Dataset preparation for training a neural text-to-speech model with Piper TTS
Steps to transform a dataset to a format that can be used for the training input


Dataset transformation
The most enjoyable type of programming for me is to have a set of simple tools that I can use to implement complex functionality. This article describes one occasion where I wanted to convert a bunch of audio files to a format that can be used to train a neural text-to-speech model. And the tools I could use was Whisper for speech-to-text, ffmpeg for some generic audio processing, and NodeJS that is my daily driver for anything programming related.
To train a neural model with Piper TTS it expects the data in a specific format. There is a metadata.csv that defines the sentences and the links to the
audio files:
wavs/1.wav|sentence 1
wavs/2.wav|sentence 2That means I need to have the audio files and what is said in them.
I have a couple of video courses that contain audio, so I could just use those, and best of all they already have transcripts. But the problem is that the audio files are segmented by topic and not by sentence, so I can't just feed these into Piper:
$ ls -ln
total 29020
-rw-r--r-- 1 1000 1000 2608021 Aug 20 2023 0.flac
-rw-r--r-- 1 1000 1000 3089203 Aug 20 2023 10.flac
-rw-r--r-- 1 1000 1000 635958 Aug 20 2023 11.flac
-rw-r--r-- 1 1000 1000 1644288 Aug 20 2023 1.flac
-rw-r--r-- 1 1000 1000 2158459 Aug 20 2023 2.flac
-rw-r--r-- 1 1000 1000 3273004 Aug 20 2023 3.flac
-rw-r--r-- 1 1000 1000 1499988 Aug 20 2023 4.flac
-rw-r--r-- 1 1000 1000 1883249 Aug 20 2023 5.flac
-rw-r--r-- 1 1000 1000 3023884 Aug 20 2023 6.flac
-rw-r--r-- 1 1000 1000 1784131 Aug 20 2023 7.flac
-rw-r--r-- 1 1000 1000 2000489 Aug 20 2023 8.flac
-rw-r--r-- 1 1000 1000 4431717 Aug 20 2023 9.flac
-rw-r--r-- 1 1000 1000 17622 Aug 20 2023 index.tsx
-rw-r--r-- 1 1000 1000 1627315 Aug 20 2023 page_not_responding.webm
-rw-r--r-- 1 1000 1000 6268 Aug 5 14:00 transcript.txtMy first approach was to manually cut the audio files.
This was not fun. I got bored after getting ~25 minutes of audio, which is not bad but the process was definitely not something I'd want to do much longer.

Writing code
So I turned to the second approach: let's write some code!
I started with the "lazy" option where I tried to parameterize the tools in a way that achieves this without me writing code, such as trying to find the
senctence boundaries and cut the files with ffmpeg. This approach works for simple things, but gets frustrating very fast. So I moved on to the next stage: use
the tools as simple operations, such as ffmpeg's silencedetect filter or whisper's transcription and write the glue between them in JavaScript.
The workflow, roughly:
- use whisper to transcribe the audio
- find the sentence in the transcript
- since whisper outputs the timestamps as well, use ffmpeg to cut the audio into sentences
Of course, there were a lot of complications along the road, but the whole process is very linear (data => step 1 => step 2 => step 3 => output), and also it's rather easy to observe what is happening.
First, let's have the tools ready! I'm using Nix to install stuff I don't usually have.
# shell.nix
let
nixpkgs = fetchTarball "https://github.com/NixOS/nixpkgs/tarball/nixos-24.05";
pkgs = import nixpkgs { config = {}; overlays = []; };
in
pkgs.mkShellNoCC {
packages = with pkgs; [
openai-whisper-cpp
ffmpeg
nodejs_22
];
}Run nix-shell and everything is installed.
Next, download a model:
$ whisper-cpp-download-ggml-model base.enThat's all the preparation needed, so let's go with the code.
First, call Whisper to generate the transcript for the audio file:
export const transcript = addFileCache(async (file, modelFile) => {
return withTempDir(async (dir) => {
try {
await util.promisify(child_process.execFile)("ffmpeg", ["-nostdin", "-threads", "0", "-i", file, "-f", "wav", "-ac", "1", "-acodec", "pcm_s16le", "-ar", "16000", "processed.wav"], {cwd: dir});
await util.promisify(child_process.execFile)("whisper-cpp", ["-m", modelFile, "-f", "processed.wav", "--output-json-full", "--output-file", "result"], {cwd: dir});
}catch(e){
console.log(file);
throw e;
}
return JSON.parse(await fs.readFile(`${dir}/result.json`, "utf8"));
});
}, {calcCacheKey: (file, modelFile) => ["transcript_1", file, modelFile]});This is using my with-file-cache utility script to store the results in a cache directory as transcribing can take a couple of seconds.
Notice that Whisper needs the input in 16000 Hz sample rate, so ffmpeg needs to convert to that first. Notice how simple it is in a real programming language:
there is a temporary directory where ffmpeg can put its result file, then whisper can read that, do its magic, write its output, and finally the result is read
and returned. No piping magic where stdout gets somehow always polluted with logs, or arcane traps to clean up temp directories. It's a few lines, and I can
easily call it in an audioFiles.map((file) => transcript(file, model)) loop.
Whisper returns the sentences with offsets (timing):
...
{
"timestamps": {
"from": "00:00:33,640",
"to": "00:00:39,280"
},
"offsets": {
"from": 33640,
"to": 39280
},
"text": " With promises, you can have a flat structure and have only one call back at the end.",
"tokens": [But sometimes the sentences are broken to multiple blocks:
{
timestamps: [Object],
offsets: [Object],
text: ' For example, running a SQL query against a remote database is long-running, as it needs',
tokens: [Array]
},
{
timestamps: [Object],
offsets: [Object],
text: ' to send a net network request.',
tokens: [Array]
},So next I needed a function that combines these back into a single sentence:
const processTranscript = (transcription) => {
return transcription
.map(({offsets, text}) => ({offsets, text: text.trim()}))
.reduce(({finishedSentences, current}, element) => {
const finishing = element.text.match(/[.?!]$/) !== null
if (current === undefined) {
if (finishing) {
return {finishedSentences: [...finishedSentences, {...element, text: element.text}], current: undefined};
}else {
return {finishedSentences, current: element};
}
}else {
if (finishing) {
return {finishedSentences: [...finishedSentences, {offsets: {from: current.offsets.from, to: element.offsets.to}, text: [current.text, element.text].join(" ")}], current: undefined};
}else {
return {finishedSentences, current: {offsets: {from: current.offsets.from, to: element.offsets.to}, text: [current.text, element.text].join(" ")}};
}
}
}, {finishedSentences: [], current: undefined}).finishedSentences;
};Next, match the sentences to the transcript:
const matching = transcription.filter(({text}) => {
return sentences
.map(cleanSentence)
.includes(
cleanSentence(text)
);
})At first I thought that I could match the sentences in order of the transcript, but then checking for existence was way easier and I think it worked equally well.
```cleanSentence```` is a set of heuristics:
const cleanSentence = (sentence) => {
return sentence
.split(",").join("")
.split("(").join("")
.split(")").join("")
.split("/").join(" ")
.split(":").join("")
.split("1").join("one")
.split("2").join("two")
.split("3").join("three")
.split("10").join("ten")
.split("key word").join("keyword")
.split("'ll").join(" will")
.split("it's").join("it is")
.split("we're").join("we are")
.split("we've").join("we have")
.split("-").join(" ")
.split("can not").join("cannot")
.split("callback").join("call back")
.replace(/[.!?]$/, "")
.toLowerCase();
}There is probably a better way to do this, but seems like it's working for most sentences.
Next problem was that I realized that whisper's timestamps are not precise:
{
file: 'js-async-course/lesson-1/11.flac',
text: 'In the next lesson, we will start with async functions.',
offsets: { from: 6420, to: 9720 }
}Which is definitely not at the right spot:
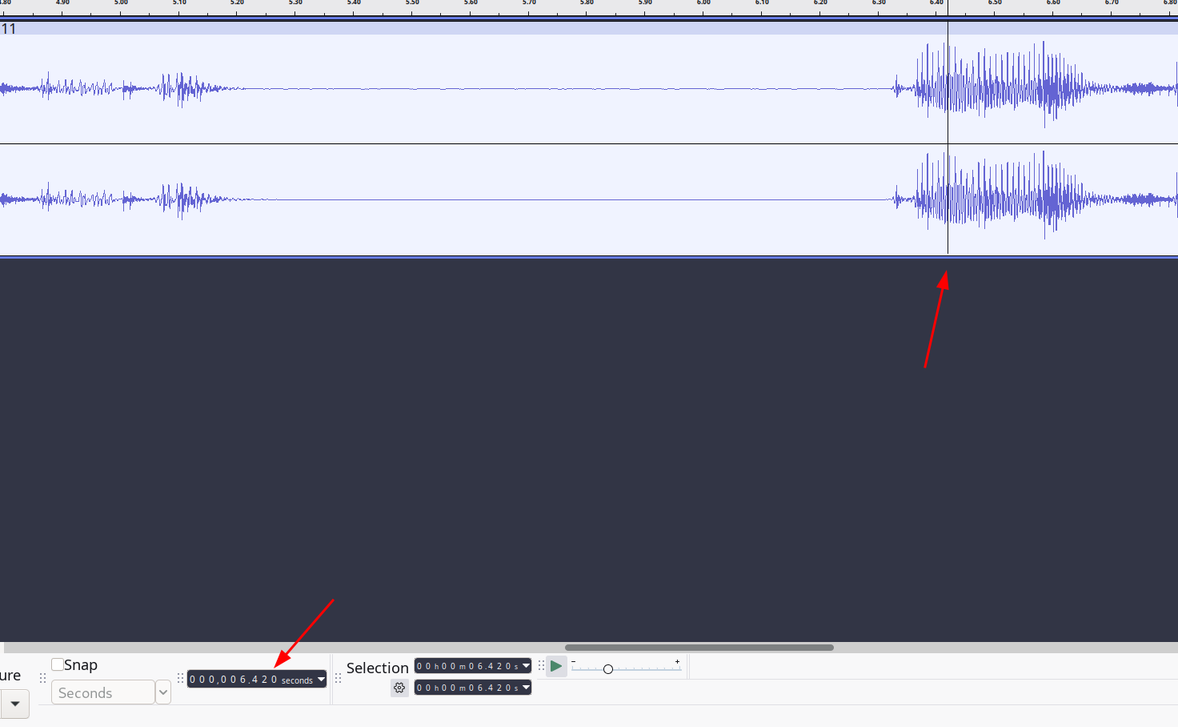
So, I needed a heuristic to move the sentence boundary to the closest silence. Here, ffmpeg's silencedetect comes helpful that outputs a list of silences
that it detects:
export const detectSilences = addFileCache(async (file, noise, duration) => {
const silenceRegex = /silence_end: (?<silenceEnd>[\d.]*).*silence_duration: (?<silenceDuration>[\d.]*)/;
const {stderr} = await util.promisify(child_process.execFile)("ffmpeg", ["-nostdin", "-i", file, "-af", `silencedetect=n=${noise}:d=${duration}`, "-f", "null", "-"], {});
const silences = stderr
.split("\n")
.filter((line) => line.match(silenceRegex) !== null)
.map((line) => line.match(silenceRegex).groups)
.map(({silenceEnd, silenceDuration}) => ({silenceEnd: Math.round(Number(silenceEnd) * 1000), silenceDuration: Math.round(Number(silenceDuration) * 1000)}))
.map(({silenceEnd, silenceDuration}) => ({silenceStart: silenceEnd - silenceDuration, silenceEnd}));
return silences;
}, {calcCacheKey: (file, noise, duration) => ["detectsilences_1", file, noise, duration]});Since the output is not JSON the code needs to do some magic on the output text to extract the silence list.
With the list of silences, the next step is to correct the sentence boundaries. At first I wanted to move them to the previous silence, but then realized that in some rare cases it needs to be moved to the next one. I ended up with this function:
const fixOffsetToSilence = async (file, offsets) => {
const silences = await detectSilences(file, "-30dB", "0.1");
const silencesWithBothEnds = await (async () => {
const length = await getLengthInMs(file);
return [
...(silences.some(({silenceStart}) => silenceStart <= 0) ? [] : [{silenceStart: 0, silenceEnd: 0}]),
...silences,
...(silences.some(({silenceEnd}) => silenceEnd >= length) ? [] : [{silenceEnd: length, silenceEnd: length}]),
];
})();
const findPoint = (timestamp, alignToStart) => {
const findLastSilence = (timestamp) =>
silencesWithBothEnds
.filter(({silenceStart}) => silenceStart <= timestamp)
.toSorted((a, b) => a.silenceStart - b.silenceStart)
.toReversed()
[0];
const findFirstSilence = (timestamp) =>
silencesWithBothEnds
.filter(({silenceEnd}) => silenceEnd >= timestamp)
.toSorted((a, b) => a.silenceEnd - b.silenceEnd)
[0];
const lastSilence = findLastSilence(timestamp);
const firstSilence = findFirstSilence(timestamp);
const moveToSilence = (timestamp - lastSilence.silenceEnd > 200 && firstSilence !== undefined) ?
(Math.abs(timestamp - lastSilence.silenceEnd) > Math.abs(timestamp - firstSilence.silenceStart) ? firstSilence : lastSilence) :
lastSilence;
const midpoint = Math.round((moveToSilence.silenceEnd + moveToSilence.silenceStart) / 2);
return alignToStart ? Math.max(moveToSilence.silenceEnd - 500, midpoint) : Math.min(moveToSilence.silenceStart + 500, midpoint);
}
const pointForOffsetFrom = findPoint(offsets.from, true);
const pointForOffsetTo = findPoint(offsets.to, false);
return {from: pointForOffsetFrom, to: pointForOffsetTo};
};Finally, Piper TTS has strict expectations on the audio format, so cut and encode the audio:
export const encodeAudio = addFileCache(async (file, msFrom, msTo, sampleRate) => {
console.log("encodeAudio", file, msFrom, msTo);
return withTempDir(async (dir) => {
try {
await util.promisify(child_process.execFile)("ffmpeg", ["-nostdin", "-i", file, "-f", "wav", "-ac", "1", "-acodec", "pcm_s16le", "-ar", sampleRate, "-ss", `${msFrom}ms`, "-t", `${msTo - msFrom}ms`, "processed.wav"], {cwd: dir});
}catch(e){
console.log(file);
throw e;
}
return await fs.readFile(`${dir}/processed.wav`);
});
}, {calcCacheKey: (file, msFrom, msTo, sampleRate) => ["encodeAudio_1", file, msFrom, msTo, sampleRate]});Now it's just a little bit of plumbing to save everything in the expected format:
const outputDir = path.join(__dirname, "dataset_dir");
await fs.rm(outputDir, {recursive: true, force: true});
await fs.mkdir(outputDir);
const wavs = path.join(outputDir, "wavs");
await fs.mkdir(wavs);
const writtenWavs = await Promise.all(encodedTexts.map(async ({audio, text}, i) => {
const fileName = `${i}.wav`;
await fs.writeFile(path.join(wavs, fileName), audio);
return {text, fileName};
}));
await fs.writeFile(path.join(outputDir, "metadata.csv"), writtenWavs.map(({text, fileName}) => `wavs/${fileName}|${text}`).join("\n"));Result:
$ ls
metadata.csv wavs
$ ls wavs/
0.wav 10.wav 12.wav 14.wav 16.wav 18.wav 2.wav 21.wav 23.wav 25.wav 4.wav 6.wav 8.wav
1.wav 11.wav 13.wav 15.wav 17.wav 19.wav 20.wav 22.wav 24.wav 3.wav 5.wav 7.wav 9.wav$ cat metadata.csv
wavs/0.wav|Before we dive into the technical details of how async functions work, let's start with some background.
wavs/1.wav|Despite their similar name, there are many differences between the two languages.
wavs/2.wav|So let's start with the question.
wavs/3.wav|Let's see a simple example, waiting one second.
wavs/4.wav|This yields a structure that is easier to understand.
wavs/5.wav|There is one fundamental difference between the two languages that affects all asynchronous code.
wavs/6.wav|JavaScript is single threaded.
wavs/7.wav|There is no UI freeze and no application not responding errors when things are running in a separate thread.
wavs/8.wav|So, how single threading affects programming?
wavs/9.wav|There is no synchronous waiting, so anything that is long running needs to use a callback.
wavs/10.wav|And long running might not be that long.
...Overall, this produced 921 sentences (about half of all the sentences in the audio) and about 1.5 hours of recording. That seems like a good start, so on to training: