
How to hash passwords and when not to
What is entropy and how it changes how to store and transmit passwords


Hashing passwords
Hashing is an algorithm that gets a text (or other data) and returns a different, often long and random-looking, text. It's usually a one-way function, meaning it is easy to calculate but hard to reverse. Sounds easy, but when it's used with passwords, things get complicated.
Security 101 says don't store passwords plain-text becuse you don't need to know the password, you only need to know that the user knows it. So instead of storing the password and comparing the user-supplied one, you can hash both of them and compare the hashes. And since hashes are hard to reverse, if a hacker steals the database they don't get the passwords just the hashes.
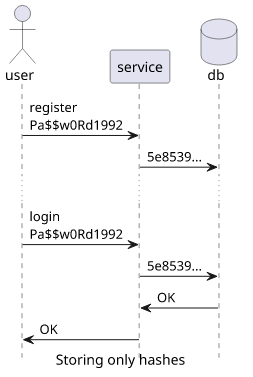
All secure? Nope, this is where password cracking comes into play. But for that, we need to talk about entropy.

Entropy
Entropy is the measurement of randomness. Imagine two people are playing a game. Player A uses a dice to generate a 5-digits number and player B tries to guess it. It sounds like a hard game for B, as a 5-digits number can be anything from 0 to 99999.
After playing a while, the first number turned out to be 44444, the second one 22222, then the third 11111. See the pattern? Now the game seems a lot easier: player A throws the dice once and repeats the result 5 times. Knowing this, B can forget most of the 5-digit numbers as A can't produce 12354, for example. In fact, the original search field had 100000 numbers, but knowing how A chooses it is now down to 6.
We say that if a number can be many different values then it's high entropy. If it only can be one of few choices, it's low-entropy. More specifically, a
5-digits number is log2(100000) ≈ 16.6 bits (2^16.6 ≈ 100000), while a single roll of a dice produces 2.6 bits of randomness (2^2.6 ≈ 6).
Knowing that player A didn't use all the available numbers makes player B's life a lot (a lot) easier. And the same thing happens with passwords.
Password entropy
Passwords can be easy (password1), hard (l2fyX2r40YBXc5cGntYBqy2S8b), and everything in between. Short and not varied passwords are low-entropy, as
they are easier to guess. For example, a password with a length of 8 without digits can only be 26^8 different values (in entropy, that's 37.6 bits). In
contrast, with digits, that goes up to 36^8 (41.36 bits).
More specifically, a password is "high-entropy" if it has at least 112 bits of randomness (lowercase, uppercase, and numbers with a length of at least 19). Anything below that is "low-entropy".

Hashing does not change the entropy of the input. While e38ad214943daad1d64c102faec29de4afe9da3d looks complicated and random, it is only a
combination of 8 lowercase letters and a number (password1). The same happens here as in the dice-throwing game: the hash can have a lot of different
values, but an attacker can discard most of them.
Because of this, a low-entropy password produces a low-entropy hash.
Hashing low-entropy passwords
After a bit of background information, let's go back to the original question: when and how to hash passwords?
Let's consider the most common case: visitors can log in to a website. In this case, you don't know the entropy, so you need to assume that passwords are low-entropy. And as we've seen before, hashing these passwords will result in low-entropy (easy to crack) hashes.
This is where slow hash functions come into play. SHA1, MD5, and similar functions are designed to be fast: get some data and calculate the hash as fast as possible. But here, that's a disadvantage. An attacker can quickly try out a lot of different passwords. Worse still, the playing field is not level: while the website is usually constrained to the CPU to calculate hashes, an attacker can utilize GPUs or special-built hardware (ASIC) that are orders of magnitude faster.
This is why you need to use special hash functions with low-entropy passwords. The more modern of these functions are designed not just to be slow (PBKDF2 uses an iteration count to run a fast function many times) but to be slow in a particular way: use a lot of memory. This makes the specialized hardware attackers might have less efficient.
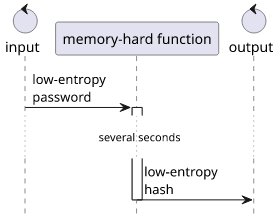
Examples for modern memory-hard hash functions are scrypt and argon2. I prefer the latter, as it's easy to reason about its parameters:
- it uses
mKiB amount of RAM - writes it
ttimes - with at most
pthreads
In encoded form: $argon2id$v=19$m=4096,t=3,p=1$dGhuYWlodGxuaDRuZWlrc3Rucmh0c3JuaWF0aA$SJgSDQMwnjKDFs6gVAvio8zIe09J7wK59v/5kZMAYEM (the v is the
version, the first part between $...$ is the salt, and the rest is the encoded hash).
Notice the salt: this is generated for each password. Adding this forces an attacker to crack each password individually.
Bottom line: use a memory-hard hashing algorithm for low-entropy passwords.
Hashing high-entropy passwords
Much rarer, but still happens is when you know the password is high-entropy. This is the case for generated tokens, or for passwords that are generated and stored in a vault (such as a password manager).
Since the password is high-entropy, the hash is also high-entropy. An attacker needs to enumerate all the possible values (statistically, half) to find the password.
In this case, it does not matter what algorithm you use or even if you add salt or not. Even unsalted MD5 is good in this case.
When not to hash passwords
Finally, there is a case where hashing passwords is not the good choice. I mention this as I saw it several times and even developed one such system myself before I realized I made a mistake.
When users log in, they send their passwords to the service that check them against a database. By default, the password is sent plain-text, then the service hashes it, then compares with the stored value. The problem is that the password is visible in the browser devtools.
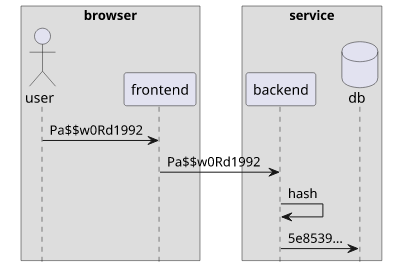
This prompts this thought: why not hash the password on the client-side so that it's not visible on the wire?
So an implementation would work like this:
- The user enters the password
- The frontend hashes it, then sends to the backend
- The backend rehashes and compares the hash with the stored value
The problem is that if an attacker can get the hash of the password they can log in. This is because they can send the hash directly and the backend will be happy to let them in. In effect, the password is now not the text the user enters but the hash of it. And it means that anyone who has the hash will be able to log in.
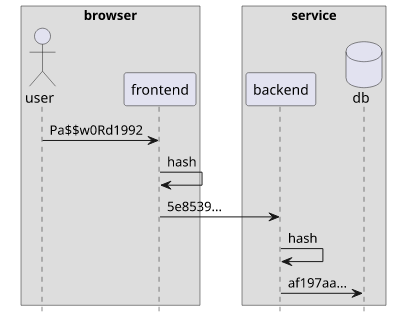
This is called security theater: You don't see the value on the devtools but it doesn't provide any security benefits. Worse still, if the backend does not rehash the incoming value, you are effectively store passwords in plain-text.
If it bothers you that the password goes on the wire in plain-text (which is not a problem when you use TLS), you can implement a protocol that is specifically designed to solve this, such as SRP.

