A first look into AWS's new Aurora DSQL database
Will this be a new standard database offered by AWS? Could be, but there are some rough edges


AWS recently announced the Aurora DSQL database that should fit into the space between the full-blown RDS and the way more restricted DynamoDB. It's still early days as it is currently in preview but there are quite a lot of information out there how to use it.
In this article I'll gather my thought on it, concentrating in 2 main topics:
- From an architect's point of view: how it fits into the general ecosystem
- From a developer's point of view: how easy it is to use DSQL in an application

As an architect
Let's first see how DSQL fits into the general ecosystem and what the pain points could be!
Running the database
As far as I can see from the presentations and the documentation, it seems that DSQL supports all the features that makes it easy to operate. According to AWS, it is a truly serverless database, which usually means there are not many knobs to turn there.
That hopefully means it can scale back to zero (as all serverless services should, looking at you Kinesis Data Streams) and also that going from zero to one is fast enough that it's not a problem.
DSQL is a regional service, meaning you don't need to worry about AZs and how to fail over when one fails. Also, one of its main selling point is active-active multi-region setup, making it possible to keep running even if a region goes down.
Availability is, according to the FAQ is 99.99% (1 hour per year) for single-region and 99.999% (5 minutes per year) for multi-region deployments.
Since it's in preview there is no pricing information. That could change the calculations a lot, but so far it looks like DSQL is going to be a database that you set up once and then forget about it.
Integrating
The bad news is that it's connection-based just like most SQL databases are. This means the application needs to establish a connection and then send the queries over that. Example code from the documentation:
const client = new Client({
user: "admin",
database: "postgres",
host: endpoint,
password: token,
ssl: {
rejectUnauthorized: false
},
});
await client.connect();
try {
await client.query("BEGIN; SELECT txid_current_if_assigned(); COMMIT;");
return 200;
} catch (err) {
console.error(err);
return 500;
} finally {
await client.end();
}Side note: what's that rejectUnauthorized: false doing in the official documentation?
Connection-based databases work well with a small amount of (mostly) fixed servers as the setup can be done once and then the queries are fast.
But guess what can't keep an active connection? Lambda.
This is a recurring theme in AWS with SQL databases. Aurora supports the Data API that provides a request-based interface (though with large gaps regional availability) to make it possible for Lambda to use it but it suffers a significant performance drop by going from single to triple digits latency. The alternative is the RDS Proxy that manages these connections which looks awesome until you take a look at its pricing page.
So it's a bummer that DSQL supports only connection-based queries and I really hope that there will be an update to open the way to use it with Lambda.
But, of course, Lambda can open a connection, send the queries, then close it when finished. The number of connections that can be open is not bad: 1000 by default should be enough for most apps. We'll see when it goes to GA, but according to this article it is slow:
Increasing Lambda timeout to 10 seconds from default 3 seconds
As an application developer
OK, I have a database up and running, what I need to know to write my application to use it?
My main entry point for this topic is Marc Brooker's re:Invent presentation (whose blog is also in my RSS feed and I can wholeheartedly recommend it).
The good news is that it's Postgres compatible, meaning most of the existing tools work with it. The bad news is that the compatibility is not complete, for example foreign keys are not supported.
DSQL uses optimistic concurrency control which means that during COMMIT the database checks if rows that were changed were written by another transaction
and abort if that's the case. This means a COMMIT can fail and the whole transaction should be retried.
Isolation
Marc talks about isolation from 41:08.

In this talk, "strong" means there is no eventual consistency. The more interesting part it "snapshot isolation". Well, it's been some time since I last worked with SQL, so I had to look up what are the tradeoffs here.
Aside: Why isolation is important
Probably the best explanation for why care about isolation is this presentation, from 3:44:
... the importance of serializability, to me, is fundamentally the fact that it gives you this preservation of integrity constraints even when the database does not know about the integrity constraints.
It is easy enough to have a database that will maintain a declared integrity constraint but if there's an integrity constraint which is complicated to express, the nice thing about serializability is that that integrity constraint will be maintained even without the platform knowing about it, provided you write each program to be sensible on its own so it turns a global program into a local problem at each program.
With serializable isolation, correctness depends on each transaction independently. If every transaction brings the database from a consistent state to a consistent state (and the initial state is consistent) then the database will be consistent all the time.
But in practice it's hardly used, mostly for performance reasons. Here's what you get out-of-the-box with different databases:
| Database | Default isolation level |
|---|---|
| Postgres | read committed |
| MySQL | repeatable read |
| Oracle | read committed |
| MSSQL | read committed |
Write skew
So, DSQL's snapshot isolation level is clearly an improvement over most other databases. But it's still lower than serializable, which means it suffers from anomalies. In this case, what can go wrong is called write skew.
When a transaction starts, it gets a consistent view of the database (a "snapshot") and it can read data without worrying about other transactions. During COMMIT if there were writes to an item that the transaction also wrote then there will be an exception. This part is called "optimistic concurrency control" as it does not use locks but rather "hopes" that these conflicts will be rare.
This means if a transaction reads some data, makes a decision to do some writes, then it won't fail even if another transaction changed the data that the decision was based on.
Examples of write skew
A simple example (taken from this presentation) is that there are 2 doctors, both on-call. The invariant that the system wants to enforce is that at least one doctor must be on-call all the time.
So a transaction that moves a doctor from on-call to reserve first reads the number of doctors and only proceed with the write if it sees another one is still on-call:
const doctors = await query("SELECT * FROM doctors WHERE status = 'on-call'");
if (doctors.length >= 2) {
await query("UPDATE doctors SET status = 'reserve' WHERE id = 'doctor1'");
}This transaction is wrong under snapshot isolation. If two transactions want to put a different doctor to reserve concurrently then both will be successful, violating the invariant.
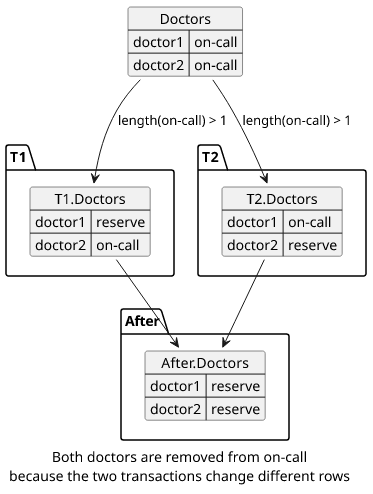
This is because only the writes conflict and the two transactions change different items. This can't happen under serializable isolation level as neither T1->T2 nor T2->T1 would end up at this state.
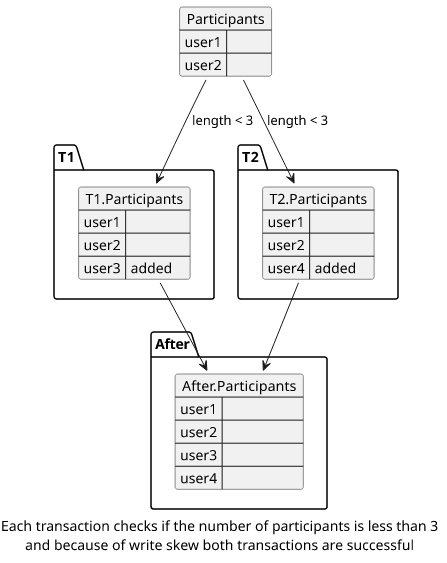
Another example is when there is an invariant that at most 3 people can join a course but due to write skew more is able to join, as described in this answer.
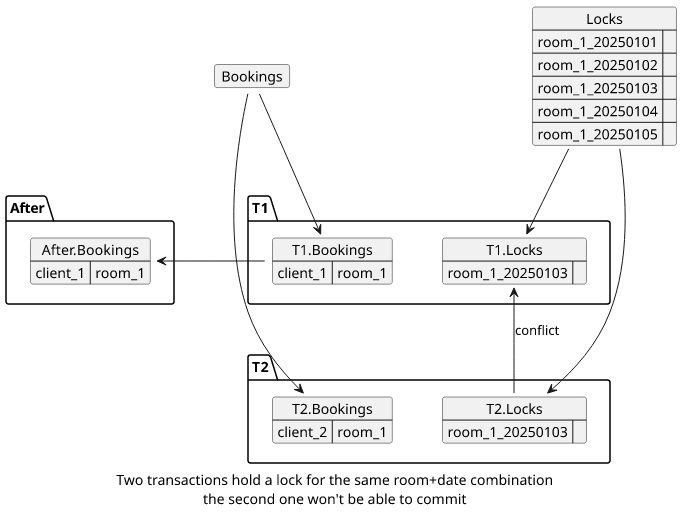
And a third example, as described here is when a meeting room can be booked by multiple clients even when all transactions check if the room is free:
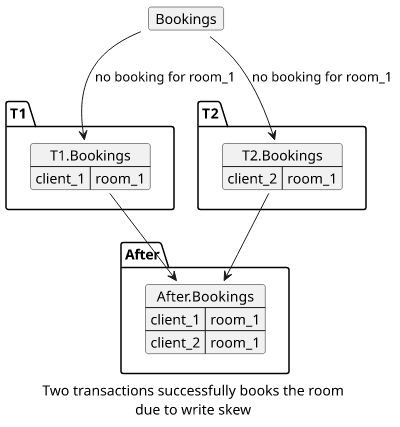
How to deal with write skews
The root cause of the problem is transactions write different data, so a solution is to add rows that both transactions touch. This forces a conflict so that one of the transactions won't be able to commit and has to retry.
One way is to use SELECT FOR UPDATE when reading the rows. When two transactions both use it for the same rows the later one to commit won't be able to
do. The problem here is that it's usually coarse-grained, meaning that it will cause a conflict in too many times.
Another way is called "materialized conflicts". For example, a separate table can hold items for all rooms for each day and a transaction can use SELECT FOR UPDATE for the rows it wants to book the room.