making requests even smaller.
Facebook's SPDY support
If we run a check, we find that Facebook's Graph API does very well support SPDY. It means we have all the goodness we have discussed in the previous topics. Let's see the benefits!
Method to compare HTTP vs SPDY
One way to see the difference between HTTP and SPDY is to disable Chrome's support for SPDY and compare the results. But it would yield suboptimal results, as it would really compare HTTPS vs SPDY. The way I compared them is with a little NodeJs server that listens on a HTTP port and pipes the requests to the Graph API.
The server's code is just an express server:
'use strict'
var express = require('express');
var app = express();
var request = require('request');
app.use(express.bodyParser());
app.use(express.urlencoded());
app.get('/getcomments', function(req, res){
res.header('Access-Control-Allow-Origin', '*');
res.header('Access-Control-Allow-Methods', 'GET');
request('https://graph.facebook.com/v2.2/?fields=share{comment_count}&id='+encodeURIComponent(req.query.id)).pipe(res);
});
app.listen(3000);Then, with chrome, I used these scripts:
for(var i=0;i<60;i++){$.get('https://graph.facebook.com/v2.2/?fields=share{comment_count}&id='+encodeURIComponent('http://index.hu'))}for(var i=0;i<60;i++){$.get('http://localhost:3000/getcomments?id='+encodeURIComponent('http://index.hu'))}Then I monitored the Network tab for timings, and used Wireshark to analyze the amount of bytes transmitted on the wire.
Timing differences
The first thing I saw is the difference in timings. With SPDY, the requests were dispatched in parallel, so all round trips lengths almost the same:
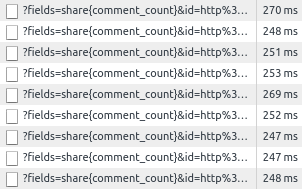
On the other hand, piping through HTTP gave an ever increasing blocking time for each consecutive request:
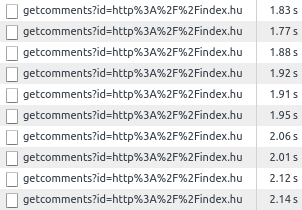
Based on these, if we dispatch numerous requests over SPDY simultaneously, it does not slows down the processing, as it scales well.
Size differences
Chrome Dev Tools does not help much with the actual bytes transferred, as it does not take into consideration the header compressions, nor the TCP overhead. Luckily, we have Wireshark that does counts the actual bytes transferred. There are many unknown factors that shape the exact bandwidth needed, so I've run a few tests and averaged.
For HTTP, it varied between 107 - 111K, that gives an average of 1.82K / request.
For SPDY, it varied between 69 - 74K, that gives an average of 1.19K / request.
That gives a reduction of 34% in request sizes when using SPDY.
Conclusion
This analysis gives an interesting result: from the transport layer, there is no need for a batch request to sum the comment counts. The naive method has some drawbacks but it is actually far less worse than one might think it is, thanks to modern standards and browsers.
The drawback is the scaling. Using this method increases the amount of bandwidth needed to show every single page by 1.19K * the number of posts. If you have hundreds of posts, this is an issue, and you need another way to have the sums. But as long as it is only on the tens scale, this should be no problem.
Also, keep an eye on the Graph API limits. If there is people who navigates a lot on your site, they can reach the limits, and then they (but only they) won't see the counts nor the sums.

