
The consequences of memory allocation size for a Lambda function
What is behind a single number


The memory allocation for a Lambda function can go from 128 MB to over 3 GB. This directly affects the memory available to the function and also increases the price so you are encouraged to set it as low as possible. But this setting is not just about memory, as it affects CPU allocation, running time, CPU variability, and function scalability.

Measuring memory usage
The available memory directly affects the function. Giving it too much is wasteful, while too little can lead to memory-related errors.
Fortunately, when Lambda logs the function execution to CloudWatch Logs, it also reports the maximum memory used:
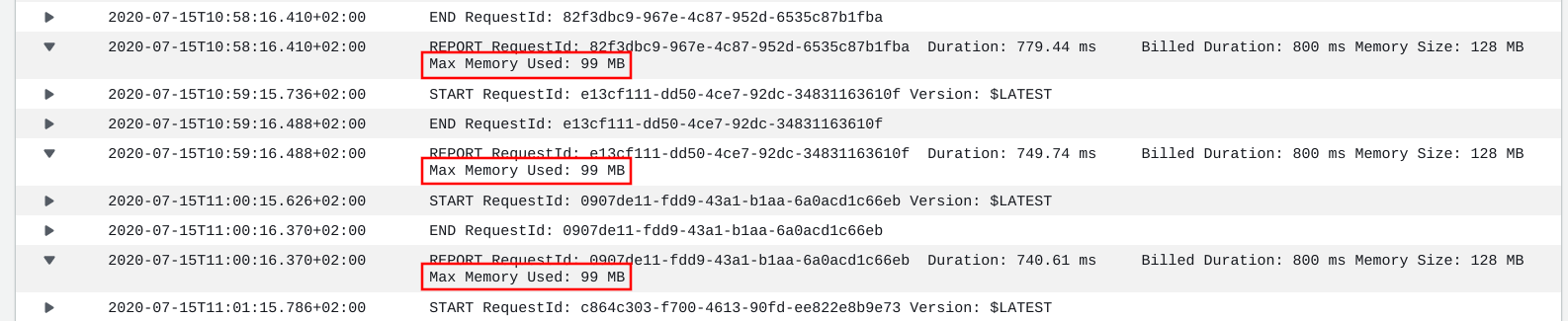
This gives a good estimate on how much of the allocated memory is used. Furthermore, CloudWatch Logs Insights can graph these values so that it's easy to see the outliers over a longer period of time.
This filter expression reports the mimimum and maximum of the memory usage, aggregated in 10 minutes:
filter @type = "REPORT"
| stats max(@maxMemoryUsed / 1024 / 1024), min(@maxMemoryUsed / 1024 / 1024) by bin(10m)This gives a graph similar to this one:
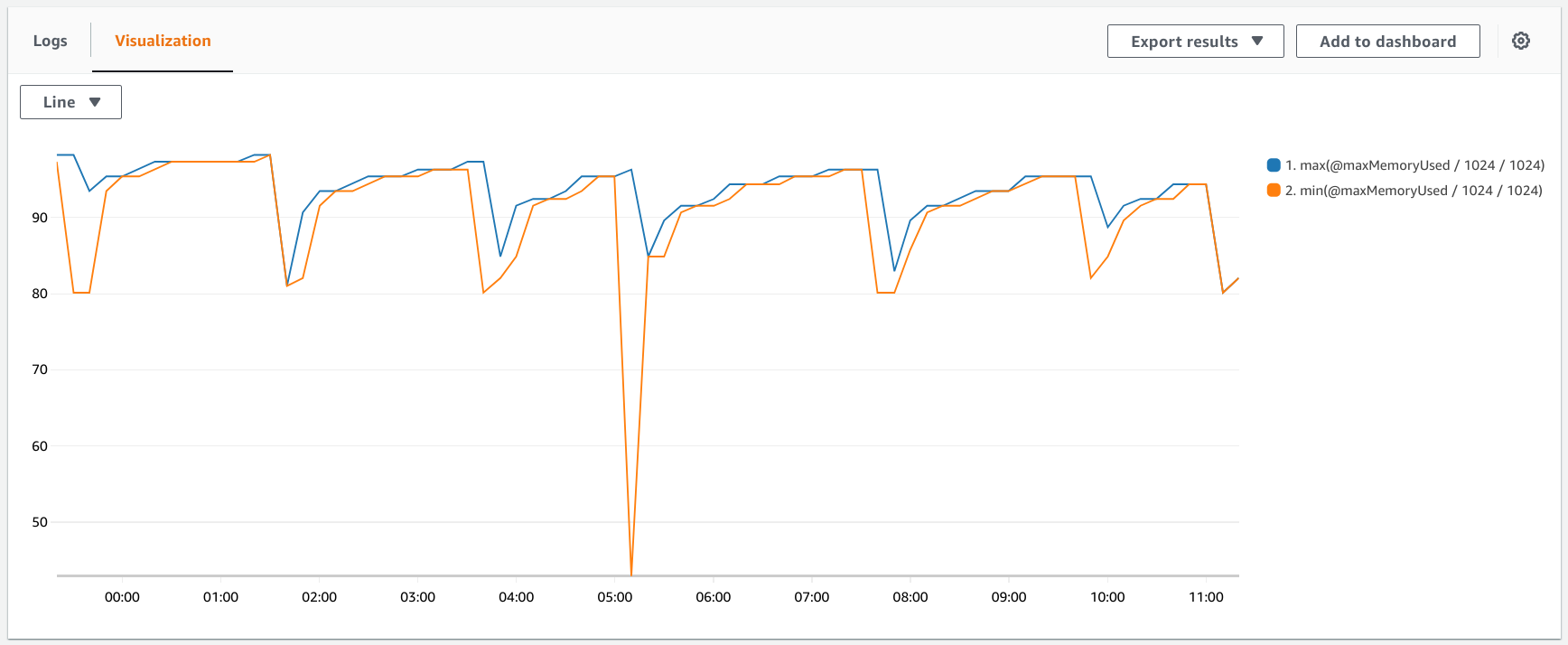
Knowing the actual memory usage is a good starting point for optimizing the allocation. When the available memory is more than the used then you can safely lower the setting without worrying about errors.
On the other hand, the used memory usually does not indicate a hard requirement. Most runtimes are using garbage-collected languages, which means they use more memory than what is strictly necessary and run the GC when needed. A lower memory allocation means more frequent GC runs which might slow down the function, but won't result in memory-related errors. Knowing the true minimum requires experimentations with different settings.
CPU allocation
A side effect of allocating memory is that it also allocates the CPU power available to the function. According to AWS, a full vCPU core is allocated for 1.792 MB of allocated RAM, and it scales linearly with memory. This yields ~7% vCPU for 128 MB of RAM.
I believe AWS uses standardized machines for Lambda and the function gets some percentage of its resources, so by allocating memory you are in fact allocating the other resources with it too. And they just decided that memory is easier to grasp than some sort of vMachine metric that translates to memory and vCPU.
As more RAM means more CPU power it also translates to shorter running times.
Total cost
Cost of a function invocation is <duration> * <allocated memory>. But the duration is rounded up to the next 100ms mark and that makes a curious economic
situation.
Since the allocated memory linearly affects the allocated CPU which in turn at most inversely change the duration (doubling the memory doubles CPU, which in turn at most halves the duration), increasing memory wouldn't mean cheaper execution. But with the discretized duration, it can.
If you can decrease the duration to fall into a lower bracket, that can have a significant effect on the overall cost. The difference between a runtime of 105 ms vs 95 ms might be small in terms of additional CPU power, but the billed duration is halved.
There are even tools that measure the runtime for different configurations and help with coming up with a sweet spot.
Running time
More CPU means shorter running time. After all, serverless still runs on a computer and we're used to the thought that a computer finishes sooner if it's faster.
But this does not translate directly to all kinds of functions. Increased CPU means shorter running times only if the CPU is the limiting factor. There are workloads where this is true, but most functions are not like that.
A typical function validates and transforms requests and responses and communicate with other services. This means most of the time is spent waiting which won't benefit from a faster CPU.
Let's look at this function execution:
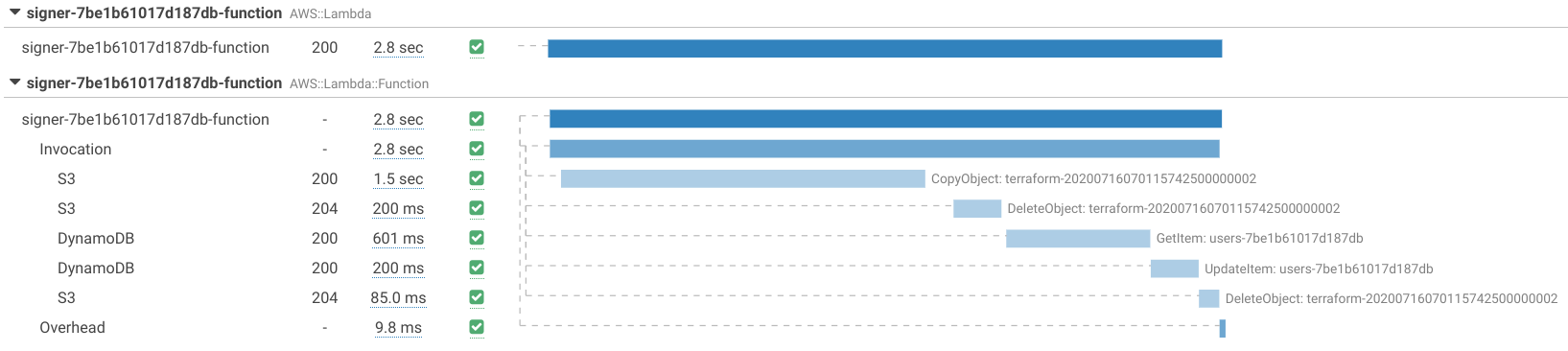
The total running time was 2.8 seconds, but 2.6 out of that was calling S3 and DynamoDB. Adding more processing power speeds up some part of those calls, but the effect would be a lot less than anticipated.
That's why most benchmarks profiling the effect of memory to running time do things like prime number testing or Fibonacci sequence generation. Keep in mind that those findings might not directly translate to your workload.
Second CPU core
A common misconception is that above 1.8 GB the function gets access to a second CPU core. This is based on the AWS documentation stating that 1.792 MB translates to 1 vCPU core:
Lambda allocates CPU power linearly in proportion to the amount of memory configured. At 1,792 MB, a function has the equivalent of one full vCPU (one vCPU-second of credits per second).
But notice that it does not mention the number of available CPU cores or the capacity of the physical core. In reality, all functions have access to 2 cores no matter how much memory is allocated:
[
{
"model": "Intel(R) Xeon(R) Processor @ 2.50GHz",
"speed": 2500,
"times": {
}
},
{
"model": "Intel(R) Xeon(R) Processor @ 2.50GHz",
"speed": 2500,
"times": {
}
}
]What happens is that the function gets more CPU credits than it can spend using only one core. When that happens, having more credits won't translate to faster runtimes unless the second core is also used.
According to benchmarks this happens above 2.048 MBs. If your function can not utilize the second core then it won't get CPU benefits above that setting.
NodeJS, for example, uses only one core for the event loop. While certain operations, like reading from the filesystem, are multithreaded, the function code won't expand to the second core. Unless you use web workers or webassembly, your code is unlikely to benefit from increasing the allocated CPU beyond saturating one core.
CPU variability
An interesting find is that the CPU credits seems to affect only the minimum amount of CPU the function can use, but when there is spare capacity it can run faster. A particularly well-made benchmark found that the function with 128 MB RAM allocated occassionally runs as fast as another with 12 times the processing power.
While this test was done in 2017 and there is no official documentation about this behavior, it might work differently at this moment or can change in the future.
If this behavior is still true, that leads to functions that are sometimes fast but usually slow. While using spare capacity seems like a good idea, excess variability in the running time can lead to unwanted side effects. If you happen to profile the function during a fast period you'll see incorrect results. Also, it might trigger a warning in a monitoring system that suddenly sees increased response times.
Allocating more RAM increases the processing power and that decreases the wriggle room which leads to smaller variations.
Concurrency
Choosing between fewer and faster functions and more but slower ones has an impact on the scalability. AWS's promo line for Lambda on the console is "Run Code without Thinking about Servers", but that is misleading. In a hypothetical perfect serverless architecture, choosing between faster and slower functions has no consequences besides the response time. But in reality using fewer instances has a few additional benefits.
First, Lambda can not scale from zero to infinity in an instant. There is a burst concurrency limit that is between 500 and 3000, and after that there is a scalability limit of 500 / minute. With fewer function instances, these limits translate to more processing power.
Another benefit of fewer instances is that functions can share data between invocations but not between instances. This comes handy in cases where the function needs an in-memory cache, for example to keep under the Parameter Store limits. Fewer instances make fewer calls to the service.
And of course, cold starts happen rarer when there are fewer instances.
Conclusion
The memory setting for a Lambda function is not just about memory but instead a proportion of all the resources that virtual executions share. Most notably, it affects the allocated CPU. Bring in the cost model of Lambda and you end up with a lot of small changes behind a single number.

