
Avoid excessive costs and save money with S3 storage classes
How to configure S3-IA and Intelligent-Tiering to reduce costs


Storage classes in S3
Every object in S3 has a storage class that identifies the way AWS stores it. It affects durability, availability, access patterns, and of course, cost.
Back then S3 standard was the only one available later joined by Glacier as a separate service. Then it got merged into S3 and additional classes were added. Now there are options for one-zone storage for recreateable data, IA for infrequently accessed objects, and Glacier is split into two.
Storage classes compromise on an aspect in order to save money. The standard class offers the best durability, availability, and retrieval capacity. If you can live with something worse, you'll pay less.
For example, if you don't need instant access then Glacier saves a lot on storage. If you can handle lost objects then the one-zone classes are cheaper than standard but using them increase the risk that something disappears. And infrequent access (IA) offers greater retrieval but lower storage costs.
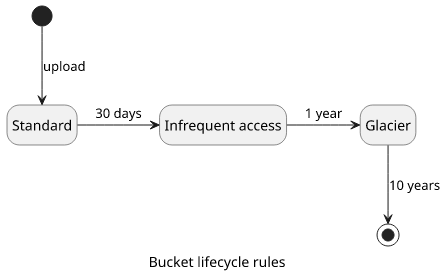
To make things more interesting, there are lifecycle rules to automatically move objects between storage classes. A common use-case is to move objects to classes with lower storage costs as they age and eventually delete them.
But storage class pricing is, let's say, complicated. It's not just some value is lower in the pricing table and some are higher, but there are other intricacies that greatly affect the total cost. These are minimum billable object sizes, minimum storage times, and retrieval costs. And it's not exactly trivial to see the best option for a given use-case.
To make things worse, if you don't take these into account you might end up paying a lot more than the standard price.
In this guide, you'll see how to avoid the pitfalls with the S3-IA storage class.

S3-IA
S3 IA (Infrequent Access) has a simple offer on the tin: for higher retrieval costs it offers cheaper storage. It is logical to use this for infrequently accessed objects and it will cost less in this case.
Let's see the numbers!
In us-east-1, which is usually the cheapest region, these are the current prices (May 2020):
| Storage (/GB/month) | Retrieval (/GB) | |
|---|---|---|
| Standard | 2.3¢ | 0 |
| IA | 1.25¢ | 1¢ |
This is a significant price reduction on storage, but there is a retrieval fee.
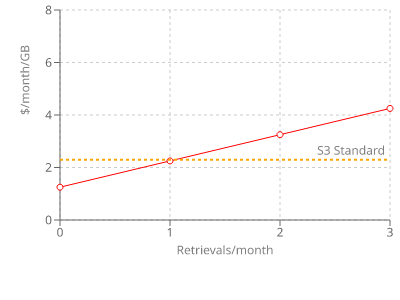
The bottom line: you get the storage almost at half price, but if you read the data once per month then you'll lose all the savings. "Infrequently" means less than once per month. My first thought was to store images that are served via CloudFront and set up caching but I had to realize this storage class is not for this use-case.
There is another difference, but it's hidden in the documentation. If you look at the availability row, you'll see that the SLA is lower: 99.9% vs 99%. This does not sound bad, but that means a difference of ~9 hours vs more than 3 days of downtime every year.
Moreover, there is an asterisk on the pricing page which always means complications. And this is not an exception.
There is a minimum billable object size of 128KB. Every object that is smaller than this will be rounded up to this size. In effect, if the object is 70KB or less it will cost more to store it even if you don't access it even once!
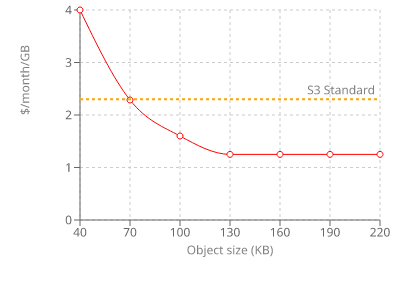
There is also a minimum billable storage time of 30 days. If you delete an object before 30 days you'll still pay for the full period.
Because of the combination of retrieval cost, minimum object size and minimum storage time, using this storage class can cost a lot more than standard. Notice that there is no upper limit on these extra expenses.
Don't upload objects to IA unless you are certain it's the right thing to do in your use-case.
Intelligent-Tiering
Because of the pitfalls of the IA storage class, there is a separate one that aims to fix its shortcomings by making sure only infrequently accessed objects are using that. After all, this is the main problem with the IA class: if something goes wrong even a few accidental reads nullify the saving accumulated for years.
Meet Intelligent-Tiering. It has 2 tiers internally, one for frequently accessed objects and one for infrequently accessed ones. If an object is not read in the first tier for 30 days it will be moved to the second. And it will be moved back once it is accessed which makes sure repeated reads don't incur an additional fee.
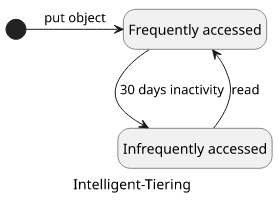
The net effect is that you won't pay more if an object is accessed frequently but still benefit from the reduced storage costs for other ones. It avoids the worst case scenario of IA.
For a price, of course, in this case 0.25¢ / 1000 objects. This makes it sensitive to the average object size, as for small objects this extra fee is more pronounced. As a rule of thumb, if the object is less than 250 KB in size it costs more to use Intelligent-Tiering than the standard class.
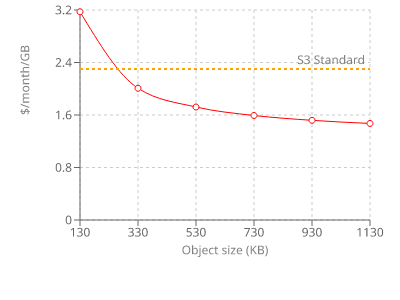
But the 128KB restriction still applies here, but not that objects will be billed for more size than they are but those smaller than this threshold will never be moved to the infrequently accessed tier. Effectively, you'll still pay the monitoring cost but without any benefits.
Moreover, the 30 days minimum rule is also applied here, so make sure things won't usually be deleted before a month.
Intelligent-Tiering helps avoid the main pitfalls of the IA storage class, but it still has problems. If the average object size is small then the extra cost outweights the benefits. And the age restriction makes it potentially more expensive.
Lifecycle rules
As Intelligent-Tiering helps with some problems of IA, Bucket lifecycle rules help with shortcomings of the Intelligent-Tiering.
S3 can move objects from one storage class to another based on a set of rules defined for the bucket but are evaluated for individual objects. This is great as you can set it and then forget about it and will do its thing, moving objects where they need to be.
The rules can filter objects by prefixes, tags and age and set a target storage class.
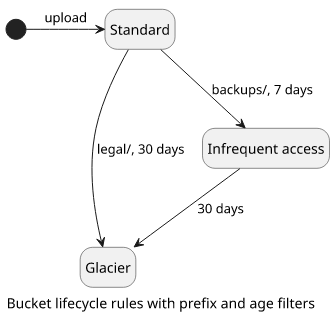
Prefixes can be used to apply to only some directory and not all objects. Maybe you have different types of objects in a single bucket, prefix filters help to differentiate them.
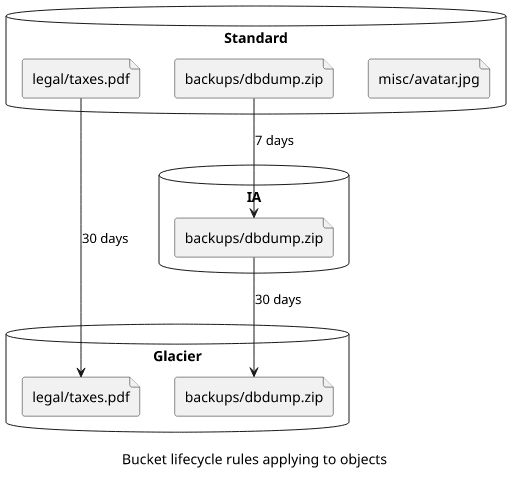
But there are additional constraints that apply that are not readily apparent from the lifecycle rule but implicit to the target storage class.
For example, objects won't move into IA or Intelligent-Tiering if they are less than 128KB or younger than 30 days. These are implicit restrictions and can not be overriden.
How to configure lifecycle rules for Intelligent-Tiering
By combining Intelligent-Tiering and lifecycle rules we can engineer a solution that moves only the objects to the storage class that actually benefit from it. With a simple rule, almost all benefits can be retained without most of the pitfalls described above.
A lifecycle rule that moves objects to Intelligent-Tiering after 30 days will do the following for different kinds of objects:
- deleted before 30 days => stays in standard
- <128KB => stays in standard
- accessed >= 1/month => stays in the frequently accessed tier
- everything else => moves to the infrequently accessed tier
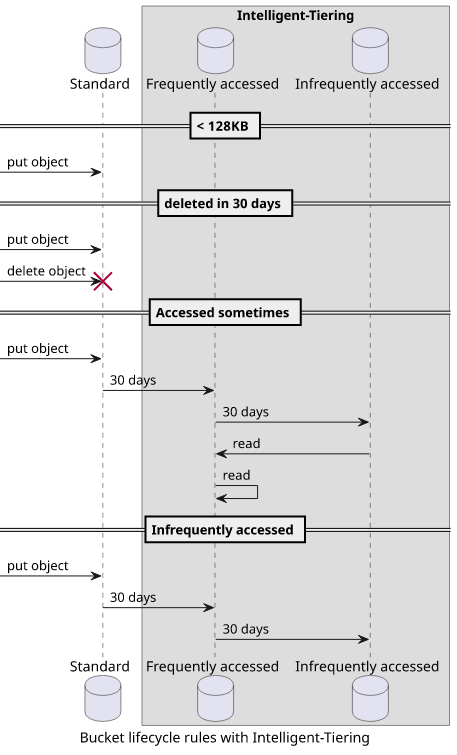
This makes sure that in no event an object costs more than the standard class and the compromise is only the reduced availability SLA for objects moved to the Intelligent-Tiering.
Well, almost. If the average object age before deletion is 31 days then it will still cost more. But that is not a realistic scenario. A more probable problem is when the object size is between 128K and 250K, in which case the lifecycle rule moves it to the Intelligent-Tiering class but the per object monitoring cost will be larger than the savings on storage. Unfortunately, there is no easy solution to this problem. The best is to use tag filters in the bucket lifecycle and put that tag only on larger objects. But that requires handling on the object instead of on the bucket level.
Configure Bucket lifecycle
To configure it on the Console:
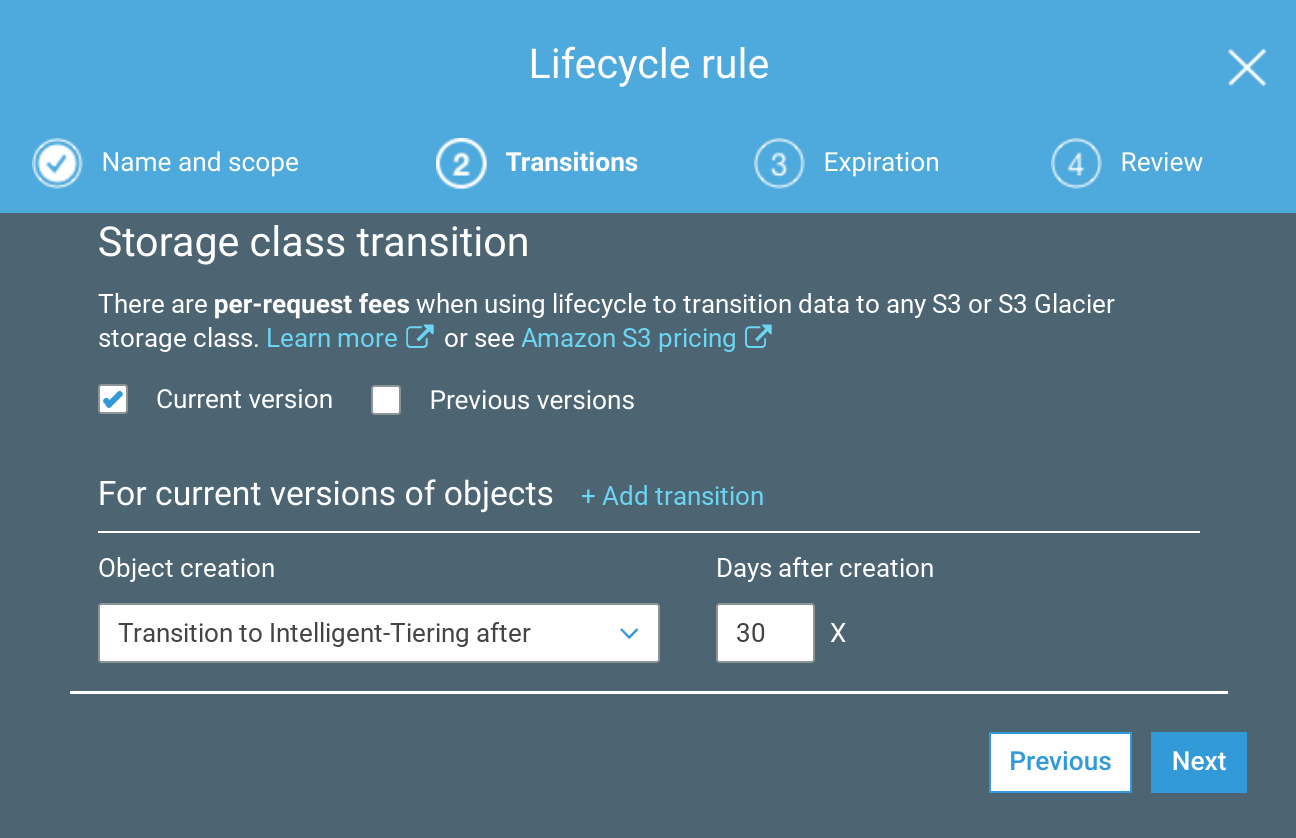
The XML for the same config:
<LifecycleConfiguration>
<Rule>
<ID>id</ID>
<Filter>
<Prefix></Prefix>
</Filter>
<Status>Enabled</Status>
<Transition>
<Days>30</Days>
<StorageClass>INTELLIGENT_TIERING</StorageClass>
</Transition>
</Rule>
</LifecycleConfiguration>And finally with Terraform:
resource "aws_s3_bucket" "bucket" {
# ...
lifecycle_rule {
enabled = true
transition {
days = 30
storage_class = "INTELLIGENT_TIERING"
}
}
}Recommendations
Don't upload objects to the IA or Intelligent-Tiering storage classes directly as they have lower limits for age and size which can bump up the costs significantly. Especially don't use IA as a single read per month will nullify the lower storage costs and multiple reads will cost a lot more.
Use the standard storage class for new objects and configure a lifecycle rule that moves objects to Intelligent-Tiering. This setup takes care of the costly edge cases while still reduces the cost when possible.

