
How to Bash and jq: generate statistics for a REST API
Walkthrough for writing easy-to-read and performant scripts


Bash scripts are infamous for their maintainability, but with pipes and small functions, the result
can be terse, readable code. And it's not only code quality: writing concurrent applications is a
hard task, but it's easy to achieve in Bash by relying on this mechanism. jq — a tool to query
and manipulate JSON — fits nicely into this world.
In this tutorial, we'll create a script step by step to analyze content available on a REST endpoint.
The Goal
For the sake of this post, the backend application is a dummy blog engine running on localhost. You can find it on GitHub if you'd follow along. It provides the following API endpoints:
/posts?pageNumber=<num>: List metadata for all posts in a paginated list: ID, title and tags./posts/<post_id>: Get all details regarding a post, including its full text content.
The goal is to calculate the percentage of Bash-related content compared to all posts in the system, based on character count. A post can be considered Bash-related if it has the "Bash" tag.
0. Getting started: a sneak peek at the endpoints
As a first step query the posts available in the blog. To get the data simply curl the endpoint:
» curl "http://localhost:8080/posts?pageNumber=0"
{"count":10,"currentPageNumber":0,"lastPageNumber":1,"posts":[{"id":1,"title":"The best Javascript frameworks in 2020","status":"draft","tags":["Javascript"]},{"id":2,"title":"Vim in 5 minutes","status":"published","tags":["Bash","Vim"]}, ... ]}The response contains an unformatted JSON output; everything is squeezed into a single line so it's a bit hard to read.
To get a better view of the data, let's pipe the output of curl into jq to get some
nice formatting:
» curl "http://localhost:8080/posts?pageNumber=0" | jq
{
"count": 10,
"currentPageNumber": 0,
"lastPageNumber": 1,
"posts": [
{
"id": 1,
"title": "The best Javascript frameworks in 2020",
"status": "draft",
"tags": [
"Javascript"
]
},
{
"id": 2,
"title": "Vim in 5 minutes",
"status": "published",
"tags": [
"Bash",
"Vim"
]
},
...
]
}Because the API is paginated, the posts are wrapped in a container object.
Let's take another look, this time on the details of a single post:
» curl "http://localhost:8080/posts/1" | jq
{
"id": 1,
"title" :"The best Javascript frameworks in 2020",
"content": "Lorem ipsum dolor sit amet, consectetur adipiscing elit...",
"tags": ["Javascript"]
}Since this is just a dummy blog engine, all posts have generated Lorem Ipsum
as their content. The single interesting stuff in this second response is the content field. Let's
use jq to extract it:
» curl "http://localhost:8080/posts/1" | jq '.content'
"Lorem ipsum dolor sit amet, consectetur adipiscing elit..."The argument passed to jq specifies a transformation, returning only the value found in the content
field.
curl and jq does a fairly good job by default, but there are a few flags that might come in handy
when they are used in a script.
Most flags can be set using a short (e.g. -x) and a long-form (e.g. --some-opt). For better
readability use the long versions in scripts.
Make curl calls more robust
By default, curl shows a progress bar for longer operations on its standard error output. Because
of this, our script might also display it whenever curl is invoked under the hood. To make the output
a bit cleaner, use the --silent (or -s) flag to enable silent mode. Note: the progress bar does
not affect programs downstream of the pipeline, as it's presented in the standard error, not the standard
output.
Using --silent has the undesired consequence of silencing error messages as well. To reenable them,
use --show-error (or -S).
To make curl handle the Location header and the 3XX response codes, add the --location (or -L) flag.
In case of an HTTP error code, curl will just output the error document returned by the server.
These error documents either have to be filtered down the pipeline, or they might cause problems.
To avoid this, pass the --fail (or -f) flag to make curl silently fail on server errors. Although
curl will emit an error message on its standard error relating to the HTTP error code, the error message
from the server will be suppressed, which can hinder debugging.
Use compact and raw output for jq
jq outputs JSONs in a nice, human-readable format. This is not convenient for pipelines,
because the data is passed around line-by-line. In order to squeeze the result of jq transformation
into a single line, use the --compact-output (or -c) flag.
For example, let's try the .posts[] transformation to decompose the list of posts and print each element
in a single line:
» curl http://localhost:8080/posts | jq --compact-output '.posts[]'
{"id":1,"title":"The best Javascript frameworks in 2020","status":"draft","tags":["Javascript"]}
{"id":2,"title":"Vim in 5 minutes","status":"published","tags":["Bash","Vim"]}Another useful flag for jq is the --raw-output (or -r). When you query a single String attribute,
by default it will be returned in a quoted form. Use this flag to omit the quotes:
» curl "http://localhost:8080/posts/1" | jq --raw-output '.content'
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Nulla vulputate tortor ut diam rhoncus cursus...1. Foundations
Before diving into the implementation, let's discuss some general, high-level decisions about the architecture of the script.
Use #!/bin/bash instead of #!/bin/sh
On many systems /bin/sh is just a symlink to /bin/bash, but this is not a given.
/bin/sh represents the POSIX compliant system shell, but under the hood, it can be
something different than Bash.
If you only target Bash, from a testing point of view it's much easier to explicitly
rely on it than to support anything the /bin/sh might refer to:
#/bin/bashUse Bash Strict Mode
Bash is great because it can be used easily in an interactive terminal session. As such, it processes commands a bit differently than a typical programming environment. For example, when you type a bad command to your shell, you expect it to print the error and continue to accept further commands. This makes Bash an excellent tool for trial and error.
However, the very same ergonomic feature can cause quite some trouble when Bash is used as a programming language. Consider the following script:
#!/bin/bash
echooo hello #o-oh, here's a typo!
echo worldIf you know other programming languages you might expect that running it will print nothing but an error. But because Bash is lenient by default it continues to execute commands even after an error occurred:
./hello-wolrd.sh: line 3: echooo: command not found
worldTo make life easier, start the script with the following:
set -euo pipefailIt adds some strictness to Bash to make it better suited for programming:
- exit immediately on failures
- exit immediately if an undefined variable is referenced
- make errors visible in pipelines
More information: Use Bash Strict Mode (Unless You Love Debugging).
Rely on Pipelines
Pipelines are one of the essential building blocks of shell scripts, connecting the standard output of the preceding command to the standard input of the following one. (Standard error can also be piped to the next command, but we don't do that in this script.)
first_command | second_command | third_commandPipelines are beneficial:
- Readability. Combining commands can't be much simpler. No need for temporary variables, just define the transformations which will perform changes on the data flowing through the pipe.
- Concurrency. Each command in the pipeline runs concurrently. When the pipeline handles multiple data, all commands in the pipeline can work concurrently.
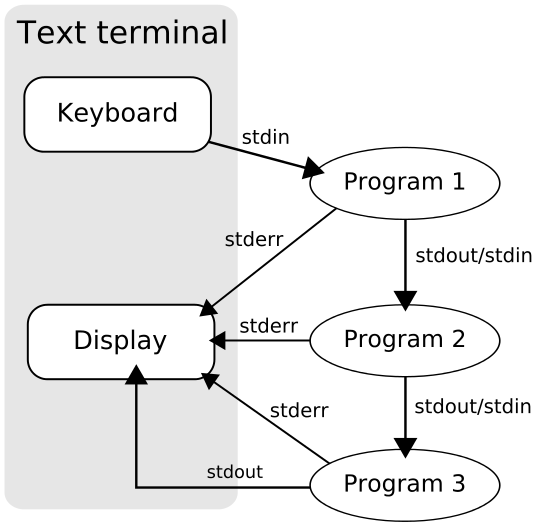
The above illustration is from Wikipedia where you can read more information on the Unix Pipeline.
Use local for function-specific variables
If you can wire together everything with pipes you don't need variables to store intermediate computation results.
However, if you have to define variables annotate them with local. This ensures that the variable is only
available inside the function and it's not polluting the global scope.
local my_var="Hello"2. Scrape all data
Now we know how the Blog's REST API looks like and have a basic idea about the structure of the script, let's create a script that collects the data from the server.
#!/bin/bash
# strict mode
# http://redsymbol.net/articles/unofficial-bash-strict-mode/
set -euo pipefail
main()
{
get_posts
}
get_posts() {
local response=$(curl --silent --show-error "http://localhost:8080/posts")
echo $response
}
mainThe var=$(...) form executes the given command and captures its standard output in a variable.
It's preferred to use this form over the legacy backtick notation
as these expressions can be nested.
Note, that Google's Bash style guide
recommends to put the declaration and the assignment of local variables into different lines because local
does not propagate the exit code of substituted commands. Since I'm not using the exit codes of substituted commands
in this script I've decided to neglect this advice for the sake of readability.
The main function seems to be superfluous for now, but in the future, it will contain the high-level
logic of the script. Because usually, this is the most important part for the reader, I defined
it as the first function in the script.
Currently, the output of the program only contains the first page of posts only. Let's make it recursive to take care of the pagination:
#!/bin/bash
# strict mode
# http://redsymbol.net/articles/unofficial-bash-strict-mode/
set -euo pipefail
main()
{
get_posts 0
}
get_posts() {
local page_num=$1
local response=$(curl --silent --show-error "http://localhost:8080/posts?pageNumber=$page_num")
echo $response
local last_page_num=$(echo $response | jq --compact-output '.lastPageNumber')
if [ "$page_num" != "$last_page_num" ]; then
local next_page=$(($page_num + 1))
get_posts $next_page
fi
}
mainThe addendum checks if the response is the last page, and if not, it calls itself one more time for the next page.
Because there are 12 posts in the blog engine, the output looks like this:
{"count":10,"currentPageNumber":0,"lastPageNumber":1,"posts":[{ ...first 10 posts... }]}
{"count":2,"currentPageNumber":1,"lastPageNumber":1,"posts":[{ ...last 2 posts... }]}3. Parse API response
We have all the data from the server, but the server returns a wrapper object with an array of posts for each HTTP request.
Also, each post in the response contains the title of the post, which is not needed for our calculation.
With jq it's easy to reshape the server's response to fit our needs:
main()
{
get_posts 0 | parse_response
}
...
parse_response()
{
jq --compact-output '.posts[] | {id: .id, status: .status, tags: .tags}'
}The output of the script now only contains the important data, one post in each line:
{"id":1,"status":"draft","tags":["Javascript"]}
{"id":2,"status":"published","tags":["Bash","Vim"]}
{"id":3,"status":"published","tags":["Java"]}
{"id":4,"status":"draft","tags":["Terraform","AWS"]}
{"id":5,"status":"draft","tags":["Terraform"]}
{"id":6,"status":"published","tags":["Git"]}
{"id":7,"status":"published","tags":["Bash"]}
{"id":8,"status":"published","tags":["CORS","Security"]}
{"id":9,"status":"draft","tags":["Java","Security"]}
{"id":10,"status":"published","tags":["ZSH","Bash"]}
{"id":11,"status":"published","tags":["Java"]}
{"id":12,"status":"published","tags":["PlantUML","Javascript","Ruby"]}4. Exclude draft posts
Amongst the posts, there are some not-yet-published draft articles. Let's filter them out:
main()
{
get_posts 0 | parse_response | only_published
}
...
only_published()
{
jq --compact-output '. | select( .status=="published" )
| del( .status )'
}The jq command above chains two operations. The first one suppresses non-published posts while the
latter one removes the now irrelevant status property. Note, that probably it would be better to keep
this data till the end to ease debugging. I removed the unnecessary properties to make the output
of the intermediate steps free from noise, hopefully making the post easier to follow.
Now the output looks like this:
{"id":2,"tags":["Bash","Vim"]}
{"id":3,"tags":["Java"]}
{"id":6,"tags":["Git"]}
{"id":7,"tags":["Bash"]}
{"id":8,"tags":["CORS","Security"]}
{"id":10,"tags":["ZSH","Bash"]}
{"id":11,"tags":["Java"]}
{"id":12,"tags":["PlantUML","Javascript","Ruby"]}5. Add content length for each post
For each post, we have to get its full content from the second API endpoint. Until now, we
just piped various commands together, but in this case, we have to execute a series of commands based
on the id field in each JSON object.
For this reason, I use xargs, which is designed to build and execute command lines from standard input:
main()
{
get_posts 0 | parse_response | only_published \
| xargs -d'\n' -I '{}' bash -c "add_length '{}' ."
}- The
-Ispecify the placeholder to be replaced by the content coming from the standard input. - To not strip quotes in the arguments, we have to specify the delimiter explicitly (Why does xargs strip quotes from input?)
With this, add_length will be called with each JSON object as an argument. Let's define it:
add_length()
{
local post=$1
local id=$(echo $post | jq '.id')
local length=$(curl --silent --show-error "http://localhost:8080/posts/$id" \
| jq --raw-output '.content' | wc --chars)
echo $post | jq --compact-output '. + {length: '$length'} | del( .id )'
}
export -f add_lengthIn order to call a function with xargs
it has to be exported and called via a subshell.
The subshell could be invoked with sh, but to be consistent with my previous recommendations and to avoid
incompatibilities I explicitly call bash here.
With this change, the output now contains the length property for each post.
As an alternative to xargs, we could have used a simple loop that reads from the standard input.
However, xargs can spawn multiple processes. Depending on your workload, this might come in handy
to increase performance. In the following example, the number of processes is 4, specified by the -P flag:
xargs -d'\n' -I '{}' -P 4 bash -c "add_length '{}' ."In my case, when I've used 4 processes to query the content bodies I've measured roughly 2x speedup in the total execution time.
Now the output contains the length of each post:
{"tags":["Bash","Vim"],"length":494}
{"tags":["Java"],"length":694}
{"tags":["Git"],"length":344}
{"tags":["Bash"],"length":872}
{"tags":["CORS","Security"],"length":425}
{"tags":["ZSH","Bash"],"length":307}
{"tags":["Java"],"length":423}
{"tags":["PlantUML","Javascript","Ruby"],"length":408}Before going to the next section, let's refactor this to be a bit more readable. The implementation
details of calling xargs leaked to the main function. So let's extract it to its own separate place:
main()
{
get_posts 0 | parse_response | only_published | add_length
}
...
add_length()
{
xargs -d'\n' -I '{}' bash -c "add_length_ '{}' ."
}
add_length_()
{
local post=$1
local id=$(echo $post | jq '.id')
local length=$(curl --silent --show-error "http://localhost:8080/posts/$id" \
| jq --raw-output '.content' | wc --chars)
echo $post | jq --compact-output '. + {length: '$length'} | del( .id )'
}
export -f add_length_I've renamed the original function to add_length_, and wrapped the xargs related code
in a separate function. Now the main function is short and concise again.
6. Aggregate the character counts
Now we have all the important data: the tags and the length of each post. By aggregating this data, we can calculate the total length of all the bash and non-bash related posts.
Although jq's group_by function
can group elements based on any arbitrary expression, I'll introduce another transformation before
the grouping to precalculate the condition. This step replaces the tags array with a boolean that
indicates if the post has the "Bash" tag.
main()
{
get_posts 0 | parse_response | only_published | add_length | add_isBash
}
...
add_isBash()
{
jq --compact-output '. + {isBash: (. | any(.tags[] ; contains("Bash")))}
| del( .tags )'
}With this, the output is as follows:
{"length":584,"isBash":true}
{"length":785,"isBash":false}
{"length":432,"isBash":false}
{"length":962,"isBash":true}
{"length":529,"isBash":false}
{"length":393,"isBash":true}
{"length":504,"isBash":false}
{"length":523,"isBash":false}The last transformation is to actually perform the aggregation based on the isBash property.
So far all jq operations were executed in streaming mode: they were processing JSON objects
immediately as they were available from the previous step or from the REST endpoint.
To sum the lengths of all posts jq has to be instructed to wait for all the data. This can be
done with the --slurp (or -s) flag.
main()
{
get_posts 0 | parse_response | only_published | add_length \
| add_isBash | aggregate
}
...
aggregate()
{
jq --slurp --compact-output 'group_by(.["isBash"])[]
| map(.length) as $carry | .[0]
| . + {lengthTotal: $carry | add}
| del(.length)' \
| jq --slurp --compact-output '.'
}The transformation above performs the aggregation, producing two objects: a character sum for each Bash-related post, and a character sum for the rest of the content. For more information on how this function works see this related Stack Overflow thread.
Because it emits two separate objects, I've piped the result into jq again to slurp
everything to produce a single JSON:
[{"isBash":false,"lengthTotal":2773},{"isBash":true,"lengthTotal":1939}]7. Compile report
Now that we have all the data in place, it's easy to calculate the answer to the original question using
bc, the command line calculator.
main()
{
get_posts 0 | parse_response | only_published | add_length \
| add_isBash | aggregate | report
}
...
report()
{
while read object
do
local non_bash_length=$(echo $object | jq -c '.[] | select( .isBash==false ) | .lengthTotal')
local bash_length=$(echo $object | jq -c '.[] | select( .isBash==true ) | .lengthTotal')
local total=$(echo "$non_bash_length + $bash_length" | bc)
local ratio=$(echo "scale=4;($bash_length / $total) * 100" | bc)
echo "Ratio: $ratio %"
done < "${1:-/dev/stdin}"
}I could have used xargs again to capture standard input, but to demonstrate the alternative
I've used the while loop. It's a bit simpler, but lacks parallelism. The function captures the single
line we pass to its standard input and uses jq to parse it as a JSON and extract data from it.
(Note: I've used the -c flag for jq instead of --compact-output to make the code snippet a bit more compact.)
Finally, it invokes bc to calculate the result:
Ratio: 41.1500 %Bonus: show interactive output
Although the script works nicely, it's totally silent while it's working. If the script would require a longer time to finish, the users would not get any feedback during the calculation.
Fork the pipeline with tee to display each post as it's being processed:
main()
{
get_posts 0 | parse_response | only_published | add_length | tee /dev/tty \
| add_isBash | aggregate | report
}Summary, considerations
By relying on the pipeline concept, Bash scripts can be efficient and easy to understand.
Adding jq to the mix brings powerful JSON manipulation techniques to the table.
However, these scripts have their limitations. Although Bash is available in most environments, the tools used from the scripts might differ. These dependencies might make it hard to produce cross-platform code.
Bash is most efficient for integrating tools, not for implementing large programs and algorithms. If the script starts to get too big, consider using a different language, for example Python. In any case, consider using a linter, such as shellcheck, and if you are new to Bash, make sure to check out a good Cheat Sheet.
