
How to run a build script with Terraform
Static files are easy to deploy with Terraform. But what about compiled apps?


Terraform build
Terraform is to deploy infrastructure, and as a consequence, it can copy code that does not require compilation. As an illustration, a Lambda function does not even need to be in a separate directory but it can be embedded in the Terraform code.
data "archive_file" "lambda_zip_inline" {
type = "zip"
output_path = "/tmp/lambda_zip_inline.zip"
source {
content = <<EOF
module.exports.handler = async (event, context, callback) => {
const what = "world";
const response = `Hello $${what}!`;
callback(null, response);
};
EOF
filename = "main.js"
}
}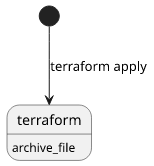
This works as long as you don't need too many files, which point usually comes during the first npm install. But this only changes one parameter of
the archive_file data source:
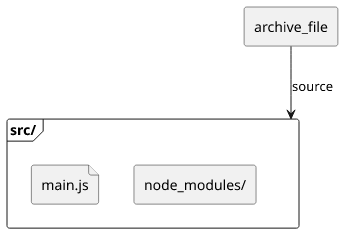
data "archive_file" "lambda_zip_dir" {
type = "zip"
output_path = "/tmp/lambda_zip_dir.zip"
source_dir = "src"
}
But what if the code requires compilation? Let's say you want to use a different language that compiles to Javascript, or, in case of a frontend app, want to use React with JSX?
With the source files:
frontend/package.json
frontend/webpack.config.js
frontend/node_modules/
...Running the build script:
npm run buildGenerates the deploy artifacts:
frontend/dist/index.html
frontend/dist/main.hash.js
...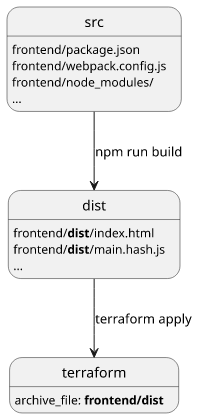
But now you can't just zip a directory with Terraform and expect it to work as it depends on whether the build script (npm run build) is run before that.
Fortunately, there is a way to run scripts from Terraform.

External data source
Terraform offers the external data source which is a configurable gateway between Terraform and the system it's running on. You can define scripts here and as long as they conform to the data source's API, it is considered a first-class citizen.
data "external" "frontend_build" {
program = ...
working_dir = ...
query = {
...
}
}
program attribute
This is the command Terraform runs when it refreshes the state of this data source. Of course, you can not assume that a given program is available
so if you use jq, npm, or anything else, it is still a dependency you need to take care of manually.
The easiest way to specify the command is to invoke bash with it and use the HEREDOC syntax so there is no need to escape quotes:
data "external" "frontend_build" {
program = ["bash", "-c", <<EOT
echo "{\"value\": \"Hello world\"}"
EOT
]
}The result must be written to stdout and it has to be a valid JSON object. Other resources can use the properties:
resource "other" "resource" {
attr = data.external.frontend_build.result.value # Hello world
}Stderr will be printed if the exit code is not 0 (there is an error). This means the original stdout should be redirected so that you'll know what went wrong if there is an error.
The above considerations give a standard structure for the program attribute as:
data "external" "frontend_build" {
program = ["bash", "-c", <<EOT
(command && command && ...) >&2 && echo "<result json>"
EOT
]
}For example, to run npm ci and npm run build then output the destination directory, use:
data "external" "frontend_build" {
program = ["bash", "-c", <<EOT
(npm ci && npm run build) >&2 && echo "{\"dest\": \"dist\"}"
EOT
]
}working_dir attribute
This attribute sets the working directory the program is run. For example, if the frontend project is in the frontend directory, set working_dir as:
data "external" "frontend_build" {
program = ["bash", "-c", <<EOT
(npm ci && npm run build) >&2 && echo "{\"dest\": \"dist\"}"
EOT
]
working_dir = "${path.module}/frontend"
}By using the ${path.module} as a prefix it works both inside modules and top-level configuration files.
Also, the value of working_dir is exported so other resources can depend on it.
Use the result
Other resources in the Terraform file can depend and use the results of the script. In this example, the result is a JSON with the destination directory.
Why output a static value even though it could be specified on the consumers' side?
By using data.external.frontend_build.result.dest, it creates a dependency between the consumer and the external data source, which means there is no
need to use the error-prone depends_on construct.
But there is another catch. Instead of using an absolute path like this:
data "external" "frontend_build" {
program = ["bash", "-c", <<EOT
# Wrong: don't return an absolute path!
(npm ci && npm run build) >&2 && echo "{\"dest\": \"$(pwd)/dist\"}"
EOT
]
working_dir = "${path.module}/frontend"
}
resource "other" "resource" {
attr = data.external.frontend_build.result.dest
}Output a relative path, relative to the working_dir attribute and combine the two on the consumers' side:
data "external" "frontend_build" {
program = ["bash", "-c", <<EOT
# Relative to working_dir
(npm ci && npm run build) >&2 && echo "{\"dest\": \"dist\"}"
EOT
]
working_dir = "${path.module}/frontend"
}
resource "other" "resource" {
# combine the path parts
attr = "${data.external.frontend_build.working_dir}/${data.external.frontend_build.result.dest}"
}Why?
In the first case, the state file will contain the full path, which is different for different environments. Using a relative path makes sure that the state file is not machine-dependent.
query attribute
So far we've covered how to run a script and how to use its outputs. Let's consider the last missing piece: how to provide input parameters?
To pass attributes, use the query:
data "external" "frontend_build" {
# program, working_dir
query = {
param = "Hi from Terraform!"
}
}The structure gets passed via the standard input as a JSON, which can be parsed with tools such as jq. For example, to pass values to a Webpack build:
data "external" "frontend_build" {
program = ["bash", "-c", <<EOT
(npm ci && npm run build -- --env.PARAM="$(jq -r '.param')") >&2 && echo "{\"dest\": \"dist\"}"
EOT
]
working_dir = "${path.module}/frontend"
query = {
param = "Hi from Terraform!"
}
}Of course, outputs of other resources can also be input parameters:
data "external" "frontend_build" {
program = ["bash", "-c", <<EOT
npm ci >&2 && npm run build -- --env.BACKEND_URL=$(jq -r '.backend_url') >&2 && echo "{\"dest\": \"$(pwd)/dist\"}"
EOT
]
working_dir = "${path.module}/frontend"
query = {
backend_url = aws_api_gateway_deployment.deployment.invoke_url
}
}But in this case, there is a gotcha. Since Terraform does not know the number of files if it depends on resources, a for_each over the output files
will yield an error:
resource "aws_s3_bucket_object" "frontend_object" {
for_each = fileset("${data.external.frontend_build.working_dir}/${data.external.frontend_build.result.dest}", "*")
# ...
}When trying to deploy with the command:
terraform applyWill not work:
Error: Invalid for_each argument
on main.tf line 73, in resource "aws_s3_bucket_object" "frontend_object":
73: for_each = fileset("${data.external.frontend_build.working_dir}/${data.external.frontend_build.result.dest}", "*")
The "for_each" value depends on resource attributes that cannot be determined
until apply, so Terraform cannot predict how many instances will be created.
To work around this, use the -target argument to first apply only the
resources that the for_each depends on.In this case, you can do a 2-step deployment by specifying a -target argument for the terraform command:
terraform apply -target data.external.frontend_buildThis deploys everything up to the build so that the number of files is now known for the next terraform apply.
Advantages
Should you use Terraform to run external build scripts? Embedding the build scripts this way has the nice property that after a git clone you
can jump straight to deploy, no need to run anything else by hand.
It also makes sure that everything that requires building is built before calculating what to deploy, which prevents accidentally overwriting a live resource with older code.
Also, as you can pass arguments via the query object that depends on other resources you can bake state-dependent information into the built artifacts.
For example, the frontend code knows the backend URL without resorting to fetching a configuration object or passing a query parameter on runtime.
Drawbacks
The obvious drawback is speed. If you have a build process like this it will be run for every state refresh, making that considerably longer than before.
30-60 seconds of compilation time is not unheard of and waiting an extra minute for every terraform plan can impact developer productivity.
Also, 2-step deployment is a pain. On the other hand, that is extra functionality that you wouldn't have without running the build from Terraform.

