
3 genius visual data extraction attacks in Javascript
How to extract information regardless of the Same Origin Policy


What a page can show but can't see
Have you noticed that you can't set the height of visited links? A CSS rule that targets these links can set a few attributes but not all.
Notice how both links have the same height, even though the bottom one should be taller:
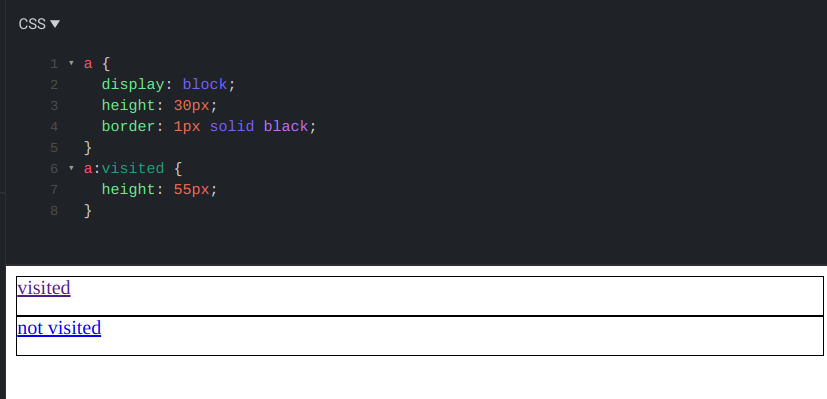
Querying the final style also shows the unvisited height:
getComputedStyle(visitedLink).height; // 30pxYou can set a few properties of visited links, such as the text color:
a:visited {
color: red;
}But even if it looks different Javascript can only see the unvisited styling:
getComputedStyle(visitedLink).color; // rgb(0, 0, 238) (blue)This is one example where a page can show something but it can not see it. A link can be styled differently depending on its visitedness attribute, but the browser guards this information from the page.

Protected visual information
A more everyday example is cross-origin images. They can be shown on a page but the browser puts all sorts of restrictions around them.
I've seen people puzzled why the web works this way, especially when coming from other languages. When you want to show an image in Java or C++ the program needs to access the bytes of the image to show it. Without complete access, they can not display it.
But Javascript and the web work differently. In HTML a simple <img src="..."> shows the image without having access to the bytes first. And this opens a
window to having separate permissions for showing things and to have access to things.
Whether a link is visited or not is a great example of this. It dates back to the earliest browsers, and it's still well-supported. It allows the user to see which links point to pages that were opened before. It's a great feature when browsing Wikipedia, for example, as you can immediately distinguish links that potentially contain new information.
But while it's great for UX, it opens a gaping security hole that is hard to close. If a webpage can tell if a link is visited or not, it can access information that is not meant to be available. For example, it can check Google search URLs and that discloses whether the user searched for specific terms. These can include sensitive information and by composing a large number of these searches a webpage can deanonymize the user.
Security problems can arise from other elements and not just links if they leak information to the site, like loading an image from a different domain can contain sensitive information. For example, a dynamic image can change depending on how many unread notifications you have:

It works as the browser sends the cookies along with the image request that contains the session information that identifies the user to Facebook. If a site
could read the response image, it could extract information about the user's Facebook activity. That's the reason why you can't export the contents of a
canvas after drawing a cross-origin image on it (it's called a tainted canvas).
And the elephant in the room is, of course, IFrames. When not explicitly denied via an X-Frame-Options or a Content Security Policy, a page can be
included in another page, with all login information and such. If a webpage could access any page it includes it would give it free rein over the data
displayed.
Visual attacks
Browsers go to great lengths to protect information that is meant to be seen by the user but not to the webpage. But sometimes they fail in various ways and due to some bugs or clever use of what's available attacks slip through. Let's see some of the most interesting ones!
#1: Visited links
The first one is related to the visited links described above. Not surprisingly, browsers implement measures to block information extraction. It is even acknowledged in the CSS 2.1 specification:
UAs may therefore treat all links as unvisited links, or implement other measures to preserve the user's privacy while rendering visited and unvisited links differently.
This means browsers limit the type of styling a visited link can have on top of non-visited links. For example, by not allowing setting the height of the
element, the webpage can not inspect the position of an element below the link to see if it points to a visited URL.
But with new capabilities, vulnerabilities resurface time and time again. With the getComputedStyle call, Javascript can read the effective style of an
element. And before it was fixed, a site could read the color of the link to see if it was visited or not. It was discovered in
2006 only to resurface ten years
later.
#2: CSS blend modes
This is a brilliant attack to extract visual information from an IFrame or other protected resource pixel-by-pixel. The blog post from Ruslan Habalov does an excellent job of explaining the attack in detail.
The gist of the vulnerability is how blend modes were implemented.
Blend modes allow the page to define how elements that are on top of each other interact. This image shows a few examples:

(Image from https://webdesign.tutsplus.com/tutorials/blending-modes-in-css-color-theory-and-practical-application--cms-25201)
Notice how the middle area changes depending on the blend mode type and the 2 layers' pixel colors.
While a page can not access what an IFrame (or a cross-origin image, or a visited link) looks like, but it can position it on the page freely, even below other elements. That allows blend modes to show differently colored pixels depending on how the elements look like.
But it should not result in any vulnerability since the page can not access the resulting colors of the pixels, it can only define how the browser renders them. At least, not directly.
The code for the blend mode calculation in the browser was implemented to use different branches for different input colors.
// example pseudocode from https://www.evonide.com/side-channel-attacking-browsers-through-css3-features/
[...]
SetSat(C, s)
if(Cmax > Cmin)
Cmid = (((Cmid - Cmin) x s) / (Cmax - Cmin))
Cmax = s
else
Cmid = Cmax = 0
Cmin = 0
return C;
// Compute the saturation blend mode.
Saturation(Cb, Cs) = SetLum(SetSat(Cs, Sat(Cb)), Lum(Cb))And since the page can control one part of the input pixels, it can then try a lot of variations and see the differences in timing. And that leaks information about the other part of the input pixels, namely the protected content.
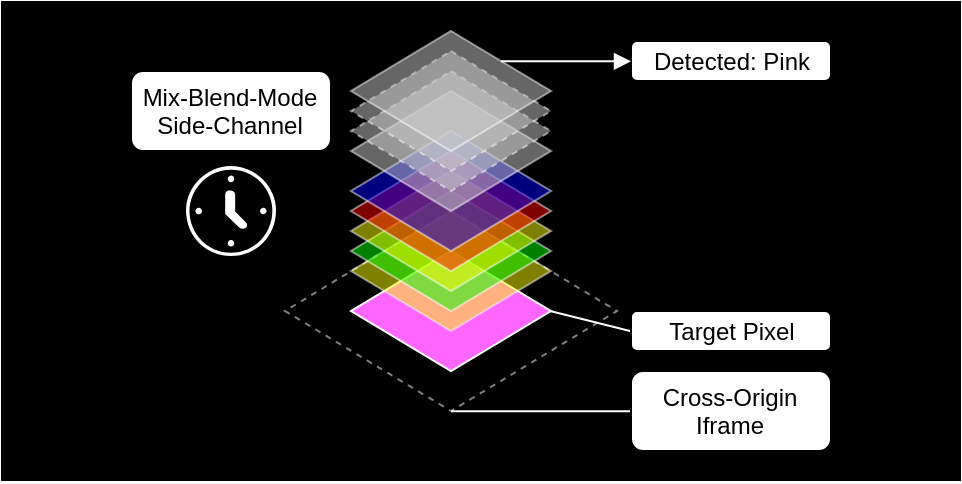
(Image from https://www.evonide.com/side-channel-attacking-browsers-through-css3-features/)
This allows data extraction, one pixel at a time and it circumvents all browser protections against cross-origin access. This vulnerability was patched by eliminating branches from the blend mode implementation, making the algorithm run in constant time regardless of the input colors.
#3: Evil CAPTCHA
This attack utilizes the weakest point in every IT security system: the user. This is a genius way to extract information from a different website as the user actively participates in the attack. And no web standard can protect against that.
A CAPTCHA is a way to protect a website (or part of it) from bots. It is a challenge that should be easy for humans but hard for machines, like reading characters from an image. This is used to prevent automated spamming the comments section or the contact form. It looks like this:
(Image from https://en.wikipedia.org/wiki/File:Captchacat.png)
Nethanel Gelernter and Amir Herzberg show in their paper a way to utilize the user's familiarity with solving CAPTCHAs to extract information. In their implementation, they loaded data in a slightly obscured way and asked the user to type it in a textbox.
For example, the cache manifest for Gmail contained the user's email address:
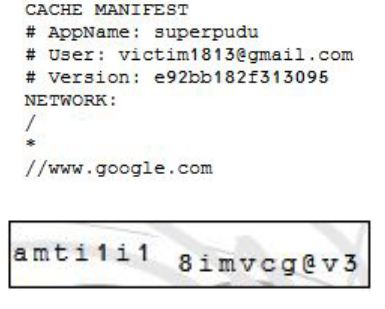
(Image from the paper)
Notice that the CAPTCHA is just a rearranged version of the first 15 characters of the email address (victim1813@gmai). It looks like an innocent normal CAPTCHA, but it gives this information to the website.
You can no longer extract the gmail address of the user from a cache manifest file. But you can still embed a Facebook comment box on any website and that still contains the real name of the user:
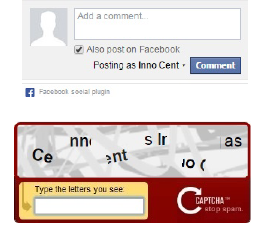
(Image from the paper)
Notice that the text contains the name "Inno Cent" in full. By typing it, the user inadvertently exposes their real name if they are signed in on Facebook.
This attack also opens the door for all sorts of other information extraction. The authors of the paper exploited Bing's personalized autocomplete feature that exposed search history. The image on the left shows the template with 4 areas to extract information. The image on the right shows how the "final" CAPTCHA looks like, in this case indicating that all 4 terms were searched:

(Image from the paper)
This example exploited a privacy bug in Bing, but it's not hard to imagine how it could also enable checking if a link was visited or not: just style the non-visited link to match the background. If the user can see it (and type it in the textbox) then the link was visited.
The beauty of this attack is that it's near impossible to implement a technical solution to prevent it. Fortunately, its applicability is limited, as it can only extract textual information and only a few times before the user becomes bored and leaves the site.


{kind=link}