
Dependency Injection Boundaries
Why you shouldn't @Autowire your next dependency.


I recently read the article Java: Spring Dependency Injection Patterns. The author considers the pros and cons of using Field, Setter, and Constructor Injection patterns. It's a great post, I recommend checking it if you haven't already. Reading it and its discussion on Reddit inspired me to write my 2 cents on this topic.
The post lists compelling reasons which injection pattern to use, but in my experience, it rarely matters which technique you choose first. In my previous projects, refactoring a class from Field to Constructor Injection was really painless. I could be lazy and start with Field Injection, then gradually upgrade when I hit a roadblock, for example regarding testability.
I think the more interesting question is: Should you even add the new dependency or not? Adding a new dependency is way too easy using any of the injection patterns, and it's comforting to be able to get the desired functionality in virtually any part of the codebase simply by @Autowiring it.
But adding an additional dependency is an architectural decision to be made. One extra dependency can result in a big chunk of extra downstream dependencies. The properties of each of these downstream dependencies affect how you can use, configure or test your component.
Sometimes this does not matter at all. For example, if you are shipping your application in one module, and relying mostly on end-to-end testing strategies (such as browser-based tests or a live staging server) to verify it, it might not be a big deal if some additional edges appear in the dependency graph.
However, there are some reasons to stop and think about how to align new modules in an existing system. In a recent project, I've come across two of them: testing and reusability.
Zero dependency is the best
This one is pretty obvious. If a module has no dynamically wired dependencies, it's the easiest to work with. There are multiple options on how to test components with dependencies, but not having them frees you from that hassle. There is no need to start the DI container or manually supply or mock its environment.
It's also easy to use in production code. You can use the DI container for convenience, but you don't have to
as a simple new will do.
Purity in the dependency graph
It's not always possible to have zero dependencies, but one should be picky about what to depend on. I think purity in a sense much like the concept of functional programming. The more side effect a module make, the harder it is to work with. For example:
- If it accesses a database, you have to provide it.
- If it requires connection to an external service, you have to make sure that it's possible.
- If it works with files, then you have to make sure that it works in different file systems, and generally that the required files are in place and cleaned up properly.
Or, as an alternative, you have to mock, but I think that leads to new problems. I am not a big fan of mocking in general, but I see its potential more in designing new modules, rather than using it as a surgical device when I have to break down a big dependency graph.
Anyway, having an impure component anywhere in the dependencies of your component affects the purity of your component as well. A module's purity is the lowest common denominator of its own purity and everything in its downstream dependency graph.
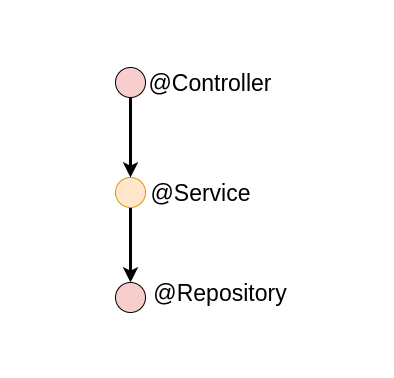
In the example above, it's no use that the business logic of the @Service in the middle is pure. If you'd like to use (or test) it in its full glory, you have to deal with impure code because in the background it makes contact with an impure component.
It has two important consequences when it comes to adding an extra dependency:
- you might lose the ability to easily test and work with your module
- and you might also limit the potential to reuse the component effectively; bringing it anywhere near a pure compoinent will make it impure and jeopardize its usability.
Configurability through manipulating dependencies
Another problem with injected dependencies is that sometimes you have to reuse a component in multiple projects in a slightly different way. In many cases, you have no other choice but to make this customization with the DI, by supplying different dependencies to the component. (Or supplying different dependencies to the dependencies of the module.)
While this is certainly an option, it's usually not convenient, and it gets even worse when you have to have multiple flavors of the same components live side by side in the same environment.
It also hinders maintainability as the configuration is made behind the magic curtain of the DI, not necessarily apparent when you look at the code.
An alternative: Shallow dependency graph
If you decide that adding the new dependency is risky, reducing the depth of the dependency graph can provide good alternatives.
For example, suppose you have a web application about movies and it has a dashboard that shows a summary of all the data you have. If you have a service component that calculates the average length of the movies found in a database for the dashboard, you might be better off if you just pass the relevant dataset to this component, rather than letting it talk to the database access service to get the necessary records for itself.
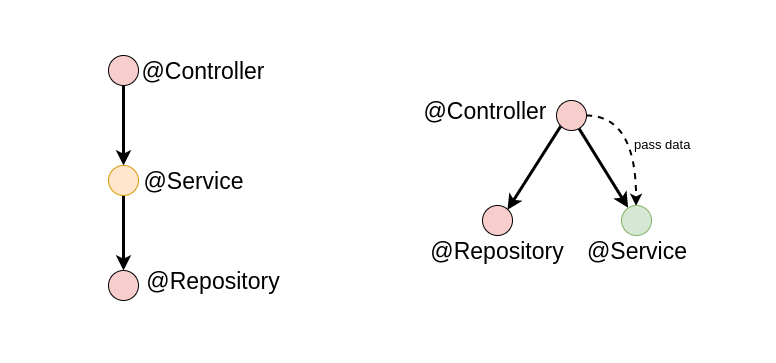
The version on the right, without the injected dependency is easier to use later. It's up to the caller to decide what data to pass, and it can use whatever query or service to get this data.
It's also easier to test, as the test-case have a multitude of options to get test data. If you have simple or no dependencies, then you can easily use the service without the DI container altogether.
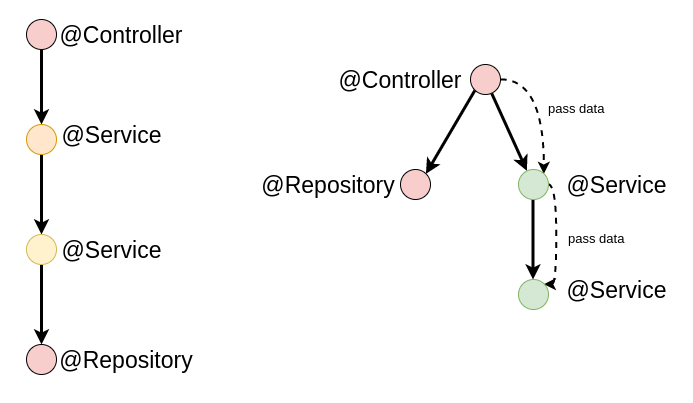
One might even go to the extremes and use the DI solely to wire infrastructure components (such as database, API's, and external connections), and use pure components for all business logic.
Of course, it's not a silver bullet solution and it has downsides to consider as well. The more layers you have to pass the required data through, the more likely that the resulting structure will be hard to modify and tightly coupled.
If you are interested, I'd recommend watching From Dependency injection to dependency rejection from Mark Seemann, an excellent talk on a similar subject.
Summary
The convenience of the DI is a great thing, and in most cases, it simplifies the mental model one has to maintain when working with parts of the whole codebase. However, as anything, it has pros and cons.
You should always consider the dependency graph of your application. Keep an eye on the properties of each component, and strategically decide where you draw the boundaries of the dependency injection.
