
Revisiting webapp performance on HTTP/2
This report analyzes the common techniques on webapp performance on the current and the next HTTP protocols

Motivation
It's well known and documented that webapp speed is an important aspect when designing a build system. Slow loading can cost visitors and in turn money; many people investigated the issues which resulted in a number of techniques to maximize performance. Now that HTTP/2 is just around the corner and browsers are already supporting it, we should revisit former best practices and assess whether to incorporate them in the build or measure the diminished results in the new transport.
In this post, I will cover the common techniques, introduce the testing system, make some measurements and finally draw some results. I am focusing only on the loading times.

Performance techniques
First, let's iterate over the most commonly used techniques that are aimed to speed up client-side loading times!
GZIP
This is pretty basic and universally supported. It just means that the content is compressed, effectively making it fewer bytes, hence more speed.
There are virtually no use cases when gzipping should be disabled, so it should be used in each and every setup.
Concatenation
Traditionally the number of round trips is the most important bottleneck on loading times; unlike bandwidth, it won't become better with newer technologies. Concatenating the sources is copying them in a single (or at least, fewer) file so that the browser can download it in a single round. As current browsers have a connection limit, this compaction has a huge effect on loading times.
However, there are a few drawbacks. The most important is that it requires HTML rewriting too, making the build more complex and is somewhat error-prone. The other scenario being to keep an eye on is when multiple output files are produced and contain an overlapping set of input files. This setup can render them bulky.
Minification
As client side code is written for reading, it contains much unneeded parts, such as indentation. Minification should keep the functionality intact while reducing the footprint. As an added benefit, it makes copying the code without possessing the source harder.
A drawback is that it makes debugging harder, but using Source Maps should mitigate this.
Mangling
Mangling is part of the minification, it is the renaming of the variables and functions. It should save quite a few bytes, and if done properly, it should not affect the functionality.
The drawback is that it can easily break the app. When building a library, renaming the public API makes consuming it impossible. Exports and externs should solve this, but it's cumbersome to write them. Libraries like AngularJs depend on argument naming, and mangling possibly breaks them.
Revving
Revving is the renaming of referenced files to contain the hash of their content. This makes perfect caching possible.
The drawback is that as the concatenation it also requires rewriting the HTML which might be error-prone.
Testbed setup
The complete source and information can be found in this Github repository. The following performance optimizations can be tested with it:
- asis: There is no concatenation and minification whatsoever, the files are served as is
- concat: The files are concatenated only
- concat_minify: The files are concatenated and minified, but not mangled (the variable names are not shortened)
- concat_minify_mangle: Full concatenation, minification and mangling are performed
- minify: The files are minified separately, without concatenation
- minify_mangle: The files are minified and mangled separately
The effect of gzipping can also be observed with the HTTP/2 and HTTP/1.x serving.
Results
Comparing sizes
The first test I carried out is inspecting the sizes of each case for both the gzipped and the raw contents.
The following table summarizes the results:

Comparing load times
Measuring times are trickier than measuring size, as there are more aspects that can affect the outcome. First, I am only considering the gzipped versions for both protocols. Second, I only take the js download times into consideration, as the HTML and the HTML processing is the same for both protocols. I prime the caches before every request, simulating a new visitor every time. The tests are performed on an AWS micro instance to have a realistic RTT and each measurement is performed multiple times to filter out some random noise.
The following table summarizes the results:

Comparing cache effects
This comparison is trickier than comparing speeds. The question that I was particularly interested in is whether revving is really worth it's price or not. The main benefit of perfect caching is that it cannot become stale, so there is no need to validate it. This means that if a visitor downloaded it once, there is no additional round trip. The effect is nicely presented in the network timeline:
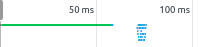
The green line represents the HTML that must be downloaded/validated, but after that there is absolutely no network usage. This greatly speeds up the website.
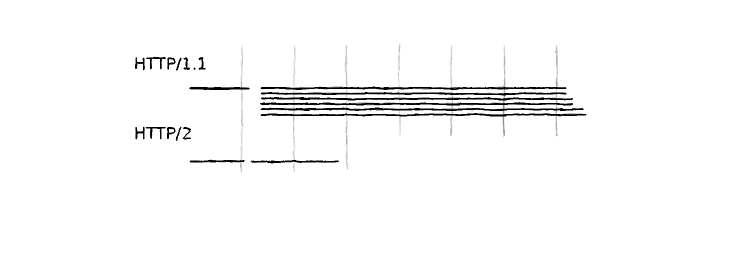
Let's compare how the two protocols differ when the assets must be validated, and they are not concatenated (because then there is only 1 round trip)!
For HTTP/1.1 I got the following timeline:

And the same setup for HTTP/2:

Conclusions
Now that we have the hard data, let's draw some conclusions. Regarding size, gzipping is a must and it has the greatest effect on minimizing bytes transmitted. Using minification we can reduce it even further, about half. Mangling has some effect too, but on a much smaller scale: it reduces the size by about 15%.
Interpreting the timings is a more interesting topic. HTTP/2 is considerably faster in all the cases than the old standard. The second noticeable thing is HTTP/2 load times are only correlated with the amount of data transferred, and does not depend on the number of files, thanks to the multiplexing feature. On the other hand, HTTP/1 depends on the quantity of the files, but on a much lower level than anticipated. Seems like the browser does a surprisingly good job of scheduling downloads. Although, when testing the cached case, the time needed to only validate all assets is almost the same as downloading them.
Best practices revisited
If you are writing a library that will be used by a massive amount of people, like an analytics snippet, then you should apply every possible optimizations and save every byte that you can. On the other hand, for most of the webapps out there, this zealous approach may results in a more complex build than it should be and the savings would be marginal.
My recommendation for HTTP/1.1 is concatenation + minification + revving, without mangling. This setup mitigates the lack of multiplexing and allows perfect caching, while sacrifices only about 15% of size optimizations. As mangling can easily break the functionality, it should be used sporadically and with extra care.
For HTTP/2, I recommend using only the minification, without mangling, concatenation or revving. This has the same ~15% penalty in size, without effect on timing. Without revving, the client must validate the assets, and it means 1 extra round trip, which in turn adds ~80 ms to the cached download time, a small footprint.
On the other hand, it basically eliminates the need for a build system for the frontend. As there is no need to rewrite the paths in the HTMLs, each file can be minified and then gzipped separately. It can be done even with a simple bash script that is run during the deployment. This means there is nothing that would break the functionality of the deployed app, and the whole script can be written in a generic and reusable way.

