
Intro to Lucene
How to build your Search Engine


Lucene is a Java library for indexing and searching that you can embed into your Java application to build a Search Engine. Also, you can find many popular tools that build on top of Lucene like ElasticSearch or Solr.
Lucene's initial release was in 1999 and it is actively developed ever since.
Why we need Search Engines
Providing search capabilities by directly querying an SQL database is certainly an option, but in many cases, it can be tricky to get it right.
Consider full-text searching where the user needs to find relevant items in a large volume of textual content. This can be implemented with an SQL query using like and wildcard,
but it might return irrelevant results. For example, with a query like "WHERE text LIKE %some%" we'll also get back results that contain "something" or "handsome" but do not
contain the word "some". On the other hand, the naïve SQL approach might also exclude valid results. For example, if the user searches for "running", it might be relevant to
show content with words such as "runs", "run", "ran", or even "jog". (Note: this is not to say that database engines can't handle full-text searching at all — some of them have
additional capabilities to support this use-case.)
Also for a Search Engine, it's very important to show the most relevant results with high performance, especially when there are many results for a query.
Lucene helps with all that with its text analysis and ranking capabilities. You can think about Lucene as a Database geared towards the fuzzy matching and text analysis and it's designed to return only the most relevant results.
So while an SQL database typically returns all results that exactly match a given query, Lucene shows the best matching ones.
How it works
Indexing
At the heart of Lucene, there's the index which is a schemaless document database. This needs to be populated by turning content into documents.
A document is a set of named fields with one or more values. Values are stored in text, so search-relevant properties need to be converted if they are not in the plain text already. Each potential search result should get its document. For example, a book store application that allows searching might create a document for each book.
public Document toDocument(Book book) {
Document document = new Document();
document.add(new TextField("title", book.title(), Field.Store.YES));
document.add(new TextField("author", book.author(), Field.Store.YES));
document.add(new TextField("summary", book.summary(), Field.Store.YES));
return document;
}Because the document does not have to adhere to a strict schema it's possible to iteratively build the search index by gradually adding additional fields to new documents.
Lucene does not support relations between documents, so the content has to be denormalized (flattened) when turned into documents.
The next step then is to analyze the documents and add them to the index. A Lucene Analyzer consists of Tokenizers to turn the text into individual terms and TokenFilters to change, remove and add terms. For example tokenization of a sentence might happen based on whitespace and punctuation, and filtering of the tokens can remove irrelevant stop words such as "and" or "the", and add new terms for other forms of a term, for example, "running" for "run". Lucene comes with many different Analyzers that consist of different combinations of Tokenizers and TokenFilters, and it's also possible to define custom Analyzers.
For example, the StandardTokenizer tokenizes content based on grammar and filters the terms making all of them lowercase. It is also capable of removing tokens based on a configuration.
To index the Document we also need a Directory to store it. This is usually a real directory on a filesystem that stores the index files.
private void index(Directory indexDirectory, Document book) throws IOException {
try (Analyzer analyzer = new StandardAnalyzer();
IndexWriter writer = new IndexWriter(indexDirectory, new IndexWriterConfig(analyzer))) {
writer.addDocument(book);
}
}At this point, the index contains the documents, ready to accept search queries.
The index in reality is an inverted index. It contains all the unique terms that appear in any of the indexed documents and for each term a list of documents in which they appear. This structure enables the fast full-text capabilities of Lucene.

Searching
Searching for documents in Lucene is done via queries, and there are multiple ways to get them.
Ad-hoc queries can be easily created using the Query Parser, which can parse a String that contains search directives. Some examples:
- "lucene": match documents that have "lucene" in any of their fields
- "title:lucene" matches documents with "lucene" in their title field
- "lucene or search": match documents that contain "lucene" or "search"
It can be useful for testing, but it has its limits because composing a more complex query this way can be tedious and error-prone.
A better option is to programmatically create Query objects. For example, the following TermQuery is used to match documents where the title contains "lucene".
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(indexDirectory));
Query query = new TermQuery(new Term("title", "lucene"));
int limit = 20;
List<Document> documents = searcher.search(query, limit);There are other types of queries too. For example, the FuzzyQuery relies on the Damerau–Levenshtein distance algorithm to match documents that have similar, but not necessarily identical content.
With the BooleanQueries it's possible to combine other queries to create complex search queries. For example the following query matches on documents where the title or the summary contains "lucene":
new BooleanQuery.Builder()
.add(new TermQuery(new Term("title", "lucene")), BooleanClause.Occur.SHOULD);
.add(new TermQuery(new Term("summary", "lucene")), BooleanClause.Occur.SHOULD);
.build();When a Query is executed, Lucene finds all the matching documents and then orders them based on relevance — or based on an explicit sorting criterion if specified. Finally, it returns the top X results.
Relevance is calculated by Lucene's scoring algorithm, which is one of the most important components. Traditional queries in databases either fully match or do not march at all for a record. However, when the full-text search comes into play with various fuzzy matching techniques, it becomes an important question of how well those results match the query. For example, if you search for "quick brown fox", it makes sense to get results containing just "quick fox" or "brown fox", but if there's a result that contains the full query, it's best to show that to the users first.
The score is calculated for each matching document and each matching term in the query. The formula takes quite some factors into account, such as:
- Term Frequency: how many times the term occurs in the document
- Term's Inverse Document Frequency: how common or rare the term is across all the documents
- The field's length
Lucene allows to customize this mechanism in multiple ways, for example, importance of fields can be boosted or even the whole scoring mechanism can be customized by supplying a custom Java implementation.
Build your own Search Engine
Lucene provides the tools you need to build a Search Engine into your application, but it's up to you to design it according to your needs. Let's conclude the post with a few aspects that are worth thinking about.
Relevance can be measured by precision (how many retrieved items are relevant) and recall (how many relevant items are retrieved).
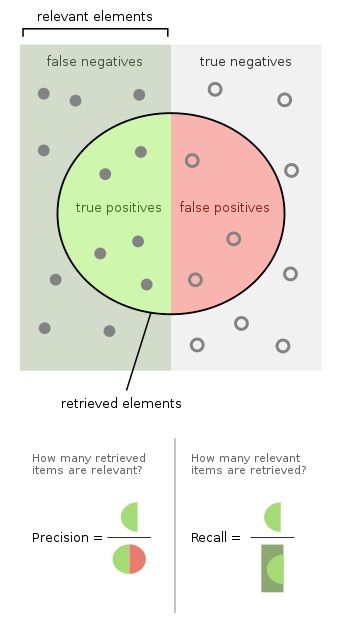
(Source: Wikipedia)
These factors greatly depend on how the search is configured, for example, which fields are searchable and what kind of fuzzy matching is used. It also affects the speed of the queries that the users can observe.
Search configuration also has a direct implication on the time and space required to index all the data. This also affects availability: how easy it is to rebuild the whole index in case of migration or catastrophic events.
From a content management point of view, there are also things to be considered. Whenever the content is updated, the changes need to be reflected in the search index as well. Probably it's a good idea to design your application to be resilient against missing or partially missing search indexes. This might include some kind of notification for the users that the provided results are not complete or even a full-blown administrative interface that can be used to reindex content when it is needed. Finally, it can be important to measure and analyze the usage (e.g. popular queries and results), potentially feeding this information back to the search engine — for example by ranking the most popular items higher.
Finally, it's important to clearly define these expectations. Regardless of how well you design your system, chances are that it can not compete with the speed and accuracy of popular public search engines. But this should not stop you from implementing a search for your next idea, done right, the result will be quite awesome.
Read more
- Official Lucene Website
- Lucene in Action, Second Edition - a pretty old book, but still the most up-to-date overview material I found on the subject
- Introduction to Apache Lucene from Baeldung
- Elasticsearch: The Definitive Guide - What Is Relevance?
