How to serve files from an AppSync API using S3 signed URLs
Sign, resolve, and return S3 URLs from AppSync


Files with AppSync
AppSync, as all serverless solutions, builds on the "small and quick" response model. This means the response size and the time it takes to assemble that response is limited in a not-adjustable way. This model does not play well with files that can be arbitrarily large, such as books, videos, or archives. To handle them, we need to rely on a different mechanism: signed URLs.
The idea is rather simple behind signed URLs: the files are stored in a dedicated object store, S3 in the case of AWS, and the API only returns a link to these files signed with keys. This way, since the API does not do anything with files the responses are small and quick and the heavy lifting is moved to the object store. The API still needs to implement access control, but it does not need to handle the bytes themselves.


In an example project, let's build a photo sharing app running on AppSync where users can upload images and then decide which ones to make public!
Here, the first of user1's photos is set to private:
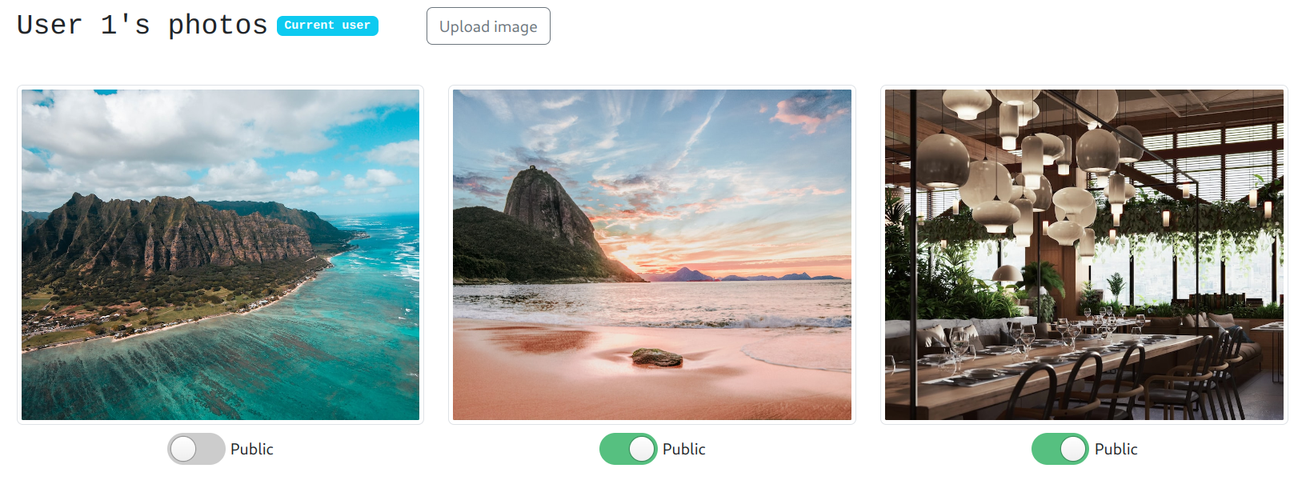
A different user then can't see it:


Implementation
The schema defines that the images have a url field:
type Image {
key: ID!
url: AWSURL!
public: Boolean!
}And images are accessible through a user object:
type User {
id: ID!
username: String!
images(nextToken: String): PaginatedImages!
}
type PaginatedImages {
images: [Image!]!
nextToken: String
}Access control is implemented in the resolver for the User.images. Here, the request only fetches the public images of the user:
export function request(ctx) {
return {
version : "2018-05-29",
operation : "Query",
index: "useridPublic",
query: {
expression: "#useridPublic = :useridPublic",
expressionNames: {
"#useridPublic": "userid#public",
},
expressionValues: {
":useridPublic": {S: ctx.source.id + "#true"},
},
},
};
}There are multiple ways to implement this query, the above one builds on a secondary index. This has the benefit of not leaking information about the number of non-public images, a simple filtering approach would do.

The URL signing is the role of the Image.url resolver. This calls a Lambda function:
export function request(ctx) {
return {
version: "2018-05-29",
operation: "BatchInvoke",
payload: {
type: "download",
imageKey: ctx.source.key,
}
};
}The Lambda uses the AWS JS SDK v3 to sign a GetObjectCommand and return the result:
import {S3Client, GetObjectCommand} from "@aws-sdk/client-s3";
import {getSignedUrl} from "@aws-sdk/s3-request-presigner";
export const handler = async ({imageKey}) => {
const client = new S3Client();
const roundTo = 5 * 60 * 1000; // 5 minutes
const signedUrl = await getSignedUrl(client, new GetObjectCommand({
Bucket: process.env.Bucket,
Key: imageKey,
}), {signingDate: new Date(Math.floor(new Date().getTime() / roundTo) * roundTo)});
return {
data: signedUrl,
};
}Notice that the above code sets the signingDate argument to the nearest past 5-minutes mark. This prevents changing the URL for every request, so that the
browser does not need to download it again and again.

The end result is that the API returns only URLs and the images are downloaded directly from S3: