
Hardcoded assumptions
What makes software break without breaking changes


Hardcoded assumptions
What I found is when a piece of software is "brittle" that is the result of hardcoded assumptions that are not guaranteed by the other parts of the system. In a sense, a part becomes "overfitted" to the environment so that when the environment changes even in ways that are considered safe, it still breaks.
On the other hand, if the software hardcodes fewer assumptions, as a former coworker said, it "lands on its feet".
This is captured in Hyrum's Law:
With a sufficient number of users of an API, it does not matter what you promise in the contract: all observable behaviors of your system will be depended on by somebody.
The clients hardcode assumptions that are not held by the system, making them break for slight changes.
Let's see an example: showing the last login of the users.
type User {
name: String!
# Returns logins ordered by time decreasing
logins(limit: Int): [Login!]!
}The above code uses GraphQL, but the ideas presented work the same with other APIs as well.
Then fetch the last login:
query {
user(id: "user1") {
name
logins(limit: 1) {
date
}
}
}This returns an Array with one item, the last login:
{
"data": {
"user": {
"name": "User 1",
"logins": [
{"date": "2024-05-02T08:08:36.641Z"}
]
}
}
}Finally, show this information on the frontend:
${user.name} (${user.logins[0].date})Notice that the frontend hardcodes the assumption that the result will always have at least one item. Maybe the system works in a way that it stores the user in the database when it first logs in and as a result there can't be a user with at least one login event.
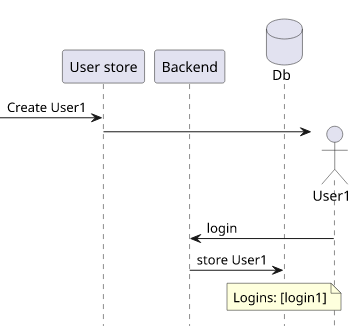
If that is the case, then there is no bug here: under no circumstances can the logins(limit: 1) return zero items.
But maybe that assumption is not a guarantee: while it works 100% of the time, it's not something documented and understood by everybody. What happens if there is a completely unrelated change in the registration flow and now a user is created before logging in first?
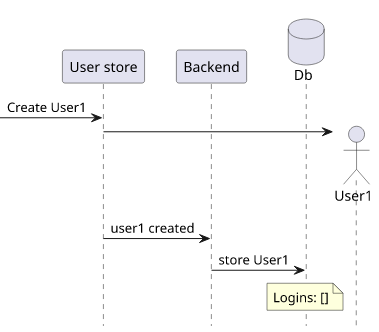
If that happens, the frontend breaks even though there was no breaking change. After all, nothing guaranteed that every user has at least one login, it was just a coincidence.
Worse still, what if the system changes so that the assumption is broken but it's not that easy to see? Maybe originally the user login was registered in the same transaction as the user creation, but that later moved to a separate write operation? In that case, there is a race condition: when the frontend gets the new user the login may or may not be persisted, leading to a race condition. When the feature was originally implemented it was free of bugs, but now it is broken in a subtle way.
Hardcoded assumptions are related to breaking changes. If only the contracts are hardcoded in a client (an ideal but hardly achievable situation) then all breaking changes are explicit: removing a field, for example, would break the client. But with hardcoded assumptions a breaking change can be implicit: all contracts are held and the client can still be broken.

Examples
I see hardcoded assumptions pretty much everywhere I look at code.
Here's a couple of examples.
Pagination with limits
This is a typical example I've seen over and over again.
To see how it works, let's extend the first example with pagination:
type PaginatedLogins {
logins: [LastLogin!]!
nextToken: String
}
type User {
# Returns logins ordered by time decreasing
logins(nextToken: String, limit: Int): PaginatedLogins
}What limit guarantees in the logins(nextToken: String, limit: Int) field?
It guarantees that the number of returned items will be less than or equals to the limit argument. What that means is that a limit: 1 is not
guaranteed to return any items in the first page even if there are items to return.
So a result like this is entirely within the guarantees of the API:
{
"data": {
"user": {
"logins": {
"logins": [],
"nextToken": "page2"
}
}
}
}And then the next page returns the login:
{
"data": {
"user": {
"logins": {
"logins": [{"date": "2024-05-02T08:08:36.641Z"}],
"nextToken": null
}
}
}
}Why is that surprising?
Mainly because SQL works differently. When you have a SELECT with a LIMIT then it returns all result items up to LIMIT. For example, the
Postgres documentation says:
If a limit count is given, no more than that many rows will be returned (but possibly fewer, if the query itself yields fewer rows).
This will return 1 result if there is at least one login and zero otherwise:
SELECT * FROM logins LIMIT 1;But that's an exception and not the rule. A good API is predictable: no matter the arguments and its internal state it will return a response in roughly the same time. If it needs to filter the results it gets from the database then providing the lower guarantee on the number of items returned (return an item if there is one) would result in variable performance: if there are many items it needs to filter out then it potentially need to fetch many pages from the database.

What would it look like if the lower limit assumption is not hardcoded in the client? It would fetch pages until:
- an item is returned => that's the last login
- no pages left => no last login
ID length
UUIDs are commonly used for identifiers as they are collision-resistant enough and still user-friendly that it's easy to tell 2 different IDs apart.
When all identifiers are like this, it's tempting for clients to build an assumption and use something like this to detect IDs:
[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}But the guarantees of an ID are just:
- they are a non-empty string
- and they identify and object
Hardcoding the structure of the ID makes the client brittle: if the backend decides to change the ID format for new items, let's say to add a type prefix, then it's not a breaking change: the contract of the ID still holds. But it will break the client nevertheless.
There are valid reasons why having a more restricted definition of an identifier might be needed. For example, a memory-constrained IoT device might need to allocate a fixed amount of bytes to store the ID. In that case, it makes sense to have a guarantee on the backend that no IDs will be longer than that agreed-upon length.
TOTP token length
Have you noticed that when logging into Atlassian there is no need to press enter when you input the 6-digits MFA code? After the 6th digits it auto-submits the form. While it's not a good UX (if I mistype the last digit I can't delete it back immediately but need to wait for the error), implementing something like this would hardcode an assumption that is usually not guaranteed.
Yes, the default for TOTP tokens it 6 digits and pretty much everybody goes with the defaults. But there are no guarantees, the specs allow for other lengths as well:
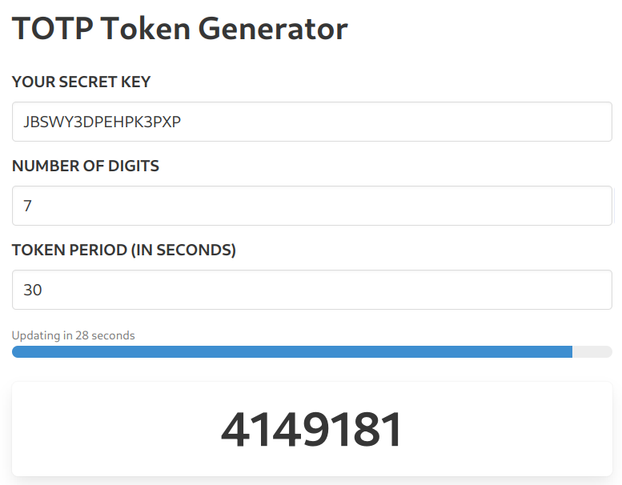
If the user store decides that from one point it generates 8-digit codes then it is free to do so without breaking any contracts. Since it is encoded in the QR
code (the digits in otpauth://totp/label?secret=secret&algorithm=SHA1&digits=8&period=30), it is transparent to the user. But if the frontend
auto-submits after 6 digits then it will be impossible for the user to log in.
Hardcoded URLs
When I first started working with AppSync there was no support for custom domains. When an API was created it got a generated endpoint at
<id>.appsync-api.<region>.amazonaws.com.
Since that is not a stable URL, I needed an indirection, something like a <domain>/config.json that points to the current API URL:
{
"APIURL": "<id>.appsync-api.<region>.amazonaws.com"
}This way the clients could first fetch the /config.json, read the APIURL then send queries to the API.
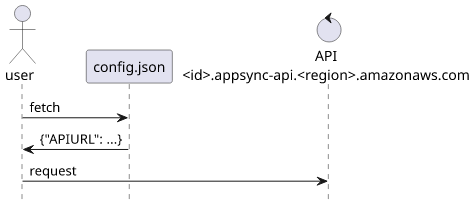
All is good, but then there were clients that did not make this indirection and instead hardcoded the <id>.appsync-api.<region>.amazonaws.com URL.
What does it mean?
If the API is recreated (something that was needed in the past), those clients will break. The assumption that was hardcoded was that the API's URL is static, which is not guaranteed, hence the indirection.
Recommendations
The problem with hardcoded assumptions is that they usually not possible to spot when using the app. With black-box testing, everything working perfectly as in a static environment all the assumptions hold.
Some assumptions are more damaging than others. Hardcoding that a TOTP token is always 6-digits long is quite safe: while theoretically it can change in practice that's hardly the case. But hardcoding the API URL is more sinister: there are circumstances when it's inevitable to recreate the API and it can not be rolled back.
To detect hardcoded assumptions it's necessary to look into the code, so it's the responsibility of engineering. Peer review can help to spot them, and also prior experience with breaking changes.

