
How serverless cold starts change best practices
Before serverless, doing everything during initialization sped up requests. Now it's slowing them down


I worked on a backend project that was based on an OpenAPI document. There is a framework called openapi-backend that provides bindings for Node.Js code that handle endpoints defined in the document. It's great as there is no need to duplicate code. Everything is in the API document.
The openapi-backend runs a lot of initialization code, which is a best practice when deployed to a server as it leads to fast response times after. But this leads to terrible performance deployed as a Lambda function.
This got me thinking about how serverless changes what is the best way to write backend functions and especially how to schedule initialization code. Subsequently, the openapi-backend got an option to better support serverless environments.
In this article, I compare serverless and traditional environments and how moving from EC2 to Lambda changes best practices.


The problem: cold starts
The root of the problem is cold starts. When a backend instance is initialized, the execution environment deploys the code to a new machine and starts routing requests to it. In the case of AWS Lambda, it happens when all the current instances are busy.
This is the basis of Lambda scalability: start an instance when needed, then stop it when it's idle for too long.
As a result, the first request needs to wait until the startup process is finished. Worse still, the code is "cold", which means that the execution environment hasn't done loading and optimizing the function's code and all the variables are uninitialized. The former is especially pronounced in Java as the JVM needs to do quite a bit of work to load the classes. It does not help that it has to be done only once.
The result is that there will be occasional slow responses when you deploy your code as Lambda functions. While most requests will be fast as they go to warm instances, some will trigger cold starts.
Slow requests cause several problems. First, they might be just too long and that leads to bad UX. They can be made faster by allocating more memory that (due to the Lambda resource model) increases the CPU power available to the function. But that also increases costs for fast requests.

Second, there is a single timeout setting for a Lambda function. To accommodate slow cold starts you need to increase it way above what all the other requests would need.

Performance best practices
The openapi-backend uses an OpenAPI document as the basis of the backend code. It makes heavy use of JSON schemas to define what type of data API endpoints can receive and send. This provides validation effectively for free.
During initialization, the framework compiles the schemas in the document. It does this as compiled validators are lightning-fast.
But the compilation itself is rather slow. Even for a small number of schemas, it took >2 seconds which is added to the cold start time. Worse still, this delay is linear to the number of schemas, so a larger API has a longer cold start time.
If you use load-balanced EC2 instances that start and stop rarely, you want to do everything as soon as possible. The best practice is to do as much initialization as possible, such as populate the caches and even sending a dummy request (called a warmup request) to execute some code paths. When the instance is started, it is ready to serve requests at full throttle. By compiling all schemas during initialization the openapi-backend project followed this best practice.
Serverless, a.k.a hyper-ephemeral computing, is built on short-lived instances and that means initialization happens fairly often as the execution units are small and the need for new capacity is instantaneous. Also, cold starts are visible to users, as it happens as part of a request and not in a separate process. The best practice here is to do as little as possible and distribute the work to subsequent requests, also called lazy loading or deferred execution. This brings down the cold start times to an acceptable level.
Results
I ran some tests on the openapi-backend project and the results clearly show the contrast in behaviors. The red line is the original configuration, compiling everything as soon as possible. The green line is with deferred initialization.
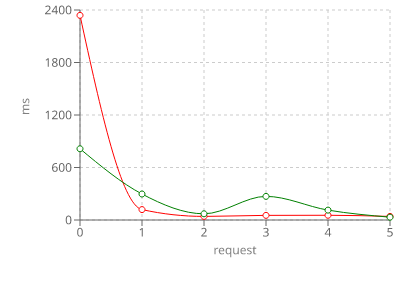
The green line shows a lot less variability in response times. The first request is still significantly longer than the rest, but this is less pronounced. With this setup, there is no need to increase the memory and the timeout settings too much.

