
How to route to multiple origins with CloudFront
Set up path-based routing with Terraform


Routing with CloudFront
Recently I got a question about Cloudfront where there were multiple backends and the asker wanted to bring everything under a single distribution. I then realized that AWS's naming does not help much in this case. The different backends are called origins which is plausible if you consider that is the origin of the data. But then where to set up path-based routing? Exactly, that is (partially) what cache behaviors are good for.
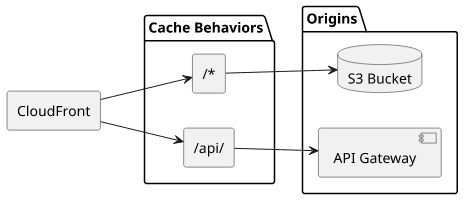
With path-based routing, you can cover a lot of different use-cases. One particularly common is to serve static assets from an S3 bucket and use API Gateway for
dynamic content under /api/:
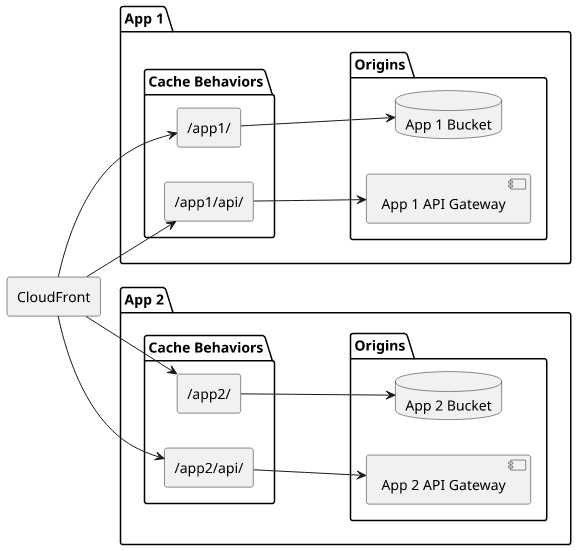
But with a different setup, you bring multiple applications under a single domain. This example routes /app1/ to the first app with its own API and /app2/
to the second one, with a separate API:
Or you can host multiple APIs under different paths for a single app:
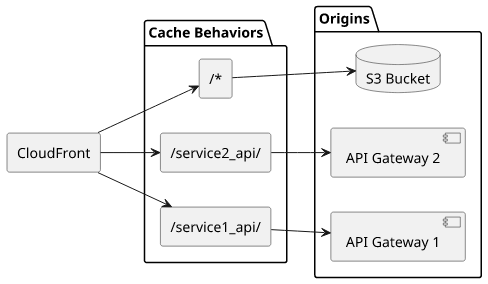
These are just some examples of how to use CloudFront as an aggregator for all the other pieces of architecture.


Advantages
Since all other pieces (S3 bucket, API Gateways, EC2 instances) have their own URLs, why should you use CloudFront in front of them? After all, deploying it is a nightmare with its 20-minutes-long waiting cycle.
But architecturally, it brings a lot of benefits placing a distribution in front of the other resources.
It brings everything under a single domain, so you don't need to worry about CORS errors.
It makes your application faster. It can cache static content, it uses HTTP2, and it can reuse the origin connection, speeding up even non-cacheable requests. It is also cheaper.
And finally, the location configuration is at CloudFront, this means you don't need to tell the clients where to find the APIs.

Origins and Cache Behaviors
In CloudFront's terms, you'll need to define an Origin for each backend you'll use and a Cache Behavior for each path.
This separation helps when you want to define multiple behaviors for a single origin, like caching *.min.js resources longer than other static assets.
For this use-case, you define a single origin (for example, an S3 bucket) and define a behavior for minified assets (*.min.js) with a cache TTL
set to a long time, and a default behavior (*) with short TTL.
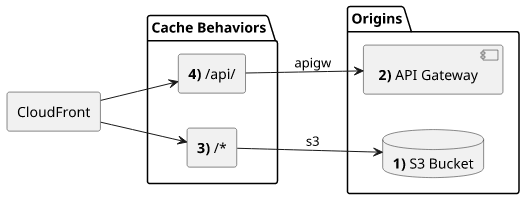
Path-based routing example
Let's see an example of how an assets - API separation would look like in Terraform! We have an S3 bucket with the static assets and an API Gateway that serves
the dynamic content. The API will be accessible under /api/ and outside that path will be the bucket's contents.
Origins
Origins are the backend configuration for CloudFront, they describe how to grab the content. To wire them to cache behaviors they have an origin_id that
acts as an identifier.

1) S3 origin
For an S3 origin, you need the domain name of the bucket and optionally (but recommended) an Origin Access Identity.
resource "aws_cloudfront_distribution" "distribution" {
origin {
domain_name = "${aws_s3_bucket.bucket.bucket_regional_domain_name}"
origin_id = "s3"
s3_origin_config {
origin_access_identity = "${aws_cloudfront_origin_access_identity.OAI.cloudfront_access_identity_path}"
}
}
# ...
}Two things to notice here. First, the bucket_regional_domain_name (<bucket>.s3-eu-west-1.amazonaws.com) is the preferred way over bucket_domain_name
(<bucket>.s3.amazonaws.com). You might see the latter is also working, but it is not guaranteed for all regions. Also, it takes some time to propagate the DNS so the regional endpoint is simply faster.
The second is the Origin Access Identity that grants bucket read access but only if accessed through CloudFront. While it does not seem a big security gain, it's best practice to lock down non-intended routes.
2) API Gateway origin
The API gateway is a custom origin, which is any regular HTTP endpoint. As such, it requires some extra configurations:
origin {
domain_name = replace(aws_api_gateway_deployment.deployment.invoke_url, "/^https?://([^/]*).*/", "$1")
origin_id = "apigw"
custom_origin_config {
http_port = 80
https_port = 443
origin_protocol_policy = "https-only"
origin_ssl_protocols = ["TLSv1.2"]
}
}The domain_name is a bit tricky here as the invoke_url contains both the scheme (https://) and the stage name but CloudFront accepts only
the domain. The replace function extracts the domain from the URL.
Another thing is the custom_origin_config where the above 4 are all required parameters. Even though https-only is specified, you need to specify
the HTTP port.
You can also specify the origin_path which gets appended to the domain_name. This is useful for API Gateway stage name.
In this example, the stage name is api which is the same as the path_pattern.
Cache behaviors
There are two types of cache behaviors: default and ordered. When a request arrives CloudFront tries to match the path to the ordered cache behaviors one by
one until a match is found. If none matches, it will use the default. The ordering is important in cases where a given path matches multiple behaviors, like
images/* and *.jpg. In this case, it matters which one is the first.
The default behavior catches everything, so you don't need to specify a path_pattern. You can think that it's a hardcoded *.
3) S3 cache behavior
Let's set up first the static assets, which will be served as the default behavior.
default_cache_behavior {
allowed_methods = ["DELETE", "GET", "HEAD", "OPTIONS", "PATCH", "POST", "PUT"]
cached_methods = ["GET", "HEAD"]
target_origin_id = "s3"
forwarded_values {
query_string = false
cookies {
forward = "none"
}
}
viewer_protocol_policy = "redirect-to-https"
}The target_origin_id specifies which Origin to use for this path.
Since S3 does not care about cookies or query parameters (except for signed URLs), it is safe to not forward them. This helps with caching.
4) API GW cache behavior
To match paths under /api/, we need an ordered_cache_behavior:
ordered_cache_behavior {
path_pattern = "/api/*"
allowed_methods = ["DELETE", "GET", "HEAD", "OPTIONS", "PATCH", "POST", "PUT"]
cached_methods = ["GET", "HEAD"]
target_origin_id = "apigw"
default_ttl = 0
min_ttl = 0
max_ttl = 0
forwarded_values {
query_string = true
cookies {
forward = "all"
}
}
viewer_protocol_policy = "redirect-to-https"
}This disables all caching and forwards all cookies and query parameters, just how you'd expect for an API endpoint. The target origin is specified as apigw.
Note that the path pattern is /api/*, which does not match /api but matches /api/.
Another important thing is that CloudFront won't remove the path pattern when forwarding to the origin. For example, if your origin domain is example.com,
then with the above path pattern you can only send requests to example.com/api/... but not outside /api/. You can use Lambda@Edge to modify the URL before
sending it to the origin or handle this case on your backend.

Conclusion
CloudFront routing allows bringing all the pieces of architecture under one entry point. This simplifies client-side and brings benefits in terms of speed, caching, and price. And after you get familiar with the terminology, it's a relatively straightforward process.

