
Keep costs under control when using t3 instances
How an enabled-by-default option can cost you more than you think. Way more


I'm sure you know the t3.nano instance type in EC2. It has access to 2 vCPUs, has moderate bandwidth, and is generally an all-purpose virtual machine
capable of handling light workloads. You need to pay separately for block storage and network usage, but considering only the CPU it will cost at most $72 a month.
Yes, you read that right. The t3.nano can cost you $72 a month. The product page shows $0.0052 an hour, but digging into the documentation shows that the
$72 is indeed possible.
Let's see how!

CPU credits
The burstable instances, which cover all with the t3. prefix, accumulate CPU credits over time. These represent the share of the physical CPU it can consume
and this process makes sure that no client on the multitenant machine starves the others, all while maintaining a predictable system.
Credits accumulate over time towards a maximum, which is the amount the instance earns in 24 hours. And since different instance types get different amounts,
this maximum also varies. A t3.nano gets 6 per hour with a maximum of 144, while a t3.2xlarge gets 192 with a cap at 4608.
One credit equals to 1 minute of a full vCPU core, so a t3.nano can use it 6 minutes every hour sustainably.
When the credits run out, the instance is throttled.
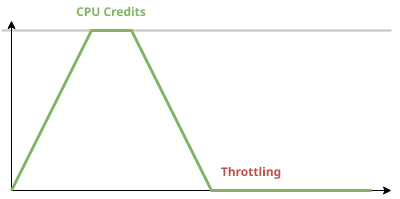
This is called standard mode.
Unlimited mode
When the T2/T3 Unlimited mode is turned on, instances can also get surplus credits. After all normal credits are used, these surplus ones get accumulated. And when they reach the maximum, which is the same for both types, you get charged for the excess.
On a graph they look like this:
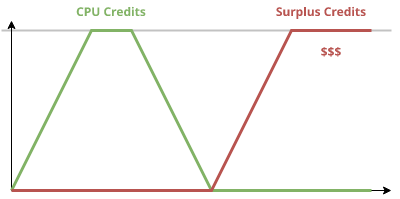
You can notice that you can burst the instance twice as long.
The two types of CPU credits are separate metrics, but essentially they track a single value. After all, if one is non-zero, the other is guaranteed to be 0.
In this sense, surplus credits are negative credits:
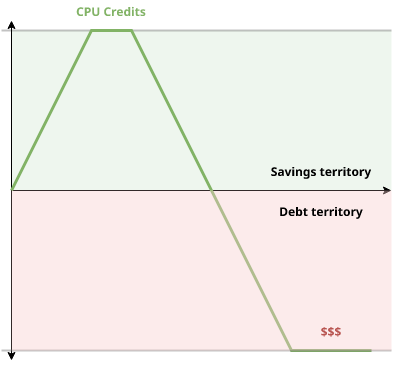
The way I like to think about them is that CPU credits track the "savings" while surplus credits represent "debt". And when you get into debt too much, you'll get charged for it.
Comparing costs
In unlimited mode, you get charged for surplus credits over the maximum. Fortunately, this cost does not vary between instance types and regions, it's $0.05 for every vCPU hour (60 credits).
The problem is that this system makes compute costs dependent on how you use the instance, while in standard mode you know it exactly beforehand.
Let's see the case for the t3.nano instance!
The baseline price for the instance is $0.0052 an hour. On a monthly basis, that will set you back $0.0052 * 24 * 30 = $3.744. This is the number you
usually associate with the cost of the instance.
Calculating the surplus credits is a bit more involved. The t3.nano has 2 vCPUs and the baseline performance is 5% (this is the amount covered
by the generation of CPU credits). The maximum cost is then 2 * 0.95 * 24 * 30 * $0.05 = $68.4.
Yes, that's an 18-fold difference.
Infinite loops
The problem is usually not that your app needs just a little bit more juice to handle all the visitors but when something goes wrong and a runaway process consumes 100% CPU non-stop. In standard mode, you'll notice it eventually when the CPU throttling kicks in and your app stops responding. But in unlimited mode, albeit slower, the instance is likely to continue working as no throttling takes place. It's likely that the first indication that something is wrong comes with the next AWS bill.
And where you get to choose between the two? At the bottom of the page when you launch an EC2 instance:

And it is checked by default for all t3 instances.
Notifications
Fortunately, there are CloudWatch metrics you can track to detect such problems. The CPUCreditsBalance is available for both standard and unlimited
mode, while the CPUSurplusCreditsBalance and the CPUSurplusCreditsCharged are for unlimited mode only.
I recommend setting an alarm for the CPUSurplusCreditsCharged at the very least. This will alarm you when the CPU is getting involved in your bottom line
and gives you the early warning that something is wrong.
For standard mode, you might already have some sort of monitoring for your app that alerts you when it goes unresponsive or too slow. But setting an alarm
for when the CPUCreditsBalance runs too low is also a good idea.
Should you use unlimited mode?
For mission-critical systems, yes.
Unlimited mode keeps the system responsive even when it is able to do so barely until you wake up in the morning and have a chance to investigate. Paying for a few surplus credits to bridge the time from having a runaway process and being able to remedy it. But don't forget to set up an alarm so that you know there is a problem.
The other valid use-case is when you consistently use more CPU than the baseline performance. In this case, you plan for this cost. And since paying for surplus credits is cheaper than switching to a larger instance with a higher baseline, it saves you money.
In every other case, opt for the standard mode to avoid costly surprises.

