
How to deploy a single-page application with Terraform
Build with Webpack and deploy with Terraform


SPA with Terraform
As covered in the previous article, Terraform can run a build script as part of the state refresh process,
i.e. during terraform plan and terraform apply. This capability
opens the way to automatically compile a project in a way that is fully integrated with other resources. You can integrate Webpack that builds a React app,
compile Typescript or CoffeScript, and many more scenarios become possible without an additional build step.
Just a terraform apply and everything is built and deployed.

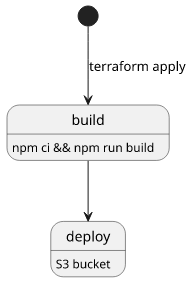
But that is only the first half of deploying a single-page application. Running the build scripts generates the static files, now let's see how to deploy them into an S3 bucket!
In this example, the frontend application is a React app built with Webpack in the frontend directory. The build is run by an npm ci followed by
an npm run build, where we can also pass parameters from Terraform with the -- --env construct.

data "external" "frontend_build" {
program = ["bash", "-c", <<EOT
(npm ci && npm run build -- --env.PARAM="$(jq -r '.param')") >&2 && echo "{\"dest\": \"dist\"}"
EOT
]
working_dir = "${path.module}/frontend"
query = {
param = "Hi from Terraform!"
}
}The compiled files are placed to the dist folder and the data source outputs its name.
Let's see how to use the resulting files!

Frontend bucket
First, we need a bucket to store the files:

resource "aws_s3_bucket" "frontend_bucket" {
force_destroy = "true"
}The way files are served to the end-user can be one of several approaches which is out of scope for this article. The easiest way is to configure a bucket website, but that is unsuited for a production environment on its own due to a lack of HTTPS support. A better solution is to use a CloudFront distribution with an S3 origin to serve the app as static files.
Bucket objects
With the frontend_build external data source, the destination directory is accessible on
the "${data.external.frontend_build.working_dir}/${data.external.frontend_build.result.dest}" path. Since this explicitly depends on the data source
itself (it uses the result object), the build is guaranteed to be run. To upload the files Terraform offers
the aws_s3_bucket_object resource which can be combined with the fileset function,
which is a new addition to Terraform, to iterate over the files.
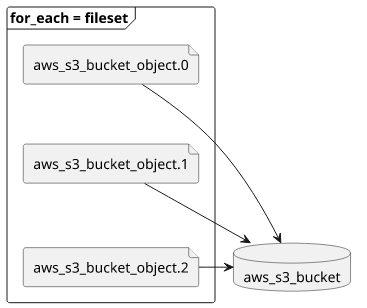
With a for_each it can generate a resource for every file found in the directory:
resource "aws_s3_bucket_object" "frontend_object" {
for_each = fileset("${data.external.frontend_build.working_dir}/${data.external.frontend_build.result.dest}", "*")
key = each.value
source = "${data.external.frontend_build.working_dir}/${data.external.frontend_build.result.dest}/${each.value}"
bucket = aws_s3_bucket.frontend_bucket.bucket
etag = filemd5("${data.external.frontend_build.working_dir}/${data.external.frontend_build.result.dest}/${each.value}")
content_type = lookup(local.mime_type_mappings, concat(regexall("\\.([^\\.]*)$", each.value), [[""]])[0][0], "application/octet-stream")
}In a for_each, the each.value contains the filename, which is the perfect candidate for the key attribute and along with the directory
it identifies the source file.
Also, as these resources use the output of the data source there is a direct dependency between them. There is no need for depends_on attributes.
etag
As with all resources, Terraform runs an update only when an attribute is changed. This is why, for example, you need to define the source_code_hash
attribute for Lambda functions.
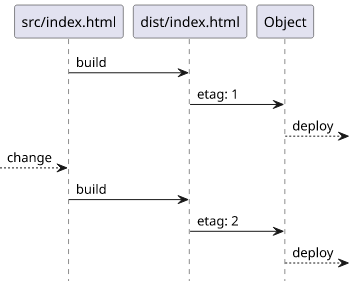
Similarly, since the filename might not change when the file itself is updated, a similar mechanism is needed here. In this case, it's called etag,
but it works just the same:
resource "aws_s3_bucket_object" "frontend_object" {
# ...
etag = filemd5("${data.external.frontend_build.working_dir}/${data.external.frontend_build.result.dest}/${each.value}")
# ...
}The filemd5 calculates a hash of the parameter file and that will be the etag of the object. When the file changes, the hash changes and, in turn,
Terraform updates the resource.
content_type
Without a proper content type set for the objects, they are downloaded but not shown. To make the frontend app work, we need to set it too for each object.

I tried to find a more robust way to do this but it seems no module gives back the mime type for a given file. That means I had to resort to a lookup table that maps extension to content types:
locals {
# Maps file extensions to mime types
# Need to add more if needed
mime_type_mappings = {
html = "text/html",
js = "text/javascript",
css = "text/css"
}
}
resource "aws_s3_bucket_object" "frontend_object" {
# ...
content_type = lookup(local.mime_type_mappings, concat(regexall("\\.([^\\.]*)$", each.value), [[""]])[0][0], "application/octet-stream")
# ...
}Of if you prefer an error if an extension is missing from the mime_type_mappings, use:
resource "aws_s3_bucket_object" "frontend_object" {
# ...
content_type = local.mime_type_mappings[concat(regexall("\\.([^\\.]*)$", each.value), [[""]])[0][0]]
# ...
}This is hardly an optimal solution, but it works.
Conclusion
With the help of the external data source and the fileset function, Terraform can compile an app and upload it to an S3 bucket from where the frontend
application can be served. All this while maintaining the integrity of the state and making sure the app is always up-to-date.

