
How to use the aws_apigatewayv2_api to add an HTTP API to a Lambda function
Learn how to use AWS HTTP APIs to easily expose a Lambda-backed API


API Gateway HTTP APIs
The AWS API Gateway HTTP APIs, a simplified version of the REST APIs, recently went GA and offer a lot of improvements over the current Lambda integration solution. With Terraform support for the new resource type, it's time to see how it works and how simple it got to add an API to a Lambda function.
The new API requires only 2 resources, the API itself and a permission to invoke the function:
# Lambda function
resource "aws_lambda_function" "lambda" {
# ...
}
# HTTP API
resource "aws_apigatewayv2_api" "api" {
name = "api-${random_id.id.hex}"
protocol_type = "HTTP"
target = aws_lambda_function.lambda.arn
}
# Permission
resource "aws_lambda_permission" "apigw" {
action = "lambda:InvokeFunction"
function_name = aws_lambda_function.lambda.arn
principal = "apigateway.amazonaws.com"
source_arn = "${aws_apigatewayv2_api.api.execution_arn}/*/*"
}As a comparison, the same with a REST API needs a lot more resources:
aws_api_gateway_rest_api
aws_api_gateway_resource
aws_api_gateway_method
aws_api_gateway_integration
aws_api_gateway_deployment
aws_lambda_permissionWith HTTP APIs all that boilerplate is hidden behind a quick-start config that takes care of setting up the trivial stuff. If you want to use something more advanced, such as JSON models or an authorizer, you can configure those too.
I've always felt that I just need one simple feature and I can do anything else in code. That simple thing is to give me a URL that calls the function. With REST APIs that core functionality requires too much boilerplate. Now with HTTP APIs that got a lot easier.
But this simplification comes with changes that affect how to properly use the new type of APIs and how to integrate with other services.

Name attribute
There are only two moving parts required for an HTTP API: the ARN of the Lambda function and a unique name for the API.
The AWS Terraform provider is inconsistent when resource names are required and when they are optional. For example, an S3 bucket will be named something
unique and random if the argument is missing. Others, such as the aws_apigatewayv2_api, require a name.
I prefer when a resource does not require a parameter like this. The problem with names is that they must be unique and the deployment fails when there is
a collision. An auto-generated name handles this by default, but when it must be provided it's tempting to hardcode something in the config. But with a fixed name,
the same stack can not be deployed to the same region and possibly to the same account more than once at a time. AWS throws a ResourceConflictException
when there is a collision.
Fortunately, the random_id resource can help by generating a unique string for each deployment.
This reproduces how an optional resource name works.

resource "random_id" "id" {
byte_length = 8
}
resource "aws_apigatewayv2_api" "api" {
name = "api-${random_id.id.hex}"
# ...
}Troubleshooting
My first experience with the simplified HTTP API was how hard it is to know what went wrong. On the first try, I got an "Internal server error", and no other clue. Logging in to the Console, I saw the request did not reach the Lambda as no log entries were in the function's log. And after activating the request logging all I saw was 500 errors without explanation.
What helped eventually was the usual trick to debug IaC: creating a new API manually using the Console and comparing the two to find what difference might result in the errors I'm seeing. Eventually I figured there was an error with the Lambda permission and the API started working after I fixed that.
Apart from the catch-all "Internal server error", I encountered "Not Found" errors also. These happen when there is a problem with the routes and the API does not match the request URL.
A longer-term problem is that it's near impossible to google its name as it's too generic. This makes it especially hard to find solutions for known problems.
And not just because of the naming, but the official documentation meshes the API Gateway HTTP API with the REST API which makes it hard to find examples specifically for the former.
Lambda payload format version 2.0
With the new API comes a new Lambda payload format. This defines the event argument of the function and the required elements in the output. Fortunately,
the old format is still supported, so an existing function can still be used with the new API without rewriting it. But new functions should use the new one.
The changes in the output format are the easier to cover as it only got easier. If you want to return a JSON, you no longer need to specify the statusCode and
the Content-Type boilerplates as those will be automatically set to 200 and application/json, respectively.
module.exports.handler = async (event, context) => {
return {
some: "result",
};
};Of course, you can overwrite them if you need, making this change backwards-compatible.
The input format, on the other hand, is changed in non-backwards compatible ways. The documentation offers an example where it's easy to compare the two formats.
Most of it is moving parameters around, such as the event.path which is now at event.requestContext.http.path and the event.httpMethod is moved
to event.requestContext.http.method.
Another useful change is the first-class handling of cookies. The event.cookies contains the cookies sent with the request and the cookies
property in the response is automatically converted into set-cookie headers.
A less used but no less impactful change is how duplicate headers and query parameters are sent to the Lambda function. These are no longer parsed for you
but simply concatenated with commas. A possible problem is that these are not escaped in any ways, so a query with ?a=b,,&a=,c will be sent as:
"queryStringParameters": {
"a": "b,,,,c"
}If that can be a problem, the rawQueryString contains the unprocessed query from where you can extract the values correctly.
$default stage and route
With the new $default stage the domain name is finally enough to call an API and there is no need to pass the stage name around too.
Before the $default stage, the URL consisted of the domain and a stage (https://<api_id>.execute-api.<region>.amazonaws.com/<stage>/)
and the root path does not reach the API. Now with $default specified as the stage name, the request to https://<api_id>.execute-api.<region>.amazonaws.com/
is handled by that stage.
As this simplifies the URL it makes the integration easier with other services. For example, the origin_path argument is not needed when using
CloudFront.
Apart from the $default stage, there is also a $default route that simplifies catch-all path patterns. This is similar to the {proxy+} construct
but it handles the root pattern also. With a REST API, if you wanted to handle both <url>/stage/ and <url>/stage/path you'd need to use
an additional resource under the root and two methods and two integrations:
# handle /*
resource "aws_api_gateway_resource" "proxy" {
parent_id = "${aws_api_gateway_rest_api.rest_api.root_resource_id}"
path_part = "{proxy+}"
# ...
}
resource "aws_api_gateway_method" "proxy" {
resource_id = "${aws_api_gateway_resource.proxy.id}"
# ...
}
resource "aws_api_gateway_integration" "lambda" {
http_method = "${aws_api_gateway_method.proxy.http_method}"
# ...
}
# handle /
resource "aws_api_gateway_method" "proxy_root" {
resource_id = "${aws_api_gateway_rest_api.rest_api.root_resource_id}"
# ...
}
resource "aws_api_gateway_integration" "lambda_root" {
http_method = "${aws_api_gateway_method.proxy_root.http_method}"
# ...
}That's a lot of boilerplate copy-pasted whenever a new API is needed. With the $default route, all this is gone.
Price
Compared to the REST APIs, HTTP APIs are cheaper and quite significantly so. The starting price is $1 per million requests, while the same is $3.5 for REST APIs. It's a significant reduction but of course, the actual impact is dependent on the ratio of this cost item to the overall infrastructure.
But let's see how it compares to the Lambda function that it exposes as an API!
With 128 MB of memory allocated, the function costs $0.2 for every 100 ms it runs per million requests. Apart from that, there is an additional $0.2 / million request cost.
With the HTTP API, $1 / million cost is equal to a function that runs between 300-400 ms. For a REST API, the same function can run for ~1.6 seconds to reach the API's $3.5 / million price tag.
To put it this way: you get a free ~1.2 seconds of runtime for your function (with 128 MB RAM) if you use the new HTTP API.
Speed
With simplified configuration, HTTP APIs also offer less overhead to the request latency, as described in the release announcement.
Faster is always better, but the latency experienced by end-users is affected by a ton of other things too. The Internet is not famous for its low jitter, DNS resolution takes an unknown number of hops, TCP and TLS require roundtrips but their exact number is determined by the protocol used, and also Lambda can spin up a new instance any time which incurs a slow cold start. But the part API Gateway adds to the mix is a bit smaller now.
On a more practical side, HTTP APIs do not support caching and edge optimization. I believe it's not a great loss as you can always add CloudFront manually, which is what "edge optimized" meant anyway, and configure it to provide both. This also gives a bit more control over how things work.
How to use with CloudFront
Since HTTP APIs bring support to the $default stage and a route key that offers fine control over the paths of the API, it changes how it can be
integrated with CloudFront compared to REST APIs.

And because of the way the path_pattern is handled in CloudFront, we need to consider how an HTTP API works with the default cache behavior as well as with
a non-default one.
Default cache behavior
With the $default stage it's enough to define the domain name and there is no need to define the origin_path argument.
resource "aws_apigatewayv2_api" "api" {
name = "api-${random_id.id.hex}"
protocol_type = "HTTP"
target = aws_lambda_function.lambda.arn
}
# ... lambda, permission
resource "aws_cloudfront_distribution" "distribution" {
origin {
domain_name = replace(aws_apigatewayv2_api.api.api_endpoint, "/^https?://([^/]*).*/", "$1")
origin_id = "apigw_root"
# no origin_path is needed for the $default stage
custom_origin_config {
http_port = 80
https_port = 443
origin_protocol_policy = "https-only"
origin_ssl_protocols = ["TLSv1.2"]
}
}
default_cache_behavior {
target_origin_id = "apigw_root"
# ..
}
# ...
}A request to the path https://<url>/testroute has the path properly filled:
{
"requestContext": {
"http": {
"method": "GET",
"path": "/testroute",
},
}
}Ordered cache behavior
The path_pattern is required for a non-default behavior, as this parameter configures the routing between the origins. But this is only used to determine
which behavior to match but the full path is sent to the origin. This messes up the request path the Lambda function sees, as it will get the
requests other than the /.
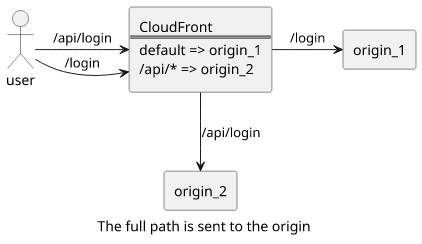
For example, if the path_pattern is /api/* then the function will get /api/login as well as /api/, but never the / or /login.
And if the function expects the requests relative to the root, it won't work.
A trivial solution is to add the path pattern to every path checking in the function's code. This works, but it limits the portability of the code.
A more robust solution is to use Lambda@Edge to cut the routing part of the origin request. This works for all types of origins but it incurs additional costs and complexity.

But with HTTP APIs it's possible to use the route_key to match only paths under the path_pattern. For example, to send only the request under
the /test/ path to the function, use the ANY /test/{proxy+} route key:
resource "aws_apigatewayv2_api" "api-path" {
name = "api-path-${random_id.id.hex}"
protocol_type = "HTTP"
target = aws_lambda_function.lambda.arn
# the route_key includes the path_pattern
route_key = "ANY /test/{proxy+}"
}
resource "aws_cloudfront_distribution" "distribution" {
origin {
domain_name = replace(aws_apigatewayv2_api.api-path.api_endpoint, "/^https?://([^/]*).*/", "$1")
origin_id = "apigw_path"
custom_origin_config {
http_port = 80
https_port = 443
origin_protocol_policy = "https-only"
origin_ssl_protocols = ["TLSv1.2"]
}
}
ordered_cache_behavior {
path_pattern = "/test/*"
target_origin_id = "apigw_path"
# ...
}
# ...
}With the above config, the event object contains the matched part in the pathParameters.proxy property. A request to https://<url>/test/testroute
yields this object:
{
"requestContext": {
"http": {
"method": "GET",
"path": "/test/testroute",
},
},
"pathParameters": {
"proxy": "testroute"
},
}Request path in the Lambda function
To support both cases on the Lambda function's side we need some special care when checking the request path.
The path is either in the requestContext.http.path or in the pathParameters.proxy. To handle both cases, the function has to check the latter
first and fall back to the former:
const realPath = event.pathParameters && event.pathParameters.proxy !== undefined
? `/${event.pathParameters.proxy}`
: event.requestContext.http.path;With this code, it does not matter if the function is reached via a default or a non-default behavior, the realPath will be relative to the correct path.
For example, when mapped to the default_cache_behavior and a request comes to https://<url>/example then realPath will be /example. If
the same function is mapped in an ordered_cache_behavior with a path_pattern of /test/*, a request to https://<url>/test/example, the
realPath will be set correctly to /example.
Conclusion
Overall, I'm happy with the new API type. It makes the common use case easier, faster, and cheaper, which is always a good thing. Now I don't need to copy-paste a screenful of Terraform code to make a Lambda function available via HTTP.
HTTP APIs also have a lot of configuration options but those are optional. You can still configure them to fit a lot of use-cases if you need to, but the common case is now reduced to just a few lines of code.

