
Comparing async Javascript functions and callbacks on AWS Lambda
Callbacks are the past, use async functions for new Lambda handlers


Initially, Lambda only supported callbacks with Javascript handlers. Back then in 2014 it was the common way to handle asynchronicity as async/await was nowhere near as mainstream as it is today. Moreover, the SDK functions also used callbacks so it fits into the trend.
But we've come a long way since then and now callbacks are becoming an anti-pattern with async functions taking their place. Fortunately, Lambda supports them just fine now.
Let's see what are the problems with callbacks when running in Lambda and how async functions can replace them!

How callbacks work with Lambda
When callbacks are used, the last argument of the handler is a function which you need to call. It uses the Node-style callback pattern, so it expects
two arguments: (error, result). To signal an error, use callback(error), and when everything is fine, return the result with callback(null, result).
module.exports.index = (event, context, callback) => {
// .. do your thing, Lambda!
callback(null, result);
}Problems with callbacks
Simple enough, but there are many problems with this approach. While it works fine for a "Hello world", it is just not the best choice for anything serious.
Waiting for async
Two distinctly Lambda-related things pop up when it comes to callbacks and Lambda. The first is context.done() which is still part of many copy-pastable
code samples but it's deprecated. The second one is the context.callbackWaitsForEmptyEventLoop.
Both are related to tasks still running when the callback function is called.
In a normal Node environment, things started when a request comes in will be executed even if the response is sent. A normal HTTP server would work like this:
const app = http.createServer(async (req, res) => {
// Do your thing, http server!
// Hold this for me, will you
s3.putObject(...);
res.end(result);
});In this case, the response does not wait for the putObject to finish. But it does not change much, the result is sent to the user as soon as possible,
and the object will be in the bucket eventually.
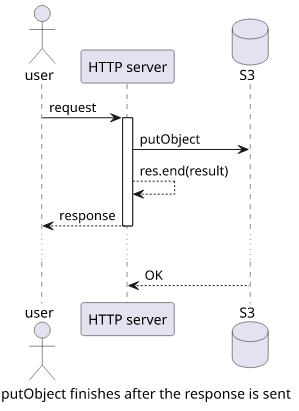
But Lambda is a different environment and there is no "do something after the response" thing. Which leaves it two options:
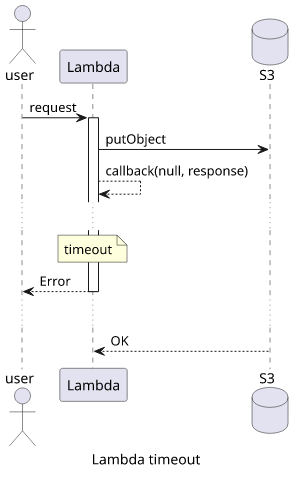
The first one is to wait for the background task to finish. Since it's so easy to forget something important still running when using callbacks, this is the default.
The second option is to stop the tasks which is exactly what context.callbackWaitsForEmptyEventLoop = false does. And historically, context.done()
and context.succeed().
Because of the default behavior, you can see timeout errors even if the callback is run in a timely fashion. Something is still going on, and Lambda will wait for it. Such as calling a different function that has a longer timeout and running time will timeout this one even though the callback is run.
module.exports.index = (event, context, callback) => {
// .. do your thing, Lambda!
// let me just call this buddy of mine real quick
lambda.invoke(...)
callback(null, result);
}A bad fix is to set the context.callbackWaitsForEmptyEventLoop = false and instruct the runtime to stop execution when the callback is run.
module.exports.index = (event, context, callback) => {
// .. do your thing, Lambda!
context.callbackWaitsForEmptyEventLoop = false;
lambda.invoke(...)
callback(null, result);
}What happens here?
No one knows.
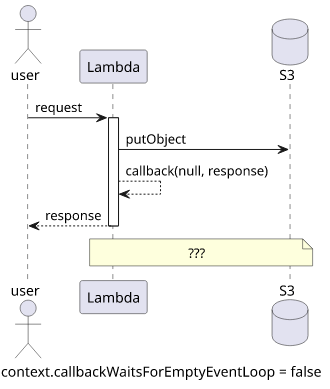
The thing is, Lambda freezes the execution and might reuse it later. So the call may go through immediately, it may be finished later when a separate request triggers the same function, or might never resume as the execution environment kills the process altogether. There are no guarantees.
Problems with callbacks
Also, excessively relying on callbacks is bad in general not just in the context of a Lambda function.
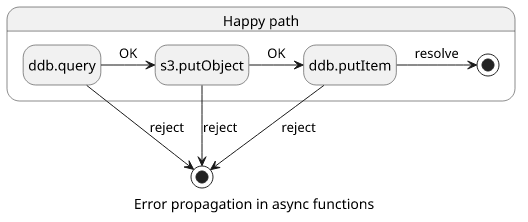
Have you heard about callback hell? As you could tell, it's not a nice place. Here's how it looks like:
module.exports.index = (event, context, callback) => {
ddb.query(..., (queryErr, queryRes) => {
if (queryErr) {
callback(queryErr);
} else {
s3.putObject(..., (putErr, putRes) => {
if (putErr) {
callback(putErr);
} else {
ddb.putItem(..., (ddbPutErr, ddbPutRes) => {
if (ddbPutErr) {
callback(ddbPutErr);
} else {
callback(null, ...);
}
})
}
})
}
})
}Every async operation adds more depth and it quickly becomes really, really hard to understand what's going on. For some time you think you can grasp it, but forget it.
Also, look at the error handling! Even one forgotten check is enough to wreak havoc to the whole operation and instead of the failure reason you'll see timeout errors.
How to use async functions with Lambda
The solution, of course, is to use Promises and async/await. That solves all problems with the callback pattern.
To use an async function, just skip the last parameter and convert it to async/await:
module.exports.index = async (event, context) => {
const queryRes = await ddb.query(...).promise();
const putRes = await s3.putObject(...).promise();
return ddb.putItem(...).promise();
}No more extra indentation for each async call, and errors are propagated just fine without any extra work.
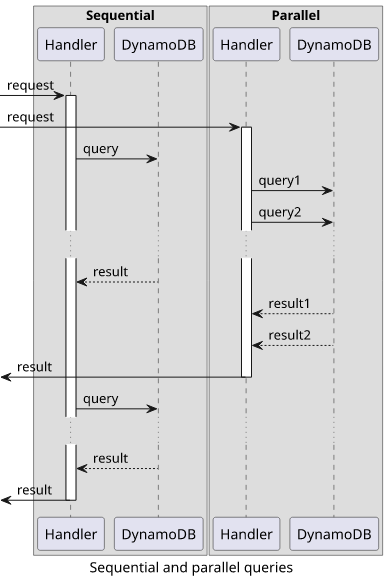
Parallelization with the above benefits is also easy with Promise.all:
module.exports.index = async (event, context) => {
// The two *independent* queries run concurrently
const [query1Res, query2Res] = await Promise.all([
ddb.query(...).promise(),
ddb.query(...).promise()
]);
}Parallelization is important not just to provide a speedy response to the user hence improving the UX but also because you are billed for the total time the function executes. Waiting for a network request to come from an external service just so that the function can start waiting for a totally unrelated other one is a waste of money.
Also, the AWS SDK provides functions that return Promises, which can be inserted into an async/await flow naturally. While the default is still
the callbacks, most function either support the .promise() to convert it to one:
// promise me an object
s3.getObject(...).promise();or provides a different function for that:
// promise me a signed URL
s3.getSignedUrlPromise();Async executions
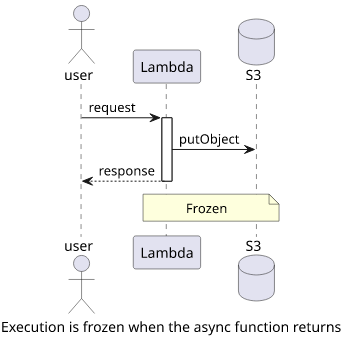
But async/await only solves problems with callbacks and the original problem was what to do with tasks still running when the function returns? After all, async functions can still linger around unawaited for.
module.exports.index = async (event, context) => {
// better hurry up, not gonna wait for you!
s3.putObject(...).promise();
return result;
}What to do with the putObject call that is still running when the result is ready? In this case, we are back to square one.
But there is an important distinction. The default behavior for callbacks is to wait for everything, but for async functions it is to return immediately.
I believe this is because it's so much easier to make an error of not waiting for something when callbacks are used than with async functions. But keep in mind that
this behavior is not configurable, there is no property in context to change it.
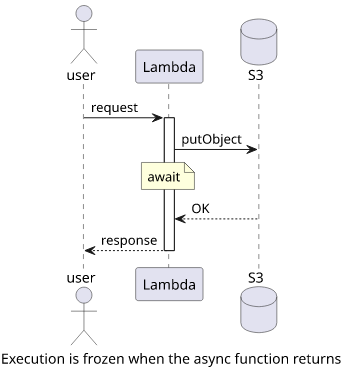
So, how to wait for background tasks to finish with async functions? With await, of course:
module.exports.index = async (event, context) => {
// don't worry, we'll wait
await s3.putObject(...).promise();
return result;
}
If you have callbacks, you can convert them to Promises with the Promise constructor and wait for the result:
await new Promise((res) => {
// do what has to be done
res();
});This gives an easy way to wait for pretty much anything, be it non-standard callbacks or streams to finish.
Conclusion
Callbacks are the past, don't use them. They have problems on their own, such as callback hell and poor error propagation and that can easily lead to problems in Lambda functions.
Use async functions instead as they are supported by both the Lambda environment and most of the AWS SDK, making asynchronous code shorter and safer.
But keep in mind that the Lambda environment is still not exactly like a Node server as there are no guarantees what happens to background tasks not finished by the
time the response is sent. This requires some planning, but properly await-ing for everything is the key here.

