
How to reproduce a Lambda function's environment variables locally
How to reproduce the environment for efficient local Lambda development


Develop Lambdas locally
Getting started with Lambdas usually involves a lot of trial-and-error which means a lot of redeploys. Change something, deploy, refresh in the browser. While the deployment can be fast, it still takes multiple seconds, not to mention it's way harder to set breakpoints and see what the code actually does.
There are projects to simulate the software environment and the event/context objects, but there are
more important environment variables that are missing: the ones you assign to the function.
I was looking for a way to run the Lambda code locally with the environment variables set and also with the permissions the live function will get. You can read about such a solution in this post.

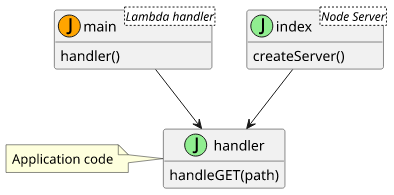
Separating the handler
If you don't use an emulated environment that sets the event/context arguments then the first thing is to separate the main application code
from the Lambda handler so that it can be reused for a local application. Let's say you have a function that handles GET requests and it uses the request path.
// main.js
const handler = require("./handler");
module.exports.handler = async (event) => {
return handler.handleGET(event.path);
};Then the handler.js does all the heavy lifting, but without any Lambda-specific code:
// handler.js
module.exports.handleGET = async (path) => {
return {
statusCode: 200,
headers: {
"Content-Type": "text/html",
},
body: `Hello world from ${path}`,
};
};The benefit of this separation is that a non-Lambda code can also call this handler. For example, a NodeJs HTTP server can use the application code to produce the same responses as the Lambda.
// index.js
const handler = require("./handler");
const http = require("http");
const port = 3000;
const processResponse = (res) => async (lambdaResponse) => {
if (lambdaResponse.headers) {
Object.entries(lambdaResponse.headers).forEach(([k, v]) => res.setHeader(k, v));
}
res.statusCode = lambdaResponse.statusCode;
res.end(lambdaResponse.body);
};
const server = http.createServer((req, res) => handler.handleGET(req.url).then(processResponse(res)));
server.listen(port, (err) => {
if (err) {
return console.log(err);
}
console.log(`server is listening on ${port}`);
});With a simple node index.js, you'll see the same output.
A small part of the code (the main.js) can only be tested by uploading to the Lambda service, but the majority is separated. With a setup similar to this one
it's easy to develop locally and upload to the real environment only occasionally.
Environment variables
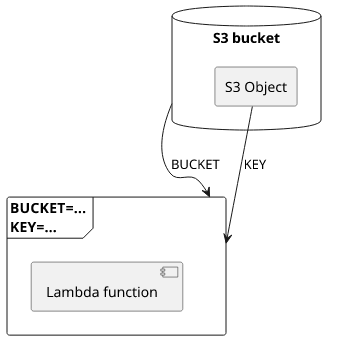
A Lambda function is unlikely to exist on itself. Usually, it interacts with other services, like databases such as S3 or DynamoDB, or message queues like SNS and SQS. Their addressing is passed as environment variables.
For example, a function might get an S3 bucket's generated name so that it can be used as a database to read objects.
resource "aws_s3_bucket" "bucket" {
force_destroy = true
}
resource "aws_s3_bucket_object" "object" {
bucket = "${aws_s3_bucket.bucket.bucket}"
key = "index.html"
content = "Bucket content"
}
resource "aws_lambda_function" "lambda" {
# ...
environment {
variables = {
BUCKET = aws_s3_bucket.bucket.id
KEY = aws_s3_bucket_object.object.id
}
}
}When you deploy this infrastructure, the real Lambda will have access to the object via process.env.BUCKET and process.env.KEY while the local one does not.
If you want to write automated tests you can do the same separation between the function and the AWS services as we did with the handler code. But when you just want to get the function out of the door and develop as rapidly as possible, it is not good.
But the solution is actually not hard. Terraform keeps track of the environment inside the state so that you just need to extract that and set at the current environment.
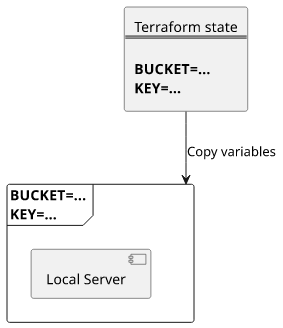
To get the environment variables for a given $FUNCTION, you can use this script:
ENV_VARS=$(terraform state show $FUNCTION | \
sed -n '/environment {$/,/}$/p' | \
sed '1,2d;$d' | \
awk '{print gensub(/^[^\"]*\"([^\"]*)\"[^\"]*\"(.*)\"[^\"]*$/, "export \\1=\"\\2\"\n", "g" $0)}')This uses some black magic to process the Terraform state output, but it sets the ENV_VARS variable to a list of export statements:
export BUCKET="..."
export KEY="..."Then all you need is to run these before calling node index.js:
PARAMS="$ENV_VARS"
COMMAND="($(echo $PARAMS) ; bash -c \""$@"\")"
eval "$COMMAND"AWS_REGION
An important environment variable not managed by Terraform is the AWS_REGION. This influences how AWS SDK services behave, therefore it is important to
mimic the production setting.
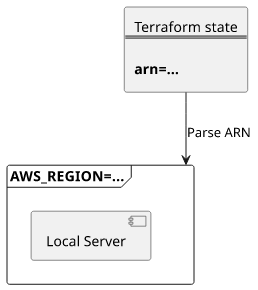
The region the function is deployed to is not present in the Terraform state as a separate value. But fortunately, the arn is, and it has a fixed structure:
arn:<partition>:<region>:<service>:<region>:<account>:<resource>. By parsing the Lambda function's ARN we can set the environment variable:
REGION=$(terraform state show $FUNCTION | \
awk '/arn/ {print gensub(/^\"(.*)\"$/, "\\1", "g", $3)}' | \
head -1 | \
awk -F: '{print "export AWS_REGION="$4}')Roles
But Lambda functions use another crucial set of environment variables: the execution role's AWS_ACCESS_KEY_ID, AWS_SECRET_ACCESS_KEY, and the
AWS_SESSION_TOKEN. Unfortunately, these are not available in the Terraform state file, so we need a different solution here.
Let's say the function wants to read the object from the bucket:
module.exports.handleGET = async (path) => {
const bucketContents = (await s3.getObject({
Bucket: process.env.BUCKET,
Key: process.env.KEY,
}).promise()).Body.toString("utf8");
return {
statusCode: 200,
headers: {
"Content-Type": "text/html",
},
body: `The content of the bucket: ${bucketContents}`,
};
};The function's role has access to the object, but how to reproduce that locally?
The solution is to assume the role the same way the Lambda service would do. In that case, the local server will have credentials with the same policies as the real thing.
Assume role policy
But the role's assume role policy only lists the Lambda service:
{
"Version": "2012-10-17",
"Statement": [
{
"Action": "sts:AssumeRole",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Effect": "Allow"
}
]
}And no matter what permissions you have, AWS will deny the assume-role operation.
As a solution, you can temporarily relax the requirements giving access to all users in the account. But it should not be hardcoded as it is a security vulnerability if you forget to remove it.
To achieve this I've made a small Terraform module that takes care of modifying the assume role policy based on an attribute.
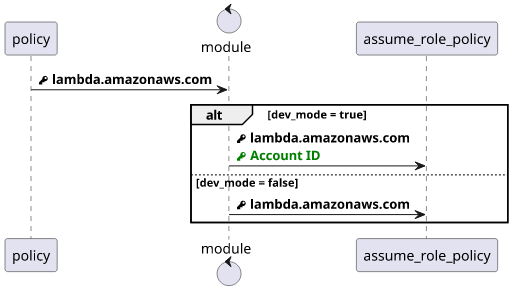
To use it, declare the module and pass the required arguments:
module "devmode_assume_role_policy" {
source = "github.com/sashee/local-lambda-environment"
dev_mode = var.dev_mode
}
resource "aws_iam_role" "lambda_exec" {
assume_role_policy = module.devmode_assume_role_policy.policy
}Optionally, you can also pass a policy if you want to customize it. By default it allows lambda.amazonaws.com service to assume the role.
If you pass true as the dev_mode argument, you'll be able to assume the role locally.
Role variables
The last step is to get the role's ARN from the Terraform state, assume the role, and set the resulting credentials to the environment.
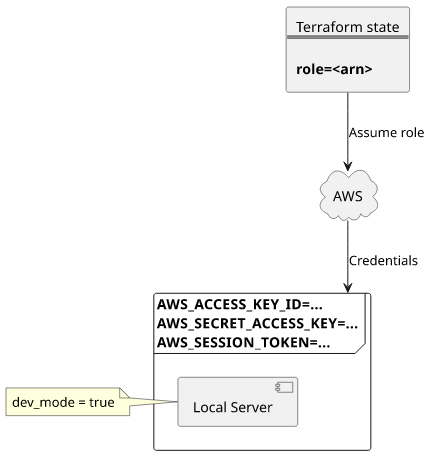
The script to do that:
ROLE=$(aws sts assume-role \
--role-arn "$(terraform state show $FUNCTION | \
awk '/role/ {print gensub(/^\"(.*)\"$/, "\\1", "g", $3)}')" \
--role-session-name test | \
jq -r '.Credentials |
{AWS_ACCESS_KEY_ID: .AccessKeyId, AWS_SECRET_ACCESS_KEY: .SecretAccessKey, AWS_SESSION_TOKEN: .SessionToken} |
to_entries[] |
"export \(.key)=\"\(.value)\"\n"' \
)Putting it together
Finally, combine the two set of environment variables and start the local server:
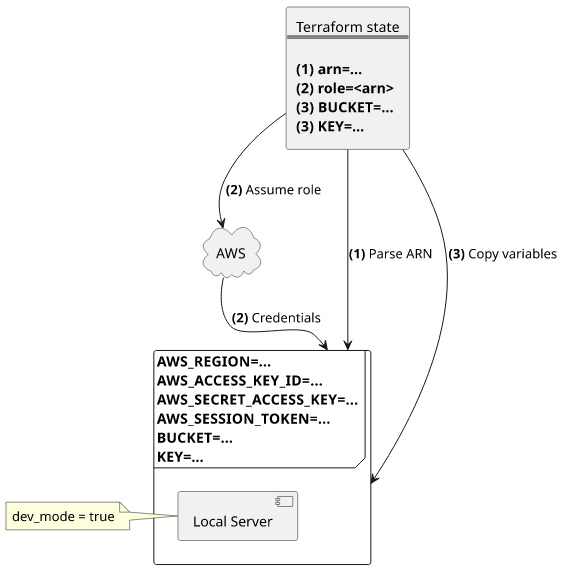
The complete function is this:
FUNCTION="aws_lambda_function.$1"
shift
ENV_VARS=$(terraform state show $FUNCTION | \
sed -n '/environment {$/,/}$/p' | \
sed '1,2d;$d' | \
awk '{print gensub(/^[^\"]*\"([^\"]*)\"[^\"]*\"(.*)\"[^\"]*$/, "export \\1=\"\\2\"\n", "g" $0)}' \
)
ROLE=$(aws sts assume-role --role-arn "$(terraform state show $FUNCTION | \
awk '/role/ {print gensub(/^\"(.*)\"$/, "\\1", "g", $3)}')" --role-session-name test | \
jq -r '.Credentials |
{AWS_ACCESS_KEY_ID: .AccessKeyId, AWS_SECRET_ACCESS_KEY: .SecretAccessKey, AWS_SESSION_TOKEN: .SessionToken} |
to_entries[] |
"export \(.key)=\"\(.value)\"\n"' \
)
REGION=$(terraform state show $FUNCTION | \
awk '/arn/ {print gensub(/^\"(.*)\"$/, "\\1", "g", $3)}' | \
head -1 | \
awk -F: '{print "export AWS_REGION="$4}')
PARAMS="$ENV_VARS $ROLE $REGION"
COMMAND="($(echo $PARAMS) ; bash -c \""$@"\")"
eval "$COMMAND"And to use it, first pass the Terraform resource's address followed by the command to run:
./run.sh aws_lambda_function.lambda "node index.js"The environment variables and the roles are all in place locally.
Conclusion
The ability to run your Lambda functions locally without deploying it every time there is a change is essential for an efficient workflow. Luckily, with the combination of the Terraform API and the AWS CLI, it is possible to reproduce the essential environment variables that let the locally run function interact with other services the same way the deployed one does.

